

大型AI模型(LAIMs),尤其是扩散模型和大型语言模型的迅速发展,标志着一个新时代的到来,其中AI生成的多媒体内容越来越多地融入到日常生活的各个方面。尽管在许多领域都具有益处,但这种内容也带来了重大风险,包括潜在的滥用、社会干扰和伦理关切。因此,检测LAIM生成的多媒体内容变得至关重要,相关研究也大幅增加。尽管如此,仍然存在一个明显的系统调查领域的空白,专门关注检测LAIM生成的多媒体内容。为了解决这一问题,我们提供了第一个全面涵盖现有研究的调查,重点关注检测LAIM生成的多媒体内容(如文本、图像、视频、音频和多模态内容)。具体而言,我们引入了一种新颖的检测方法分类法,按媒体模态进行分类,并与两个视角相一致:纯检测(旨在提高检测性能)和超越检测(为检测器添加可泛化性、鲁棒性和可解释性等属性)。此外,我们还简要介绍了生成机制、公共数据集和在线检测工具,为该领域的研究人员和实践者提供了宝贵的资源。此外,我们还识别了检测中的当前挑战,并提出了未开发、正在进行和新兴问题的未来研究方向。我们的目标是填补学术空白,为全球AI安全工作做出贡献,帮助确保数字领域信息的完整性。项目链接为https://github.com/Purdue-M2/Detect-LAIM-generated-Multimedia-Survey。

大型AI模型(LAIMs)以其异常高的参数数量而闻名,通常达到数十亿,正如[1]–[3]的工作所强调的那样。这些模型通常包括扩散模型(DMs)和大型语言模型(LLMs),它们都在广泛的数据集上进行训练,需要大量的计算资源。特别值得注意的是,LAIMs,尤其是DMs,与传统的AI模型(如生成对抗网络(GANs)和变分自编码器(VAEs))相比,具有可扩展性和生成质量的优势。具体而言,LAIMs在处理复杂任务(如语言理解、模式识别以及生成高度逼真的多媒体内容,包括文本、图像、视频和音频)方面表现出色。正如[2]所记录的,自2020年以来,这些模型吸引了相当大的兴趣,因为它们在各个领域(包括自然语言处理[1]、计算机视觉[4]和健康信息学[3]等)中持续提高了性能和多功能性。
LAIMs的最新进展为人类在生活和工作的各个方面提供了许多好处。具体而言,LAIM生成的多媒体内容的好处涵盖了教育[5]、医疗保健[6]、创意增强、业务流程优化[7]和提高可访问性[8]等广泛领域。这些进步提高了任务效率,并为创新和问题解决开辟了新的途径。
与此同时,LAIMs生成的多媒体内容也带来了滥用和社会动荡的重大风险,如[9]、[10]所讨论的。具体而言,这些模型可以用于制作令人信服的虚假新闻、Deepfake(使用AI算法创建的高度逼真的虚假图像、音频和视频[11])以及其他形式的错误信息,从而挑战了信息的准确性和公众信任[12]–[14]。例如,LAIM生成的多媒体内容可以被用来进行政治宣传或操纵性广告,利用其创建具有说服力和定制性的内容的能力。此外,还存在关于使用LAIMs制作艺术或模仿人类创造力的内容时的伦理困境,引发了关于原创性、知识产权和人类艺术表达内在价值的辩论[15]。此外,LAIMs生成多媒体内容的能力可能会对创意领域的就业产生影响,引发了关于新闻、艺术和娱乐领域人员被替代的担忧。2023年夏季的大规模罢工,作家和表演者与好莱坞主要制片公司对抗的事件就是一个显著的例子[12]。
这些挑战突显了迫切需要有效的LAIM生成多媒体内容检测方法。近年来,针对这一领域的研究大幅增加。然而,据我们所知,尽管有许多关于使用LAIMs生成多媒体内容的调查,但缺乏系统性的调查专门探讨检测LAIM生成的多媒体内容,这与之形成对比。为填补这一空白,我们提供了这一全面的调查,不仅填补了重要的学术空白,而且与各国政府的AI安全举措(如2023年的AI安全峰会[16]和美国政府的“AI执行令”[17])保持一致。
在本调查中,我们详细审查了现有关于识别LAIM生成的多媒体内容的研究,特别强调了扩散模型和大型语言模型。我们的目标是指导研究人员了解当前的挑战,并探索这一领域的未来研究方向,旨在恢复用户对数字内容的信任。此外,我们努力展示,尽管LAIM生成的多媒体内容具有很高的逼真度,但仍然可以识别,这对于其合法使用和维护数字世界中信息的完整性至关重要。LAIMs使用生成和检测多媒体内容之间的动态和持续相互作用如图1所示。
1)这是第一份全面的关于检测由大型AI模型(LAIMs)生成的多媒体内容的调查,涵盖了文本、图像、视频、音频和多模式内容。通过这个有组织和系统的调查,我们希望推动这一领域的研究取得进展。 2)我们简要介绍了LAIMs、它们的生成机制以及它们生成的内容,揭示了这一领域中“猫(生成)和老鼠(检测)”游戏的当前状态。此外,我们介绍了专为检测任务量身定制的公共数据集。 3)本调查审查了LAIM生成的多媒体内容的最新检测方法。我们创新性地将它们按媒体模式分为两大类:纯检测和超越检测。这个分类法提供了一种以前未曾探索的独特视角。在这两个类别中,我们根据它们的共同和独特特征进一步将方法分类为更具体的子类别。 4)我们对在线检测工具进行了彻底的检查。这为这一领域的研究人员和从业者提供了宝贵的资源。此外,我们指出了最近的检测方法所面临的当前挑战,并提供了未来工作的方向。 本调查的其余部分组织如下:在第2节中,我们简要介绍了LAIMs,包括生成机制和数据集。在第3节中,我们按照功能对检测方法进行分类,并将它们组织到我们新定义的分类法中。我们在第4节总结了在线检测工具。第5节讨论了检测器面临的关键挑战和潜在的未来方向。最后,在第6节中总结了这项调查。 生成
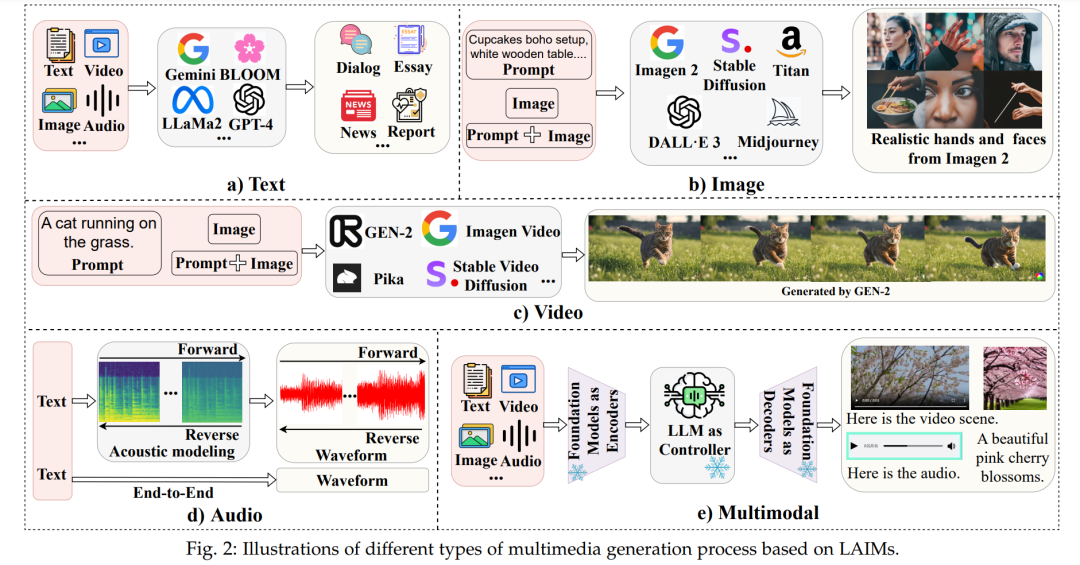
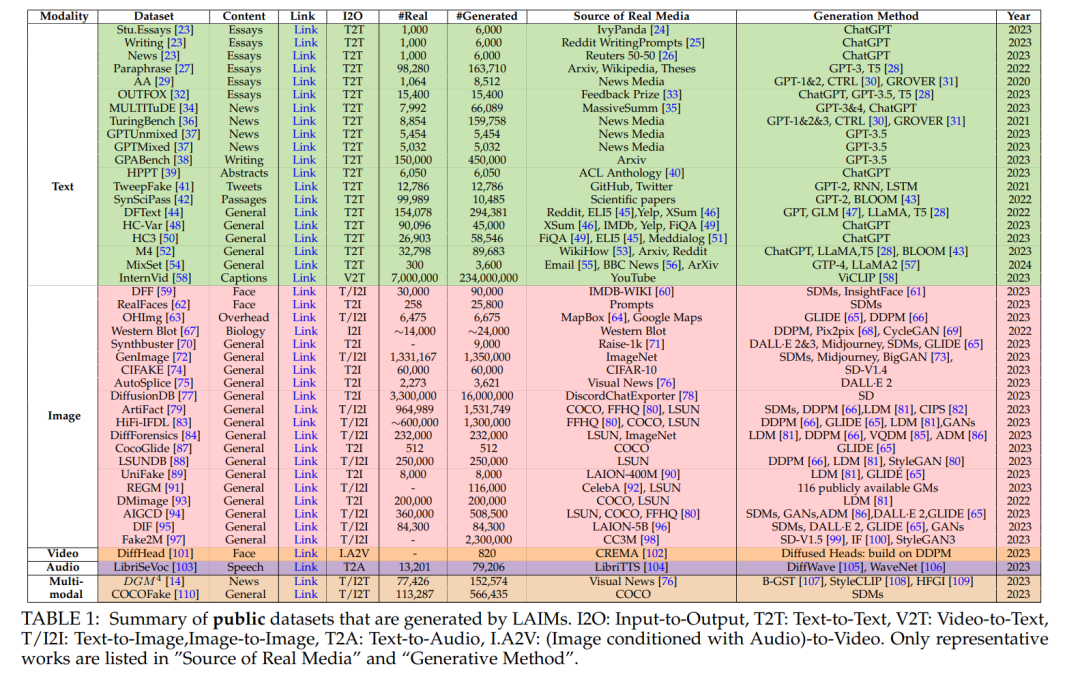
在这个部分,我们提供了大型生成式AI模型、它们的生成机制以及它们生成的内容的概述。 ♣ 文本。机器生成的文本,主要由大型生成式AI模型(LLMs)的出现推动,正在越来越多地渗透到我们日常生活的许多方面。LLMs在理解、追踪和复杂推理方面的卓越能力[111]已经确立了它们在文本创作中的主导地位。最近,我们目睹了LLMs的激增,包括OpenAI GPT4 [112]、Google Gemini [113]、Meta LLaMA2 [57]以及它们在各种任务中取得的显著表现,如新闻 [31],[36]、问题回答 [45]、生物医学 [114]、代码生成 [115]、推特 [41]和科学写作 [42],请参见图2 a)。更多详细信息可以在[1],[116]中找到。 数据集。用于LLM生成文本检测的主要数据集列在表1中。例如,HC3 [50]是最初的开源努力之一,用于比较ChatGPT生成的文本与人类编写的文本。由于它在这一领域的开创性贡献,HC3语料库已经被广泛用作众多后续研究的宝贵资源。此外,作者归属 [29]和TuringBench [36]数据集被提出用于评估检测器的归属能力。HPPT [39]可以用于检测ChatGPT优化文本的任务的基准。
♣ 图像。在图像合成这一具有挑战性的任务中,扩散模型(DMs)[66],[117],[118]已经成为新的深度生成模型家族的最新技术。DMs中的图像生成过程通常包含两个过程[66]:一个前向过程逐步通过添加噪声破坏数据,一个反向过程学习通过去噪生成新数据。更多详细信息可以在[4],[119]中找到。当前的扩散模型研究主要基于三种主要的公式:去噪扩散概率模型(DDPMs)[66],基于得分的生成模型(SGMs)[117]和随机微分方程(得分SDEs)[118]。在它们的基础上,出现了更先进的图像生成模型,包括OpenAI DALL·E 3 [120]、Stable Diffusion V2 [81]、Google Imagen2 [121]、Midjourney [122]、Amazon Titan Image Generator [123]和Meta Emu Edit [124],请参见图2 b)。数据集。存在一些百万级别的生成图像检测数据集:GenImage [72],DiffusionDB [77],ArtiFact [79],HiFi-IFDL [83]和Fake2M [97]。DiffusionDB是第一个大规模的图像-提示对数据集,尽管其中的图像仅由稳定扩散生成。GenImage、ArtiFact、HiFi-IFDL和Fake2M包含由各种DMs和GANs生成的图像。HiFi-IFDL独特之处在于其包含高分辨率伪造掩模,使其特别适用于检测和定位任务。有关更多详细信息,请参见表1。
♣ 视频。在追求高质量视频生成方面,最近的研究也转向了扩散模型。早期的工作 [125],[126]基于DDPM [66]进行视频生成。当前的研究将文本到图像(T2I)扩散模型扩展到文本到视频(T2V)生成。Meta提出了Make-A-Video [127],通过时空分解扩散模型将基于扩散的T2I模型扩展到T2V。更先进的模型Emu Video [128]是他们最新的视频生成里程碑。与Make-A-Video不同,Emu Video只需要五个模型,它是一个简单的统一架构,用于视频生成,并且只使用两个扩散模型。给定文本提示,Google的Imagen Video [129]使用基本视频生成模型和一系列交替的空间和时间视频超分辨率模型生成高分辨率视频。最近,Stability AI的Stable Video Diffusion [130]和Runway的GEN-2 [131]提供了用于视频生成的潜在视频扩散模型,而Pika [132]引入了一个旨在扩展视频创作创意可能性的平台,如图2 c)所示。
数据集。尽管在T2I生成的成功基础上,T2V生成要求具有与文本匹配的时间平滑和逼真的动画,除了高质量的视觉内容,这使得它与图像合成相比仍处于初级阶段。此外,视频生成比图像合成要昂贵得多。据我们所知,只有一项工作[101]通过LAMs贡献了他们生成的说话头视频,详见表1。
♣ 音频。大多数由扩散模型合成的音频侧重于文本到语音(TTS)任务。一种工作线路 [105],[133],[134]首先生成声学特征,如mel频谱图,然后使用声码器输出波形。另一分支的工作 [135],[136]试图以端到端的方式解决TTS任务,如图2 d)所示。Diff-TTS [133]是第一个将DDPM [66]应用于mel频谱图生成的工作。它通过扩散时间步将噪声信号转化为mel频谱图。[105],[134]将扩散模型应用于声码器,以生成基于mel频谱图的波形。与将声学建模和声码器建模视为独立过程不同,[135],[136]从文本生成音频,而不将声学特征作为显式表示。
数据集。由于相对较少的研究关注伪造音频的检测,表1中的LibriSeVoc [103]是迄今为止唯一包含基于扩散模型的声码器(WaveGrad [134]和DiffWave [105])的公共数据集。
♣ 多模态。多模态学习指的是包括学习文本、图像、视频和音频等多种模态的综合学习情境 [137]。从生成的角度来看,视觉生成任务,如文本到图像和文本到视频,被视为多模态生成。用于这些任务的生成模型被训练来学习视觉表示和语言理解,以进行视觉生成。从检测的角度来看,用于伪造检测的能够学习多个模态的检测器被归类为多模态。在这个背景下,我们从检测的角度定义了"多模态生成",指的是具备创建多模态输出能力的框架。多模态生成过程通常包含基础模型作为编码器(例如,CLIP [138]、ViT [139])和解码器(例如,Stable Diffusion [81]),以及一个从编码器中获取语言类似表示的LLM,用于语义理解并生成用于引导内容输出的模态信号令牌,如图2 e)所示。最近的工作,如HuggingGPT [140]、AudioGPT [141]和NExTGPT [142],都是基于LLMs的语言理解和复杂推理能力,利用现有的多模态编码器和解码器作为执行多模态输入和输出的工具。
数据集。表1中的多模态数据集包含多种类型的伪造媒体。例如,DGM4 [14]和COCOFake [110]包括合成的文本和图像。
**检测 **
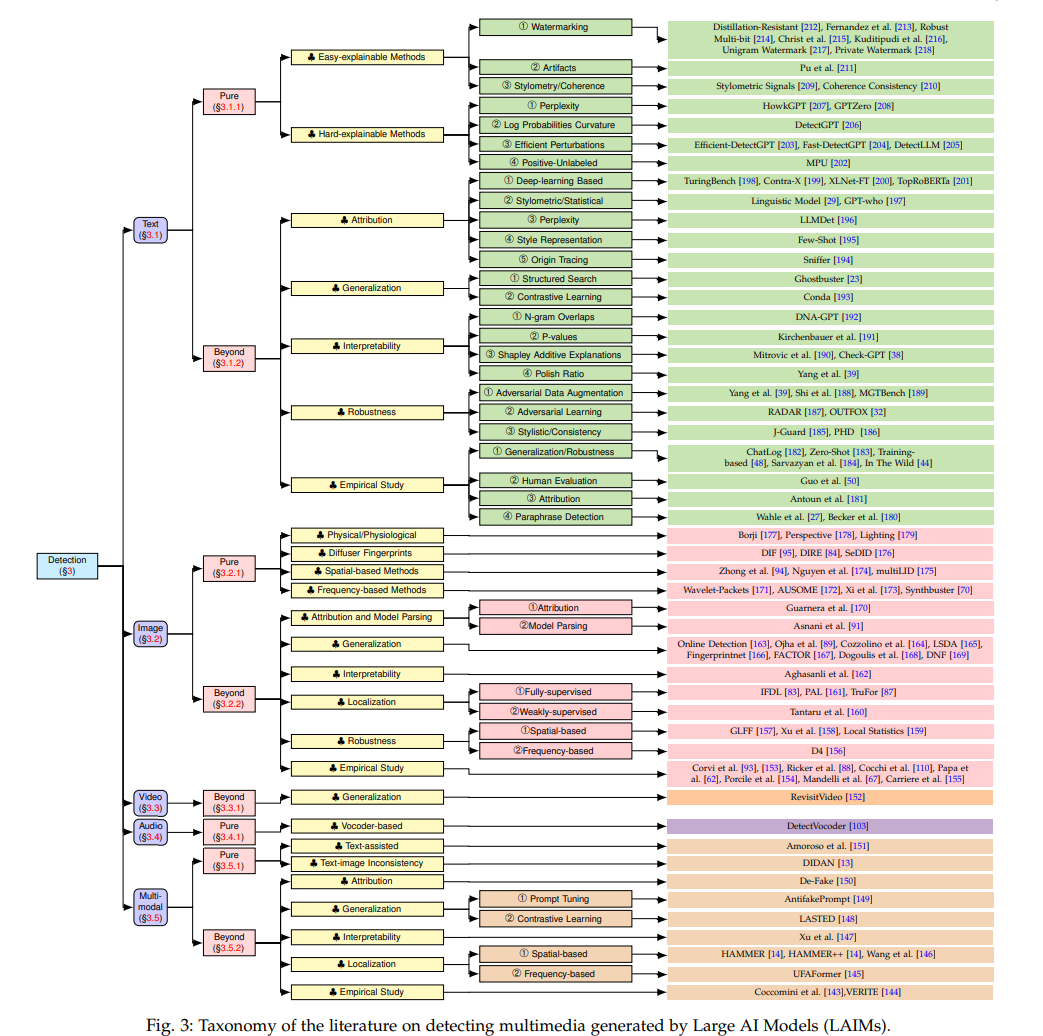
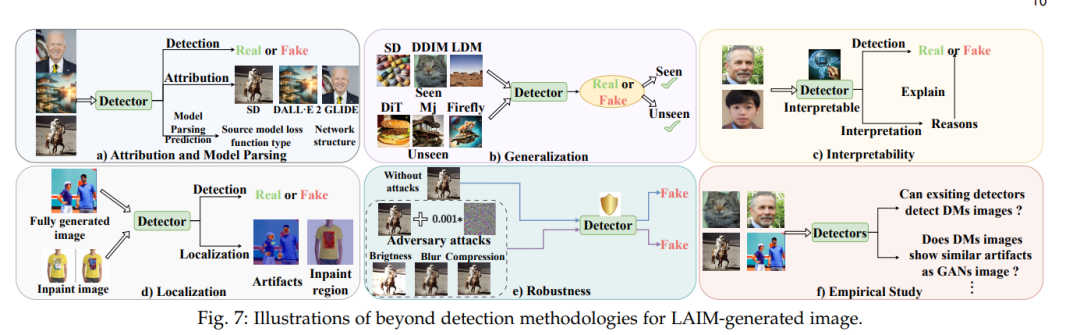
在这一部分中,我们提供了有关LAIM生成多媒体的检测方法的新颖分类。图3提供了本节结构的概述。具体来说,我们确定了这些检测器的功能,并将它们分为每种数据模态两类: 纯检测。这个类别中的检测方法只旨在提高检测性能。
超越检测。它为检测器赋予了额外的特性(例如,通用性、鲁棒性、可解释性),同时保持准确和有效的检测能力。
文本检测
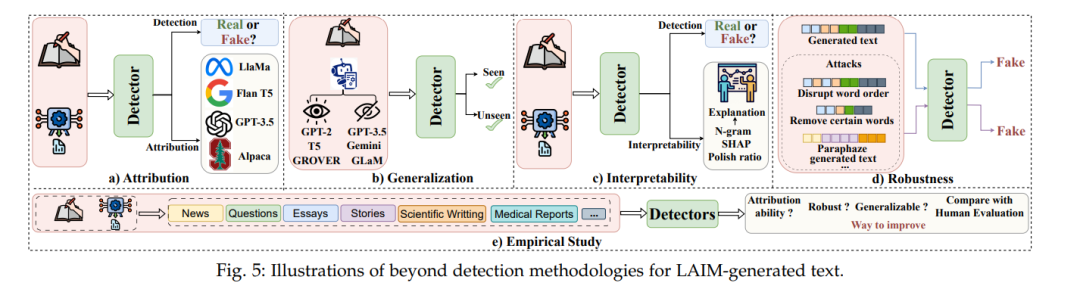
已经存在一些调查提供了关于当前检测策略和基准的详细概述[18]–[20]。具体来说,[18]将检测方法分为三组:基于训练、零样本和水印。每组中的工作根据其检测场景,如黑盒和白盒,进一步区分。[19]中的作者根据检测器应用的技术(例如,对抗性学习、水印方法和人工辅助方法)以及检测器对训练的依赖性(例如,零样本检测器、微调检测器)对LLM生成内容的检测进行分类。[20]将现有的文献分为两部分:设计用于检测LLM生成的文本的方法(例如,基于水印、基于微调和零样本的方法),以及设计用于回避检测的方法(例如,改写攻击、欺骗攻击)。尽管这些组织策略适用于最近的检测方法,但它们的分类法可能不足以适应新的或不断发展的检测技术。因此,我们提供了一种基于“纯检测”和“超越检测”的新颖分类。

图像检测 尽管扩散模型(DMs)发展迅速并生成越来越逼真的图像,但它们仍然经常会犯一些错误并留下可识别的指纹。

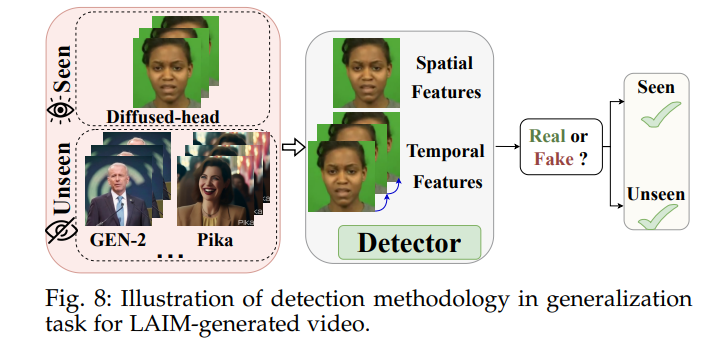
最近,有限的研究集中在检测由LAIMs生成的视频上。这主要是因为视频生成技术比图像生成技术更复杂。此外,正如在第2节中所概述的,与图像生成相比,视频生成技术仍处于初级阶段。据我们所知,与这个领域相关的工作只有一项[152],请参见图8,我们将其分类为“超越检测”类别。
在这里,我们对利用多模态学习的文献进行分类,多模态学习可以在单一或多个模态中使用多种模态来检测伪造。特别是,多模态学习[137]指的是一种包括学习文本、图像、视频和音频等多种数据模态的综合学习情境。

结论
本文提供了第一份系统且全面的调查,涵盖了有关从文本、图像、音频和视频到由大型AI模型生成的多媒体内容的检测研究。我们引入了一种新颖的检测方法分类法,将它们分为两个主要框架:纯检测(重点是提高检测准确性)和超越检测(将通用性、鲁棒性和互操作性等属性整合到检测器中)。此外,我们还概述了贡献于检测的信息源,如LAIMs的生成机制、公共数据集和在线工具。最后,我们指出了该领域当前面临的挑战,并提出了未来研究的潜在方向。我们相信,这份调查是解决该领域一个显著的学术空白的初步贡献,与全球AI安全倡议保持一致,从而维护了数字信息的真实性和完整性。

