

在大型语言模型(LLMs)时代以及人工智能驱动的内容创造被广泛采纳的背景下,信息传播的景观经历了一种范式转变。随着由人类撰写和机器生成的真假新闻的泛滥,鲁棒且有效地辨别新闻文章的真实性已成为一个复杂的挑战。虽然已有大量研究致力于假新闻的检测,但这些研究要么假设所有新闻文章都是人类撰写的,要么粗暴地假设所有机器生成的新闻都是假的。因此,在理解机器(改写)真实新闻、机器生成的假新闻、人类撰写的假新闻和人类撰写的真实新闻之间的相互作用方面存在显著差距。在本论文中,我们通过对各种场景下训练的假新闻检测器进行全面评估来研究这一差距。我们的主要目标围绕以下关键问题展开:如何适应LLMs时代的假新闻检测器?我们的实验揭示了一个有趣的模式:那些仅在人类撰写的文章上训练的检测器确实能够很好地检测机器生成的假新闻,但反之则不然。此外,由于检测器对机器生成文本的偏见(Su et al., 2023a),它们应该在与测试集机器生成新闻比例更低的数据集上进行训练。基于我们的发现,我们为开发鲁棒的假新闻检测器提供了一个实用策略。
自从英国脱欧和2016年美国总统竞选以来,假新闻的泛滥已成为一个主要的社会问题(Martino et al., 2020)。一方面,虚假信息更容易生成但更难以检测(Kumar and Shah, 2018)。另一方面,人类常常被耸人听闻的信息所吸引,并且比真实新闻快六倍地传播它(Vosoughi et al., 2018),这对个人和整个社会都是一种威胁。直到最近,大多数在线虚假信息都是人类撰写的(Vargo et al., 2018),但最近很多都是由人工智能生成的。随着自然语言生成的持续进步(Radford et al., 2019; Brown et al., 2020; Chowdhery et al., 2022),人工智能生成的内容已变得与人类撰写的内容无法区分,并且经常被认为比人类生成的宣传更可信(Kreps et al., 2022)和值得信赖(Zellers et al., 2019; Spitale et al., 2023)。这引起了对人工智能模型所启用的前所未有规模的虚假信息的紧迫关切(Bommasani et al., 2021; Kreps et al., 2022; Buchanan et al., 2021; Goldstein et al., 2023)。虽然抗击机器生成的假新闻的努力可以追溯到早在2019年(Zellers et al., 2019),但这个领域的大多数研究主要集中在检测机器生成的文本上,而不是评估机器生成的新闻文章的事实准确性。在这些研究中,机器生成的文本被视为始终是假新闻,不管其内容如何。
以前,当生成性人工智能不太普遍时,假设大多数自动生成的新闻文章主要被恶意行为者用来制造假新闻是相当合理的。然而,随着过去两年生成性人工智能的显著进步,以及它们在我们生活的各个方面的整合,这些工具现在被广泛用于合法目的,例如协助记者创造内容。例如,有声望的新闻机构使用人工智能来起草或增强他们的文章(Hanley and Durumeric, 2023)。然而,人类撰写的假新闻的古老问题仍然持续。这种机器生成的真实新闻、机器生成的假文章、人类编造的虚构和人类撰写的事实文章的多样化混合,已改变了新闻生成的方式,而内容来源的错综复杂的交织在可预见的未来可能会持续。
为了适应大型语言模型(LLMs)时代,下一代假新闻检测器应能够处理人类/机器生成的真/假新闻的混合内容环境。虽然存在大量关于假新闻检测的研究,但它们通常专注于人类撰写的假新闻(Khattar et al., 2019; Kim et al., 2018; Paschalides et al., 2019; Horne and Adali, 2017; Pérez-Rosas et al., 2018)或机器生成的假新闻(Zellers et al., 2019; Goldstein et al., 2023; Zhou et al., 2023),基本上将问题框定为检测机器生成的文本。然而,健壮的假新闻检测器应主要评估新闻文章的真实性,而不是依赖于其他混杂因素,比如文章是否是机器生成的。因此,迫切需要理解机器转述的真实新闻(MR)、机器生成的假新闻(MF)、人类撰写的假新闻(HF)和人类撰写的真实新闻(HR)上的假新闻检测器。
在这里,我们通过评估训练有机器生成和人类撰写假新闻不同比例的假新闻检测器来弥合这一差距。我们的实验得出以下关键见解: (1)当假新闻检测器仅在人类撰写的新闻文章(即HF、HR)上训练时,它们有能力检测机器生成的假新闻。然而,反之则不然。这一观察表明,当测试数据的比例不确定时,建议仅用人类撰写的真假新闻文章训练检测器。这样的检测器仍然能够有效地概括以检测机器生成的新闻。 (2)尽管整体性能主要由测试数据集中机器生成和人类撰写假新闻的分布决定,但我们实验的类别准确性表明,为了实现所有子类的平衡性能,我们应该在与测试集相比机器生成新闻比例较低的数据集上训练检测器。 (3)我们的实验还揭示,假新闻检测器在检测机器生成的假新闻(MF)方面通常比识别人类撰写的假新闻(HF)更好,即使是专门训练在人类生成的数据上(在训练期间没有看到MF)。这强调了假新闻检测器内在的偏见(Su et al., 2023a)。建议在训练假新闻检测器时考虑这些偏见。
我们的贡献可以总结如下:
• 我们是第一个在新闻文章展示广泛多样性的多种情景下,包括人类撰写和机器生成的真假内容,对假新闻检测器进行全面评估的。 • 基于我们的实验结果,我们提供宝贵的见解和实用指导,以在现实世界的环境中部署假新闻检测器,确保它们在不断发展的新闻生成环境中保持有效。
• 我们的工作为理解由LLMs引起的假新闻中数据分布的变化奠定了基础,超越了简单的假新闻检测。我们旨在提高研究社区对人类语言演变动态及其更广泛影响的认识。
**方法论 **
随着人类撰写和机器生成内容之间的动态变化,评估它们对模型区分真假新闻能力的影响至关重要。在这里,我们考虑了三种不同的实验设置,每种代表了由于LLMs的发展而导致的新闻文章生成的不同阶段,如图1所阐述。 最初的“人类遗产”阶段,象征着新闻主要由人类作者创作的时代。在这个实验设置中,我们仅使用人类撰写的真实新闻文章作为真实新闻类别的训练数据。同时,为了观察机器生成的假新闻在训练数据中的比例如何影响检测器的性能,我们逐步将机器生成的文章引入假新闻类别,比例从0%到100%不等。这种设置反映了过去的时代,当时人类是真实新闻的主要制作者,机器在假新闻文章生成中扮演了微不足道的角色。
转变到“过渡共存”阶段,我们反映了目前的情况,即语言模型共同贡献于真实新闻文章的生成。为了简化这个设置,我们的真实新闻类别训练数据包含了人类撰写和机器生成的部分。这种设置反映了新闻领域正在进行的转变,标志着LLMs影响力的增长。
最后,在“机器主导”阶段,我们模拟了一个可能的未来,即机器生成的文本在真实新闻生成中激增。为此,真实新闻类别的训练数据完全来源于机器生成的真实新闻文章。这一阶段设想了一个场景,即LLMs凭借其先进的能力成为新闻生成的主要和主导来源。
实验结果
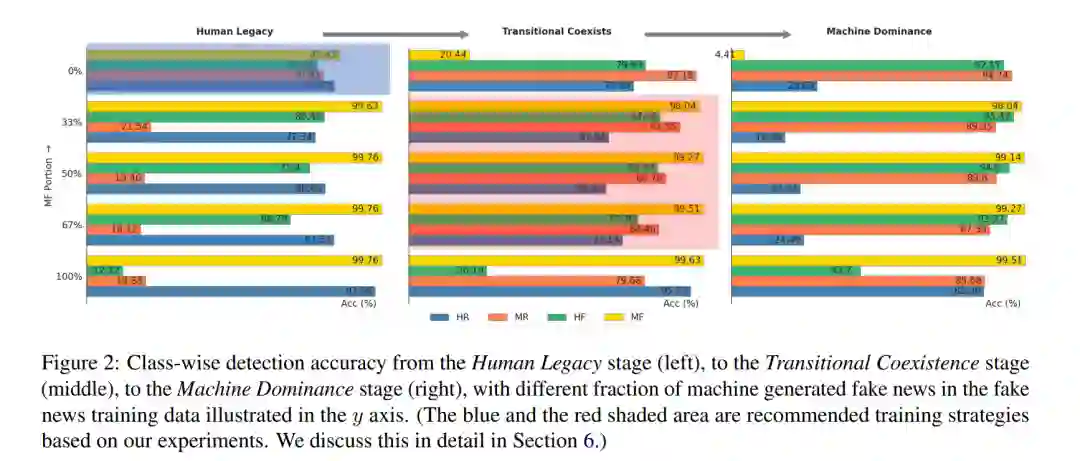
在这一部分中,我们对第三节提到的三个阶段进行了详尽的实验和探索。具体来说,我们评估了五种基于Transformer的模型在这三个阶段的两种不同大小。结合了五种不同比例的机器生成假新闻,共产生了50种独特的模型配置。我们在两个数据集上测试了这些配置:一个领域内数据集GossipCop++和一个领域外数据集PolitiFact++。 (正如我们在附录C中分析的那样,由于与GossipCop++有显著的统计差异,PolitiFact++可以作为评估检测器稳健性的有价值的领域外数据集。) 5.1 主要结果 考虑到实验的大量性,为了保持清晰和避免读者感到压倒性,我们将完整结果放在附录B中,而主要集中在图2的分析和讨论上,该图显示了在GossipCop++数据集上训练大型RoBERTa模型并进行测试所获得的性能度量。 为了提供全面的理解,我们首先独立地深入研究每个阶段,然后对这些阶段的观察模式进行更全面的分析。 人类遗产设定。在这种设置中,真实新闻的训练数据全部是人类撰写的。当与人类撰写的假新闻配对作为整个训练集时,它可以达到相对平衡且高检测准确度的每个子类。当MF部分增加到33%时,MF的检测准确度增加到约99%,并且在训练数据中进一步增加MF子类的比例几乎不再对MF子类的测试检测准确度有更多贡献。此外,我们发现MR子类的检测准确度出现突然下降。这可能是因为,当我们将MF添加到训练数据中时,由于我们在训练期间没有MR数据,检测器可能使用了诸如机器生成文本的独特特征作为“假新闻”的特征,因此可能将大多数MR示例归类为假新闻。同样,当MF示例的比例从67%增加到100%时(即,我们仅使用机器生成的假新闻与仅人类撰写的真实新闻作为训练数据),我们观察到HF准确度的突然下降:这种方式训练的检测器将大多数人类撰写的假新闻归类为真实,因为它检查文本是否是机器生成的作为检测假新闻的关键特征。注意,即使MF部分很高,MR子类的准确度仍然大于1 − Acc(MF),这表明检测器仍然可以学习一些特征来识别机器生成文本的真实性,而不是仅使用机器生成文本的特征。否则,我们将有Acc(MR) ≈ 1 − Acc(MF)。
这个阶段的一个关键观察是,当MF的比例为0%,即我们在人类撰写的真假新闻文章上训练检测器,然后部署它来检测机器生成的真假新闻的设置。有趣的是,生成的检测器能够很好地区分真假机器生成的新闻,其检测准确度几乎可以与检测人类撰写的新闻相媲美。这表明,可能不必在机器生成的真假新闻上训练就能够检测它们。如果我们的训练数据分布与测试数据分布很好地对齐,对整体检测准确度当然会有帮助;然而,在现实世界部署中,由于分布转移或由于我们对现实世界场景中新数据的分布不了解(例如,我们不知道有多少新闻文章是机器生成的,更重要的是,这种分布可能随着模型更新和其他因素(Omar et al., 2022)而随时间变化),训练检测器最有效的方式是在人类撰写的真假新闻文章上训练。
过渡共存设置。在这种设置中,真实新闻类别的训练数据由机器生成和人类撰写的文章平等组成。值得注意的是,当假新闻训练数据完全由人类撰写时,MF子类的准确度相对较低,仅为20.44%,而HF类别的检测准确度高达79.93%。相反,当假新闻类别完全是MF时,HF子类的准确度降低到仅26.19%,而MF的准确度很高。回顾我们之前在人类遗产阶段的分析,这可能归因于检测器利用指示文章来源(机器或人类)而非其真实性的特征。在训练数据中没有HF的情况下,检测器可能会采取捷径,假设所有假新闻都是机器生成的,从而导致HF子类的准确度降低。当训练期间没有MF数据时,也可能出现类似情况,这可能导致检测器在测试时将MF文章错误分类为真实新闻。此外,即使假新闻类别中含有一半MF和一半HF,MF子类的检测准确度始终超过其他子类,而HR的准确度最低。这种检测准确度并不像仅在HF和HR上训练那样平衡(参见人类遗产阶段MF部分为0%的结果,蓝色阴影区域)。这突出了一个关键见解:在训练期间努力实现每个子类的完美平衡可能不会产生像仅在人类生成的真假新闻上训练那样好的结果。然而,由于与其他三个子类(HR、HF、MF)的训练结果比纯粹在人类撰写的真假新闻上训练的结果更好,整体性能可能会更好(取决于测试集中的子类分布)。
机器主导设置 在这种设置中,真实新闻类别的全部训练数据由MR组成,训练期间没有接触到HR示例。当假新闻类别只有HF作为训练示例(即0% MF部分)时,检测器在辨别HF和MR方面表现出色,似乎是通过识别文章的来源(机器或人类)而不是建模其事实性。鉴于建模事实性本质上比确定文章的来源更具挑战性,这种方法降低了对MF和HR子类的检测准确度。值得注意的是,将适度的33% MF文章引入训练数据,引发了MF检测准确度的巨大飙升,从区区4.41%跃升至令人印象深刻的98.04%。这种迅速的适应表明,在这个训练集中,检测器有能力区分真假内容,而不会被表面特征误导,这些表面特征用于分类MF和MR类别。这种行为暗示了一种可能性,即机器生成文章(MF和MR)的真实性比人类生成文章(HF和HR)更容易辨别。通过比较机器主导设置(100% MF)和人类遗产设置(0% MF),可以进一步阐明这一假设,实验表明,专门在人类撰写文章上训练的检测器即使面对机器生成内容也表现出值得称赞的准确度,而相比之下,完全在机器生成文章上训练的检测器经常错误地将HF子类分类为真实。
