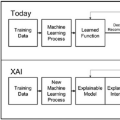
可解释人工智能(XAI)应对了对人工智能系统透明度和可解释性的日益增长的需求,从而增强了决策过程中的信任和问责制。
本书提供了全面的可解释人工智能(XAI)指南,将基础概念与先进方法相结合。它探讨了传统模型(如决策树、线性回归和支持向量机)中的可解释性,并分析了深度学习架构(如卷积神经网络(CNN)、递归神经网络(RNN)和大规模语言模型(LLMs))的解释挑战,包括BERT、GPT和T5等模型。 本书还介绍了实用的技术,如SHAP、LIME、Grad-CAM、反事实解释和因果推断,并通过Python代码示例展示了这些技术在实际应用中的使用。 案例研究阐明了XAI在医疗、金融和政策制定中的作用,展示了其在公平性和决策支持中的影响。本书还涵盖了解释质量的评估指标、前沿XAI工具和框架的概述,以及新兴的研究方向,如联邦学习中的可解释性和伦理人工智能问题。
本书旨在面向广泛读者群,提供了掌握XAI所需的理论洞察力和实践技能。书中还提供了实践示例和附加资源,可通过配套的GitHub仓库https://github.com/Echoslayer/XAI_From_Classical_Models_to_LLMs
引言
**1.1 可解释人工智能(XAI)的背景与重要性
人工智能(AI)已渗透到我们日常生活的各个方面,从智能手机上的预测文本到医疗和金融领域中的复杂决策系统 [1]。尽管AI在准确性和效率上表现出色,但它常常因其“黑箱”特性而受到批评,尤其是在深度学习和大规模语言模型(LLMs)等复杂模型中 [2]。此时,可解释人工智能(XAI)应运而生 [3]。 可解释人工智能的目标是使AI决策变得透明、可理解和可解释 [4]。AI系统缺乏可解释性引发了关于信任、问责制和公平性的担忧 [5]。举例来说,假设一个AI系统拒绝了银行贷款申请。如果没有解释,申请人将无法理解决策为何做出,也不清楚未来申请时可以改进哪些方面。 此外,像欧盟的《通用数据保护条例》(GDPR)等监管机构强调“解释权”,这进一步增加了对可解释AI系统的需求 [6, 7]。可解释人工智能不仅能够建立用户信任,还能促进调试、合规性和AI系统性能的提升 [8]。它解决了一个根本性问题:我们如何信任一个我们无法理解的系统?
**1.2 可解释人工智能(XAI)的核心概念和定义
在深入探讨可解释人工智能的核心概念之前,让我们先定义一些本书中将使用的关键术语: * 可解释性(Interpretability):指人类能够理解决策原因的程度。这通常涉及将复杂模型预测结果简化为人类可以理解的见解 [2]。 * 透明性(Transparency):模型结构和数据的开放性与可访问性,允许外部审查。像决策树这样的透明模型被认为本质上具有可解释性 [9]。 * 公平性(Fairness):确保AI系统不会基于种族、性别或年龄等敏感属性产生偏见或歧视的保证 [10]。 * 可解释性(Explainability):指机器学习模型内部机制可以理解的程度。可解释性比可解释性更进一步,关注“为什么”做出某个决策 [11]。
这些概念并非互相排斥,而是XAI的相互关联的各个方面。例如,透明性有助于提高可解释性,而可解释性则促进了可解释性。理解这些术语至关重要,因为它们构成了我们讨论XAI技术和应用的基础。
**1.3 XAI、透明性、可解释性与公平性在AI中的关系
透明性、可解释性和公平性之间的关系复杂,但对于可靠AI系统的开发至关重要 [12]。让我们通过几个例子来说明这些概念: * 透明性示例:想象一个简单的线性回归模型,根据区域、位置和房产年龄等特征预测房价。模型的系数可以轻松检查和解释,使其具有透明性 [13]。 * 可解释性示例:用于医疗诊断的决策树可以提供清晰的逐步推理,帮助非专家理解其预测过程,从而具有可解释性 [14]。 * 公平性示例:在一个预测警务模型中,如果训练数据包含有偏的犯罪报告,该模型可能会对特定人群进行不成比例的打击,从而引发公平性问题 [15]。
**1.4 本书结构与读者指南
本书旨在引导读者理解可解释人工智能(XAI)的基本概念,并逐步深入探讨先进技术,探索未来的研究机会。以下是各章的简要概述: * 第二章 - 可解释人工智能的理论基础:本章深入探讨了为什么可解释性在AI中如此重要,讨论了可解释性与模型复杂性之间的内在权衡,并概述了在实现有意义解释时面临的挑战。 * 第三章 - 传统机器学习模型的可解释性:聚焦于决策树 [14]、线性回归 [13]、支持向量机 [16] 和贝叶斯模型等经典模型,强调它们的内在可解释性和直观的解释方式。 * 第四章 - 深度学习模型的可解释性:探讨了深度学习模型(包括卷积神经网络(CNN)和递归神经网络(RNN))的可解释性问题,并介绍了特征可视化 [17] 和注意力机制 [18] 等技术。 * 第五章 - 大规模语言模型(LLMs)的可解释性:提供了关于大规模语言模型(包括BERT [19]、GPT [20] 和 T5 [21])的可解释性挑战的全面分析。该章节介绍了探测、基于梯度的分析和注意力权重解释等技术。 * 第六章 - 可解释人工智能的技术:介绍了多种模型解释技术,涵盖了内在方法(如特征重要性)和事后方法(如SHAP [22]、LIME [23] 和 Grad-CAM [24])。本章还包括反事实解释和因果推断技术等高级主题。 * 第七章 - 可解释人工智能的应用:讨论了XAI在各个行业中的实际应用案例,包括医疗 [8, 25]、金融、法律和政策制定。本章提供了XAI如何增强决策支持并解决公平性问题的示例。 * 第八章 - 可解释人工智能的评估与挑战:详细讨论了使用忠实度、稳定性和可理解性等指标评估解释质量的问题。还讨论了深度模型的黑箱特性以及准确性与可解释性之间的权衡。 * 第九章 - 工具与框架:本章回顾了当前XAI工具和框架的现状,包括像LIME和SHAP这样的模型无关工具、像Captum [26]这样的深度学习专用库和用于交互式解释的可视化框架。 * 第十章 - 未来方向与研究机会:总结本书内容,探讨XAI研究中的新兴趋势,如将XAI与法律合规性结合、探索联邦学习中的可解释性以及解决AI解释中的伦理问题。
读者指南:本书旨在面向AI领域的新手和资深专业人士。每一章都在前面章节的基础上进行拓展,但如果读者已熟悉某些主题,完全可以跳过相关章节。全书提供了实用示例,并附有Python代码片段,帮助读者深入理解所讨论的技术。这些示例旨在弥合理论与实践之间的差距,展示XAI方法在现实场景中的应用。我们希望本书能成为您掌握可解释人工智能的全面资源。 所有代码示例可访问GitHub仓库:https://github.com/Echoslayer/XAI_From_Classical_Models_to_LLMs.git