利用人工智能实现认知优势的目的是从海量数据中提取相关信息,以建立军事和非军事态势感知。对视觉信息进行可靠而及时的解读是获得这种优势的有利因素。随着大规模、多模态深度学习模型(如对比语言-图像预训练(CLIP))的兴起,一种有前途的神经网络正在出现,以执行此类视觉识别任务。这种网络能够通过一次性应用光学字符识别(OCR)、面部识别或对象分类从视觉输入中提取知识,而无需进行显式微调。通过选择针对图像中搜索对象的特定文本提示,CLIP 可以实现这种 "零样本"功能。
本文将研究 CLIP 如何用于识别军事领域的车辆,并利用从乌克兰-俄罗斯战争中吸取的经验教训。为了进行分析,创建了一个新的数据集,其中包含有军用和民用车辆的图像,但也有没有车辆的图像。首先,我们搜索适当的查询,利用单个搜索结果,然后组合多个提示。其次,探讨这种方法是否可用于从基于监控摄像头和智能手机的视频流中识别军用车辆。在图像数据集上表明,经过深思熟虑的提示工程,CLIP 模型能够以较高的精确度和召回率识别军用车辆。视频数据集的性能取决于物体大小和视频质量。有了这种方法,盟军和敌方都可以系统地分析大量视频和图像数据,而无需耗时的数据收集和训练。
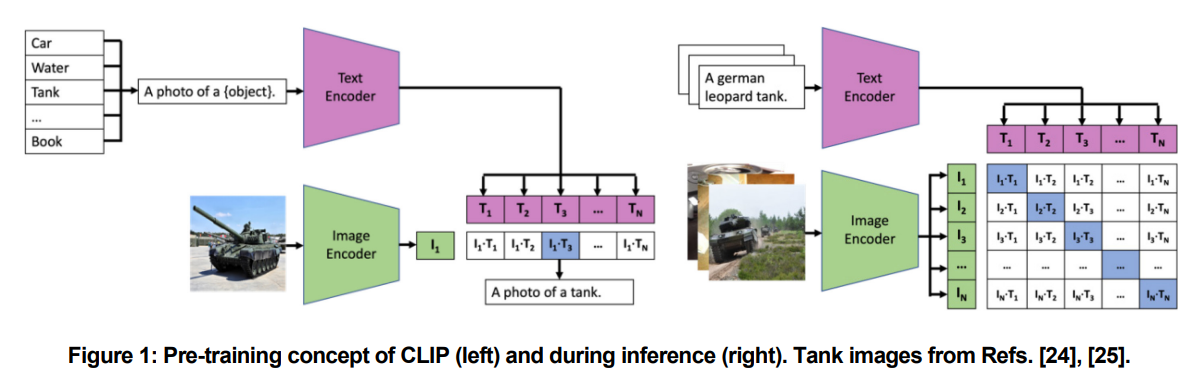
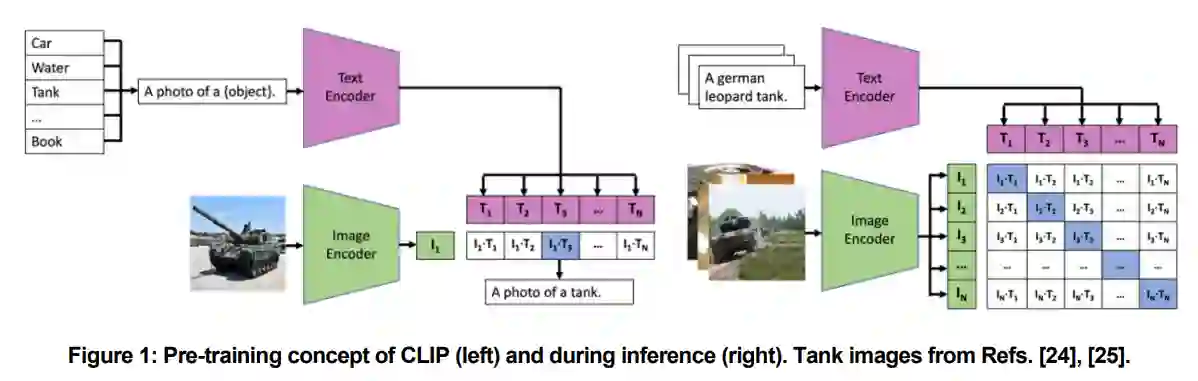
CLIP 模型
CLIP 是目前最好的零样本模型之一。Radford 等人[10] 开发了一种全新的方法,利用简单的对比预训练目标来学习尽可能多的概念。CLIP 在 4 亿个图像-文本对上进行了预训练。不过,该数据集尚未公开,因此不知道有关训练数据的详细信息。图像由图像编码器嵌入,文本由单独的文本编码器嵌入。目标是使用对称交叉熵损失来减少嵌入的距离,如图 1(左)所示。余弦相似度被用作距离度量。基于这一简单的预训练目标,CLIP 可以在没有监督注释的情况下学习一般概念,因此具有很强的零误差能力。ResNet [2] 及各种改进 [13], [14] 和 Vision Transformer [15] 被用作图像编码器,Transformer 架构 [16] 被用于文本嵌入。Radford 等人提供了其 CLIP 模型的九种不同配置。在我们的分析中,我们使用了 ViT-B/16,这是一个中等规模的模型,图像编码器和文本编码器分别有 8620 万和 3780 万个参数。为了防止过拟合,通常会使用一些数据增强,但由于预训练数据集的大小,这些增强可以忽略不计,只进行简单的裁剪。预训练数据集并不公开,因此在训练过程中与军事相关的数据量不得而知。在推理过程中,使用不同的提示(T1、...、TN)对搜索到的类别进行编码,然后根据文本向量与图像向量(I1)之间的距离确定类别,如图 1 所示。