

为计算机生成兵力(CGF)创建行为模型是一项具有挑战性且耗时的任务,通常需要具备复杂人工智能算法编程方面的专业知识。因此,对于了解应用领域和培训目标的主题专家来说,很难建立相关的场景并使培训系统与培训需求保持同步。近年来,机器学习作为一种为合成智能体建立高级决策模型的方法,已显示出良好的前景。这类智能体已经能够在扑克、围棋和星际争霸等复杂游戏中击败人类冠军。我们有理由相信,军事模拟领域也有可能取得类似的成就。然而,为了有效地应用这些技术,必须获得正确的工具,并了解算法的能力和局限性。
本文讨论了深度强化学习的高效应用,这是一种机器学习技术,可让合成智能体学习如何通过与环境互动来实现目标。我们首先概述了现有的深度强化学习开源框架,以及最新算法的参考实现库。然后,我们举例说明如何利用这些资源为旨在支持战斗机飞行员培训的计算机生成兵力软件构建强化学习环境。最后,基于我们在所介绍环境中进行的探索性实验,我们讨论了在空战训练系统领域应用强化学习技术的机遇和挑战,目的是为计算机生成的兵力有效构建高质量的行为模型。
计算机生成兵力的学习环境
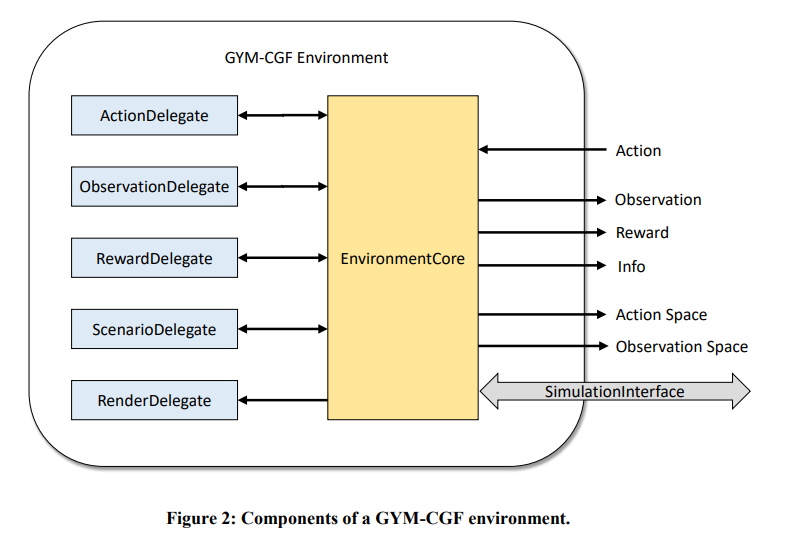
在实验中,将强化学习环境构建为实现 OpenAI Gym 接口的 Python 模块,因为许多现有的强化学习算法实现都支持该接口。环境的结构如图 2 所示。环境的大部分功能都在 EnvironmentCore 类中实现。该类通过 SimulationInterface 与本地或远程计算机上运行的仿真进程通信,在仿真中的实体和控制它们的强化学习智能体之间传输观察结果和操作。SimulationInterface 还用于在计算机生成兵力软件中加载模拟场景。
模拟与环境模块之间的通信是通过 ZeroMQ 实现的,ZeroMQ 是一个开源、轻量级的消息传递中间件,可绑定多种编程语言,包括 C++ 和 Python。ZeroMQ 可以轻松实现几种流行的消息传递模式,如请求-回复、发布-订阅和推-拉。ZeroMQ使用谷歌协议缓冲区(Google protocol buffers)来指定消息,这是一种语言中立、平台中立的结构化数据序列化机制。使用简单的协议语言创建消息规范,然后将其编译成各种编程语言(包括 C++ 和 Python)的源代码。
要配置特定的环境,需要使用一些委托对象:
- ActionDelegate: ActionDelegate 指定环境的动作空间(OpenAI Gym 中提供的空间定义之一)。在执行过程中,它将该空间中的动作作为输入,并将其转换为 ActionRequest 消息,然后由 EnvironmentCore 发送给模拟中的实体。 -ObservationDelegate:指定环境的观察空间(OpenAI Gym 中提供的空间定义之一)。在执行过程中,它将来自模拟实体的状态更新信息作为输入,并将其转换为来自观察空间的状态观察信息,然后将其呈现给智能体。
- RewardDelegate:将状态观测信息作为输入,并计算出一个标量奖励信号,然后将其发送给智能体。
- ScenarioDelegate:管理要模拟的情景,包括终止标准。对于训练过程中的每个情节,委托机构都会根据需要调整场景内容,并生成模拟请求(SimulationRequest)消息,由环境核心(EnvironmentCore)发送给模拟。
- RenderDelegate:会渲染模拟场景当前状态的视图。这对调试非常有用。我们使用 Python Matplotlib 和 Basemap 库实现了简单的地图渲染。
空战仿真领域的深度强化学习
在空战模拟领域的深度强化学习实验中,我们发现了一些挑战,这些挑战通常不存在于许多强化学习的简单基准环境中。状态和行动空间的维度高且复杂,使得智能体难以学习重要的状态特征和合适的决策策略。例如,在许多场景中,由于传感器的限制或电子战的影响,环境只能被部分观测到。此外,在大多数场景中,智能体不会单独行动,而是必须与盟友合作,同时与敌人竞争,以达到目标。为了处理长期和短期目标,可能需要在不同的时间尺度上进行决策。代表最重要目标的奖励通常是延迟的、稀疏的,例如,如果智能体取得了胜利,就会在情景结束时给予奖励,这样就很难将功劳归于正确的行动。此外,根据训练需要,智能体的目标也有可能在不同的模拟运行中有所不同。例如,我们可能需要调整模拟的难度,以适应受训者的熟练程度。最后,由于运行高保真模拟的计算成本很高,因此尽可能提高学习过程的样本效率非常重要。在下面的章节中,我们将讨论一些可以用来应对这些挑战的技术。


