强化学习(RL)方法的主要关注点之一是如何将在模拟环境中学到的策略转移到现实环境中,同时获得相似的行为和性能(即模拟到现实的可转移性),这一点在机器人控制器中尤为重要[1]。在过去的几年里,为了缩小模拟世界与现实世界之间的差距,实现更有效的策略转移,人们已经跟踪了多个研究方向。领域随机化是学习迁移中应用最广泛的方法之一,它将模型暴露在各种条件下,使模型对这些方面的建模误差具有鲁棒性。随机化被认为是实现从模拟到真实转移和一般稳健策略的关键[2]。另一种常用的方法是系统识别,它使用具有精确物理和动态系统数学模型的高保真环境。不过,系统识别的缺点是计算量大,因此需要更多时间进行训练。其他相关方法有零点转移法和域适应法 [3]。
大多数关于 RL 的研究都集中在使用端到端方法的低级控制器上,其中 RL 网络将机载传感器提供的原始信息作为输入,并将应用于执行器的连续控制动作作为输出 [4]。然而,这种方法有两个主要局限性:(i) 它对平台的配置有很强的依赖性,例如,与传感器提供的信息及其质量有关,或与推进器等执行器的数量及其配置有关;(ii) 模拟到现实的传输差距更难缩小,因为经过训练的策略会受到机器人平台动态的强烈影响。例如,在文献[5]中,作者在真实飞行器中使用了第二个训练过程,学习过程继续在线进行。在文献[6]中,控制器需要进行额外的调整,以弥补模拟与真实世界之间的差异,但即便如此,现场结果仍显示出较低的性能。
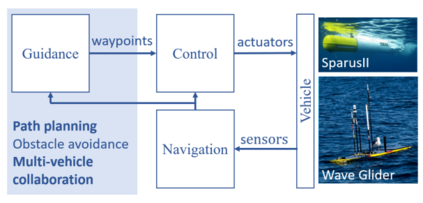
在本研究中,我们介绍了一种平台便携式深度强化学习方法,该方法已被用作自主车辆定位水下物体的路径规划系统,如图 1 所示。我们设计了一个高级控制系统,以减少上述问题,并具有强大的模拟到实际的传输能力。此外,我们的方法易于配置,可在不同平台和不同条件下部署。例如,训练有素的智能体已成功部署在两种不同的飞行器上: (i) 液体机器人公司(Liquid Robotics,美国)的自主水面飞行器(ASV)"波浪滑翔机";以及 (ii) IQUA 机器人公司(IQUA Robotics,西班牙)的自主水下飞行器(AUV)"Sparus II"。测试在加利福尼亚州蒙特雷湾和西班牙加泰罗尼亚 Sant Feliu de Guıxols 港口进行。在这两种情况下,飞行器都使用了仅测距的目标跟踪方法来定位锚定的应答器[7]。
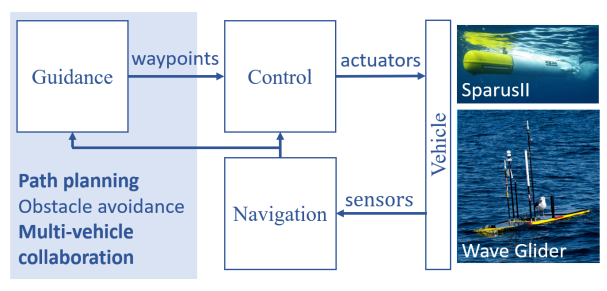
图 1:制导、导航和控制系统,以及与制导相关的一些主要研究方向。用粗体字表示详细描述的方面。