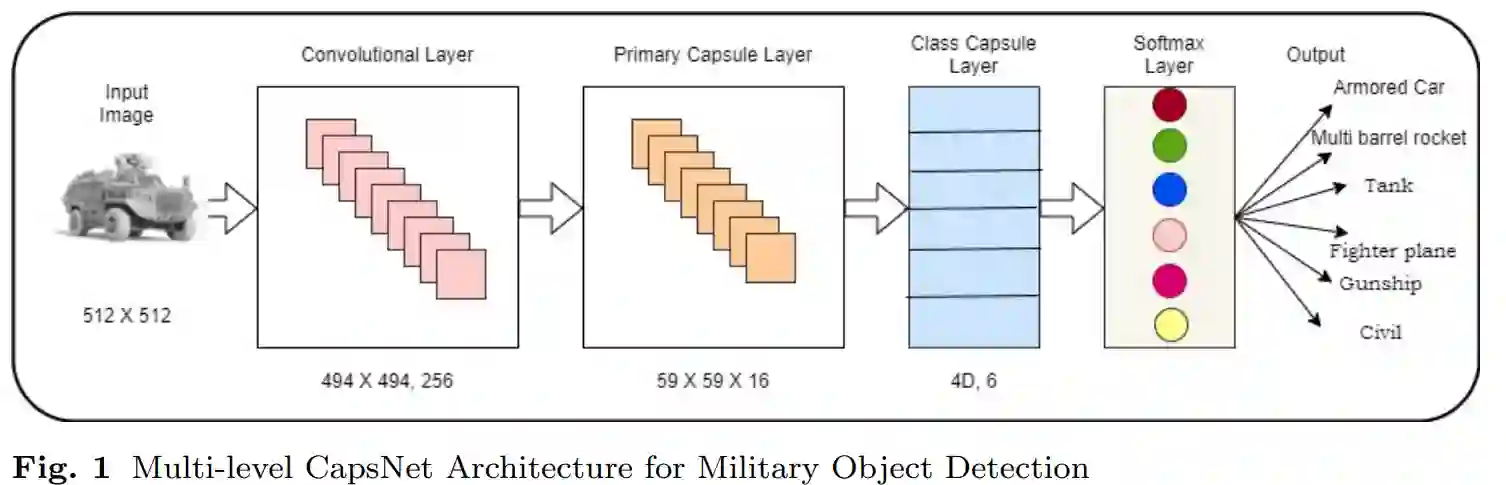
自动目标检测在自动化战争行动中发挥着重要作用。自动目标检测背后的关键概念是从捕获的图像中识别军事目标。对于给定图像中的目标识别,卷积神经网络(CNN)是一个强大的分类网络。CNN是位置不变的,其性能主要取决于训练集的大小。由于军事目标的操作和安全问题,训练数据的大小一般来说可利用的比例较小。因此,CNN的性能可能会急剧下降。为了解决军事物体的问题,引入了一个相对较新的神经网络架构,即胶囊网络(CapsNet)。因此,在这篇文章中,一个名为多层CapsNet框架的CapsNet变体被用于小型训练集情况下的军事目标识别。本文介绍的框架在一个从互联网上收集的军事目标数据集上得到了验证。该数据集特别包含五个军事目标和类似的民用目标。本文提出的框架在军事目标识别方面有很大的改进,准确率达到96.54%。实验表明,所提出的框架可以实现较高的识别精度,优于许多其他算法,如传统的支持向量机和基于转移学习的CNN。

在过去的几十年里,战争越来越依赖尖端技术,因此,战争模式从传统战争转变为信息化战争,这已成为当今战争的主要类型。快速、熟练和精确地发现军事目标,以达到精确攻击的目的,这不仅是当今战争的基本利益,而且也是改进早期基本警报系统的重要组成部分[1]。
目标检测是跟踪和识别目标的基础。所有的后续操作都取决于检测图像中的目标。到目前为止,普遍使用的目标识别策略基本上包括一些常规的策略;例如,特征匹配策略、背景显示技术、边缘划分策略、依赖于深度学习的技术,以及依赖于视觉质量的策略。传统识别方法中的特征匹配技术,[2],[3],[4]具有较高的识别精确性和准确性,但是它的独立性和估计有效性较低,而且其项目应该是物理安装的。背景识别策略[5],[6],[7]可以完成项目与背景的程序化分离,但是模型的建立和更新很繁琐,动态背景会干扰结果。阈值分割策略[8],[9]对于有正常背景和明显目标的情况是有利的和熟练的,然而在复杂条件下的识别效果是不能接受的。总而言之,传统的识别计算有一些限制,这使得它很难解决现实生活中复杂多样的情况下的问题。此外,这些技术依赖于人工阻抗,其通用能力还远远不够。
近年来,在计算机视觉的研究问题上有了快速和富有成效的发展。计算机视觉领域预计将在视频处理、医疗保健和安全等不同的应用中受到很大冲击。计算机视觉使机器有能力看到并向外感知其总体环境,就像人们利用自己的眼睛一样。这一成就的一部分来自于人工智能技术的实施和调整,而另一部分则来自于对明确的计算机视觉问题的新描述和模型的发展,或来自于有效安排的改进。
近年来,计算机视觉的一个子领域取得了非凡的进展,那就是目标识别。目标识别是计算机视觉的一种类型,正在企业和消费者网络中获得力量。鉴于一组不同的物体,目标识别包括决定图片中所有目标的面积和大小。因此,目标识别器是发现所有的目标,这些目标至少有一个是给定的目标类别,几乎不考虑比例、面积、目前的情况、关于相机的情况、中途的障碍物和光线条件。目标识别正在进入一个广泛的业务范围,其使用案例包括从个人安全到工作环境的效率。面部识别是其中的一种类型,它可以作为一种安全努力,只允许某些人进入一个有深刻特征的区域,例如国防或军事。它还可以用来检查预先定义的战争区域内的个人数量,从而改变其他专门的设备,以帮助减少用于战斗的时间。它也可以被用于视觉网络搜索工具,以帮助买家找到他们正在追逐的特定东西,例如,Pinterest就是一个例子,因为整个社交和购物阶段都是围绕着这种创新进行的。
在许多计算机视觉框架中,目标识别是前面的主要任务,因为它可以获得关于被识别的物品和场景的额外数据。当目标识别为脸部时,可以想象获得额外的数据,如感知特定的目标,即识别主体的脸部,在一连串的图像中跟踪该目标,如在视频中跟踪战争车辆的运动,并删除有关该目标的额外数据。目标识别已被用于众多的应用中,其中最著名的是:人与计算机之间的互动、机器人技术、先进的移动电话等购物电子产品、追踪和跟踪军事中的物体、搜索引擎和自动驾驶车辆。所有这些应用都有不同的需求,包括:处理时间(如在线、实时和离线),对故障的反应能力,以及在姿势变化情况下的识别。虽然许多应用考虑从单一视角定位单一目标,但其他应用需要从不同角度识别不同的目标或单一目标。
基于深度学习的目标识别技术[10],[11],[12]可以应用于不同的应用场景,因为它们在从一个视角显示时具有适应性和优势,而在发现和识别不同种类的目标时具有特殊的差异性。这就是为什么它们被应用于许多应用的动机,比如观察和识别车辆和步行者。无论如何,这种技术的检测效果在很大程度上依赖于集合,特别是巨大的信息索引和物理标记的信息索引,这进一步需要大量的计算资产。人眼的视觉机制使视觉框架能够从巨大的图片信息中挤出最吸引人的特征,从而大大提高了处理数据的熟练程度。因此,视觉注意力策略已经逐渐成为计算机视觉领域的一个有趣的问题,并以这种方式吸引了众多研究人员的关注。一段时间以来,许多科学家提出了不同的策略来获取重要的目标,例如,基于图形的视觉显著性[13],频率调整检测[14],基于区域对比度的目标检测[15],成本敏感的支持向量机(SVM)[16],等等。除了前面提到的策略及其改进的变体之外,在过去两年中,还出现了许多利用深度学习的新目标检测技术,例如监督显著目标检测 [17]、循环全连接网络 [18],其标准是通过开发和准备神经网络来生成显著性图。
由于对数据进行分类的军事准则,国内外在这一领域所做的有效调查很少。通过对最近所做的工作进行分析,我们发现,需要为军事目标检测任务设计有效的方法或系统。为了提高战争中使用的武器和车辆的生存能力,它们将在非战争时期进行伪装。因此,伪装,加上令人困惑和可改变的战区,确实使识别军事目标变得更加困难。考虑到军事目标识别任务的质量和先决条件,本文通过对人类视觉感知策略的模仿,提出了一种检测军事目标的方法。本文的工作探讨了以下几个部分:a)介绍一种基于深度学习的胶囊网络(CapsNet)的新方法,用于检测给定图像中的军事目标;b)收集一个包括足够数量的军事目标的数据集,以验证所提出的方法。