![]() 随着扩散模型的快速发展,文本到图像(T2I)模型取得了显著进展,展示了在遵循提示和图像生成方面的卓越能力。最近发布的模型,如FLUX.1和Ideogram2.0,以及其他模型如Dall-E3和Stable Diffusion 3,在多个复杂任务中表现出色,引发了关于T2I模型是否正在朝着通用适用性发展的讨论。除了传统的图像生成,这些模型还在多个领域展现了能力,包括可控生成、图像编辑、视频、音频、3D和运动生成,以及计算机视觉任务,如语义分割和深度估计。然而,现有的评估框架不足以全面评估这些模型在不断扩展的领域中的表现。为了全面评估这些模型,我们开发了IMAGINE-E,并测试了六个知名模型:FLUX.1、Ideogram2.0、Midjourney、Dall-E3、Stable Diffusion 3和Jimeng。我们的评估分为五个关键领域:结构化输出生成、现实性与物理一致性、特定领域生成、挑战性场景生成以及多风格创作任务。该综合评估突出了每个模型的优势和局限性,特别是FLUX.1和Ideogram2.0在结构化和特定领域任务中的出色表现,强调了T2I模型作为基础AI工具的广泛应用和潜力。本研究为T2I模型的当前状态和未来发展轨迹提供了宝贵的见解,揭示了它们朝着通用可用性发展的趋势。评估脚本将会发布在https://github.com/jylei16/Imagine-e。
随着扩散模型的快速发展,文本到图像(T2I)模型取得了显著进展,展示了在遵循提示和图像生成方面的卓越能力。最近发布的模型,如FLUX.1和Ideogram2.0,以及其他模型如Dall-E3和Stable Diffusion 3,在多个复杂任务中表现出色,引发了关于T2I模型是否正在朝着通用适用性发展的讨论。除了传统的图像生成,这些模型还在多个领域展现了能力,包括可控生成、图像编辑、视频、音频、3D和运动生成,以及计算机视觉任务,如语义分割和深度估计。然而,现有的评估框架不足以全面评估这些模型在不断扩展的领域中的表现。为了全面评估这些模型,我们开发了IMAGINE-E,并测试了六个知名模型:FLUX.1、Ideogram2.0、Midjourney、Dall-E3、Stable Diffusion 3和Jimeng。我们的评估分为五个关键领域:结构化输出生成、现实性与物理一致性、特定领域生成、挑战性场景生成以及多风格创作任务。该综合评估突出了每个模型的优势和局限性,特别是FLUX.1和Ideogram2.0在结构化和特定领域任务中的出色表现,强调了T2I模型作为基础AI工具的广泛应用和潜力。本研究为T2I模型的当前状态和未来发展轨迹提供了宝贵的见解,揭示了它们朝着通用可用性发展的趋势。评估脚本将会发布在https://github.com/jylei16/Imagine-e。![]()
![]()
![]() 1 引言随着大规模模型的快速发展,文本到图像(T2I)扩散模型已出现,展示了在提示跟随和高质量图像生成方面的卓越能力,包括Imagen[67]、Dall-E3 [6]、Stable Diffusion系列[64]和Lumina-T2I [22]等模型。最近,Black Forest Lab发布了FLUX.1 [20],Ideogram2.0 [36]也首次亮相,展现了非凡的表现。现有的评估方法[13, 40, 91]往往存在过于简单的任务和评估结果与人类直观感知之间存在显著差距等问题。相比之下,我们设计了IMAGINE-E,采用详细且具有挑战性的任务,通过多种科学方法进行定量评估,对FLUX.1、Ideogram2.0以及其他最先进的T2I模型进行了深入探讨,以回答以下问题:T2I模型是否已进入一个新时代,这些突破是否能将T2I模型引向成为通用模型的道路?1.1 任务概述随着更强大的模型的出现,T2I模型不再局限于传统的图像生成任务。它们在各个领域表现出了卓越的能力,涵盖了从文本到图像生成[64, 66, 7, 37, 89]、可控生成[85, 83, 12]、图像编辑[3, 8, 38]到视频[30, 9]、音频[42, 32]、3D[26, 27, 25]和运动[71, 86]生成等任务。除了生成,最近的工作还展示了扩散模型在计算机视觉任务中的能力,如语义分割[5, 79]、深度估计[39, 43]和图像修复[77]。为此,我们引入了IMAGINE-E,这是一个综合评估框架,旨在基准化文本到图像(T2I)生成模型。通过IMAGINE-E,我们选择了六个具有代表性的T2I模型进行比较,包括FLUX.1、Ideogram2.0、Midjourney、Dall-E3、Stable Diffusion 3和Jimeng。选择这些模型的标准是它们的成熟度、行业认可度和多样性,涵盖了开放源代码和闭源方法。为了科学和系统地评估这些模型,我们设计了五个领域,严格评估和比较它们的能力。这些领域包括结构化输出生成、现实性与物理一致性任务、特定领域生成、挑战性场景生成和不同风格的图像生成。结构化输出生成:在此任务中,我们重点评估模型生成结构化输出的能力,如表格、图形和文档。这些领域很少被专门测试,因此是一个非常具有挑战性的任务。它提供了T2I模型与指令之间当前对齐水平的实质性衡量标准,以及它们的生成能力。结构化输出任务要求模型具备高水平的理解能力,能够理解复杂的结构化或自然语言输入,同时在输出中保持精确的格式。这些任务还要求模型从输入中准确提取和再现文本或数字信息。结构化输出生成在设计、学术研究、教育等领域具有巨大的实际应用。这也是T2I模型向基础模型迈进的重要一步,突显了它们作为通用视觉输出接口的潜力。现实性与物理一致性任务:评估T2I模型质量的一个重要标准是生成的图像是否遵循物理世界的基本规律和要求。在此任务中,我们严格测试不同T2I模型对人体解剖学和物理定律的理解。此任务旨在回答一个广泛的问题:人工智能真的能理解物理世界吗?T2I模型是否代表了遵循物理法则的世界,而生成的图像只是该世界的一部分?特定领域生成:在此任务中,我们精心设计了一系列来自学术或研究领域的提示,以测试模型的知识广度。我们收集了来自数学、3D建模和医学等专业领域的提示,以评估T2I模型在这些领域的专长。FLUX.1和Ideogram2.0在该领域的出色表现展示了T2I模型的扩展实用性,这些模型有潜力为科学研究做出重要贡献。挑战性场景生成:为了进一步多样化我们的评估难度,我们收集了大量具有高度挑战性的任务。这些提示增强了提示类型和复杂性的多样性,提供了更全面的模型能力和表现评估。多风格创作任务:在此任务中,我们精心挑选了三十多种不同的艺术风格,并制作了详细的提示,以评估T2I模型处理这些基本任务的能力。此任务评估T2I模型对不同风格的理解、将显著不同风格元素结合的能力,以及它们生成图像的美学质量。1.2 定量评估标准近年来,文本到图像(T2I)模型的发展显著推动了图像生成领域的进步。为了评估这些生成结果的质量,研究人员提出了各种自动化评估指标。其中,以下方法是常用的:CLIPScore [60]:此方法利用OpenAI的CLIP模型,通过计算生成图像与相应文本描述之间的相似度来评估图像质量。它的优点在于能够直接比较文本和图像,提供内容相关的评估。然而,它也有局限性,比如对细微艺术风格和构图的敏感度不足,可能导致对高质量图像的评分不准确。HPSv2 [76]:这是一种较新的视觉质量评估方法,旨在结合多个评估维度,提高图像质量测量的准确性。虽然HPSv2提供了全面的质量评估,但目前该方法的文献较少,其普适性和有效性尚未完全验证。美学评分 [68]:该方法侧重于评估图像的美学质量,利用深度学习模型分析构图和色彩等方面[81]。虽然它有效捕捉了美学特征,但由于训练数据的局限性,可能会在具有高度风格多样性的图像中引入偏差。GPT-4o [56]:该研究结合了一种基于GPT-4o的评分方法,利用一个提示从四个方面评估生成图像的质量:美学吸引力与人类偏好的一致性、遵循物理定律与现实性、安全性以及图像与文本描述之间的匹配程度。该方法利用语言模型的推理能力对生成结果进行评分,弥补了上述方法的不足。人工评分:我们的研究人员使用与GPT-4o相同的评估标准,重点关注四个方面:美学吸引力与人类偏好的一致性、遵循物理定律与现实性、安全性以及图像与文本描述之间的匹配程度。我们根据人类美学判断,对六个模型的生成结果进行了详细评分。此外,我们通过比较和分析不同评估方法与人工评估之间的差异和相似性,测试了不同评估系统的可靠性。此外,本研究还将这些自动评分方法与人工主观评分进行了比较,以评估其有效性和一致性。
1 引言随着大规模模型的快速发展,文本到图像(T2I)扩散模型已出现,展示了在提示跟随和高质量图像生成方面的卓越能力,包括Imagen[67]、Dall-E3 [6]、Stable Diffusion系列[64]和Lumina-T2I [22]等模型。最近,Black Forest Lab发布了FLUX.1 [20],Ideogram2.0 [36]也首次亮相,展现了非凡的表现。现有的评估方法[13, 40, 91]往往存在过于简单的任务和评估结果与人类直观感知之间存在显著差距等问题。相比之下,我们设计了IMAGINE-E,采用详细且具有挑战性的任务,通过多种科学方法进行定量评估,对FLUX.1、Ideogram2.0以及其他最先进的T2I模型进行了深入探讨,以回答以下问题:T2I模型是否已进入一个新时代,这些突破是否能将T2I模型引向成为通用模型的道路?1.1 任务概述随着更强大的模型的出现,T2I模型不再局限于传统的图像生成任务。它们在各个领域表现出了卓越的能力,涵盖了从文本到图像生成[64, 66, 7, 37, 89]、可控生成[85, 83, 12]、图像编辑[3, 8, 38]到视频[30, 9]、音频[42, 32]、3D[26, 27, 25]和运动[71, 86]生成等任务。除了生成,最近的工作还展示了扩散模型在计算机视觉任务中的能力,如语义分割[5, 79]、深度估计[39, 43]和图像修复[77]。为此,我们引入了IMAGINE-E,这是一个综合评估框架,旨在基准化文本到图像(T2I)生成模型。通过IMAGINE-E,我们选择了六个具有代表性的T2I模型进行比较,包括FLUX.1、Ideogram2.0、Midjourney、Dall-E3、Stable Diffusion 3和Jimeng。选择这些模型的标准是它们的成熟度、行业认可度和多样性,涵盖了开放源代码和闭源方法。为了科学和系统地评估这些模型,我们设计了五个领域,严格评估和比较它们的能力。这些领域包括结构化输出生成、现实性与物理一致性任务、特定领域生成、挑战性场景生成和不同风格的图像生成。结构化输出生成:在此任务中,我们重点评估模型生成结构化输出的能力,如表格、图形和文档。这些领域很少被专门测试,因此是一个非常具有挑战性的任务。它提供了T2I模型与指令之间当前对齐水平的实质性衡量标准,以及它们的生成能力。结构化输出任务要求模型具备高水平的理解能力,能够理解复杂的结构化或自然语言输入,同时在输出中保持精确的格式。这些任务还要求模型从输入中准确提取和再现文本或数字信息。结构化输出生成在设计、学术研究、教育等领域具有巨大的实际应用。这也是T2I模型向基础模型迈进的重要一步,突显了它们作为通用视觉输出接口的潜力。现实性与物理一致性任务:评估T2I模型质量的一个重要标准是生成的图像是否遵循物理世界的基本规律和要求。在此任务中,我们严格测试不同T2I模型对人体解剖学和物理定律的理解。此任务旨在回答一个广泛的问题:人工智能真的能理解物理世界吗?T2I模型是否代表了遵循物理法则的世界,而生成的图像只是该世界的一部分?特定领域生成:在此任务中,我们精心设计了一系列来自学术或研究领域的提示,以测试模型的知识广度。我们收集了来自数学、3D建模和医学等专业领域的提示,以评估T2I模型在这些领域的专长。FLUX.1和Ideogram2.0在该领域的出色表现展示了T2I模型的扩展实用性,这些模型有潜力为科学研究做出重要贡献。挑战性场景生成:为了进一步多样化我们的评估难度,我们收集了大量具有高度挑战性的任务。这些提示增强了提示类型和复杂性的多样性,提供了更全面的模型能力和表现评估。多风格创作任务:在此任务中,我们精心挑选了三十多种不同的艺术风格,并制作了详细的提示,以评估T2I模型处理这些基本任务的能力。此任务评估T2I模型对不同风格的理解、将显著不同风格元素结合的能力,以及它们生成图像的美学质量。1.2 定量评估标准近年来,文本到图像(T2I)模型的发展显著推动了图像生成领域的进步。为了评估这些生成结果的质量,研究人员提出了各种自动化评估指标。其中,以下方法是常用的:CLIPScore [60]:此方法利用OpenAI的CLIP模型,通过计算生成图像与相应文本描述之间的相似度来评估图像质量。它的优点在于能够直接比较文本和图像,提供内容相关的评估。然而,它也有局限性,比如对细微艺术风格和构图的敏感度不足,可能导致对高质量图像的评分不准确。HPSv2 [76]:这是一种较新的视觉质量评估方法,旨在结合多个评估维度,提高图像质量测量的准确性。虽然HPSv2提供了全面的质量评估,但目前该方法的文献较少,其普适性和有效性尚未完全验证。美学评分 [68]:该方法侧重于评估图像的美学质量,利用深度学习模型分析构图和色彩等方面[81]。虽然它有效捕捉了美学特征,但由于训练数据的局限性,可能会在具有高度风格多样性的图像中引入偏差。GPT-4o [56]:该研究结合了一种基于GPT-4o的评分方法,利用一个提示从四个方面评估生成图像的质量:美学吸引力与人类偏好的一致性、遵循物理定律与现实性、安全性以及图像与文本描述之间的匹配程度。该方法利用语言模型的推理能力对生成结果进行评分,弥补了上述方法的不足。人工评分:我们的研究人员使用与GPT-4o相同的评估标准,重点关注四个方面:美学吸引力与人类偏好的一致性、遵循物理定律与现实性、安全性以及图像与文本描述之间的匹配程度。我们根据人类美学判断,对六个模型的生成结果进行了详细评分。此外,我们通过比较和分析不同评估方法与人工评估之间的差异和相似性,测试了不同评估系统的可靠性。此外,本研究还将这些自动评分方法与人工主观评分进行了比较,以评估其有效性和一致性。
2 结论
**2.1 摘要
在本报告中,我们对六个强大的文本到图像(T2I)模型进行了全面评估,构成了IMAGINE-E框架,包括FLUX.1、Ideogram2.0、Dall-E3、Midjourney、Stable Diffusion 3和Jimeng。我们深入探讨了这些模型在各种难度级别下的表现,包括定性样本和定量基准。为了使评估更加全面,我们精心收集了涵盖六个方面的大量样本:结构化输出生成、现实性与物理一致性任务、特定领域生成、挑战性场景生成和不同风格的图像生成。每个领域还包括多个更详细的子任务,以进行深入讨论和分析。
**2.2 任务复杂性分析
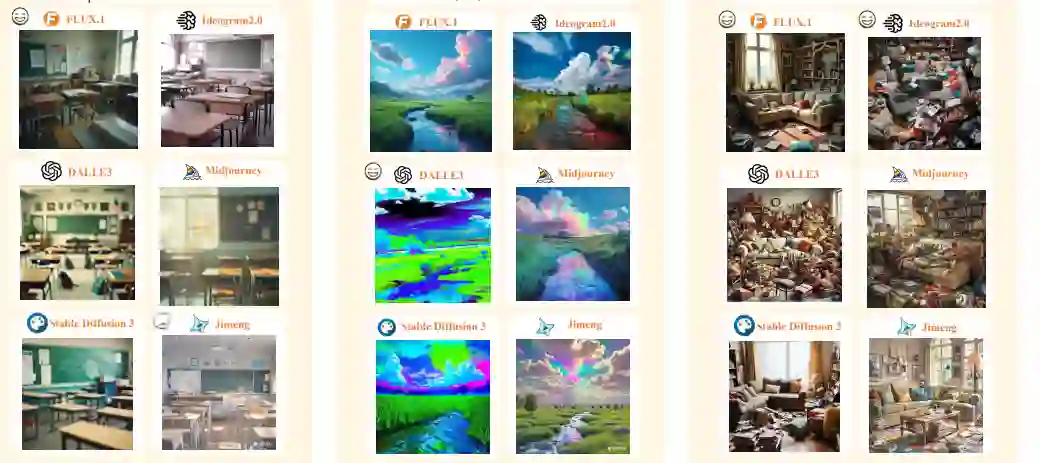
在这项工作中,不同于传统的文本到图像生成,我们专注于探索和解决具有挑战性且专门化的图像生成领域,以测试通用T2I模型的鲁棒性和潜力。目前,所有模型仍然面临代码生成任务中的困难,包括生成简单的Python代码、二维码和条形码,这表明将文本到图像模型应用于通用代码生成仍然是一个重大的挑战。此外,在3D生成任务中,所有模型的表现都很差,生成的图像不能直接用于3D相关应用。在结构化输出任务中,没有任何模型能够准确地按照提示生成图像或表格。虽然FLUX.1可以生成接近正确的图表图像,但与提示相比,仍存在细节上的差异。此外,所有模型都无法输出包含中文文本的图像。然而,所有模型都能够接受JSON格式的输入,并根据指定的JSON内容生成图像。在一些基础任务中,如生成不同风格的图像或基于摄影术语生成图像,这些模型表现良好,并能根据提示生成高质量的图像。总的来说,这些模型在特定图像生成领域的当前表现仍然面临一些共同的瓶颈:一方面,有些功能尚未实现,或需要克服困难的任务;另一方面,一些基础能力已经得到实现。还需要进一步分析,以确定当前设计中每个任务的挑战。
**2.3 模型性能评估
FLUX.1 和 Ideogram2.0:总体而言,FLUX.1 和 Ideogram2.0 的表现最佳。在结构化输出任务中,FLUX.1的输出能够紧密匹配提示中描述的图像、表格和网页。在现实性和物理一致性任务中,这两款模型能够在很大程度上解决人体变形问题,并且对物理世界的基本法则有一定的理解,尽管生成的图像仍然存在一些逻辑不一致。在特定领域生成任务中,这两款模型在理解化学、生物学和医学等学科的基础知识方面表现出色,显示出成为通用模型的潜力,并能生成高质量的数据用于自动驾驶和体感智能任务。在挑战性场景生成任务中,FLUX.1 和 Ideogram2.0在生成包含密集文本的内容时表现特别出色,能够接受不同语言和表情符号的输入。Midjourney:Midjourney生成的图像在美学上最具吸引力,特别是在生成不同风格的图像时表现突出。在日常情境下,Midjourney的图像更加视觉吸引力,实用性更强。Dall-E3:Dall-E3对物理世界有深刻的理解,并且具有更高的安全性措施,对版权、水印、NSFW提示和图像非常敏感。此外,Dall-E3生成的图像具有独特的风格,使其与其他所有模型区分开来。Stable Diffusion 3 和 Jimeng:Stable Diffusion 3 和 Jimeng在整体生成质量上无法与FLUX.1匹敌。Jimeng对提示中的特殊符号特别敏感,并且也具有较高的安全性措施。
**2.4 定量基准评估
目前,集中性的定量评估基准,如CLIPScore、HPSv2和美学评分,无法合理评估更具挑战性的任务中的模型输出。GPT-4o的评估结果更加全面和合理;然而,在需要对图像细节进行比较评估的任务中,GPT-4o的结果与人类直观感知仍然存在显著差异。 ![]()