

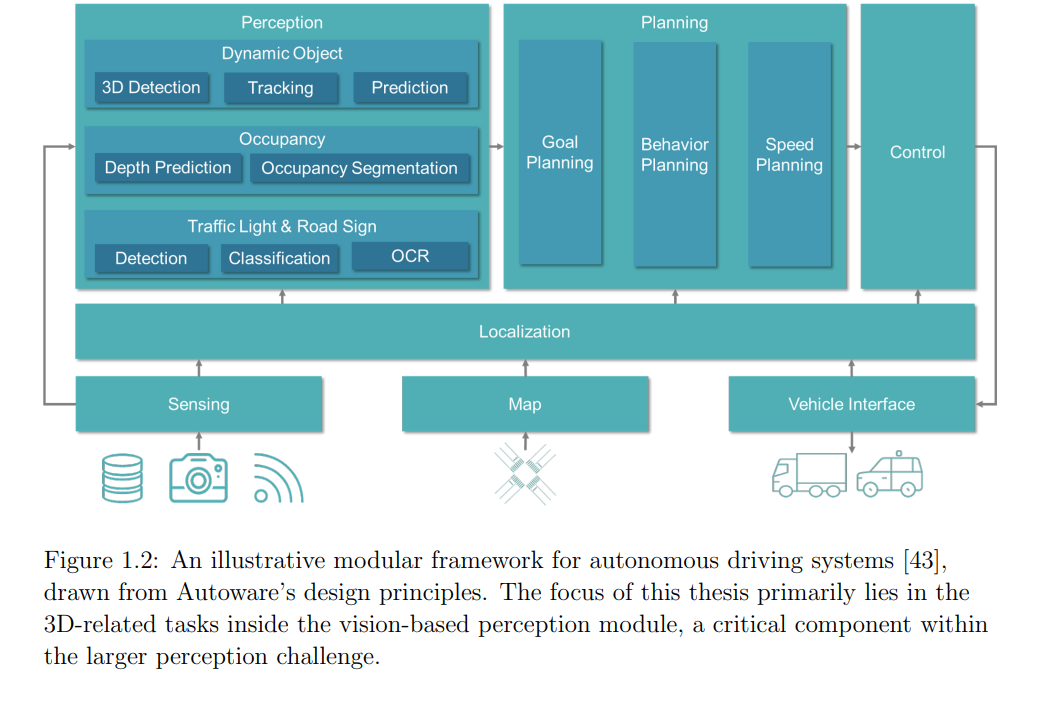
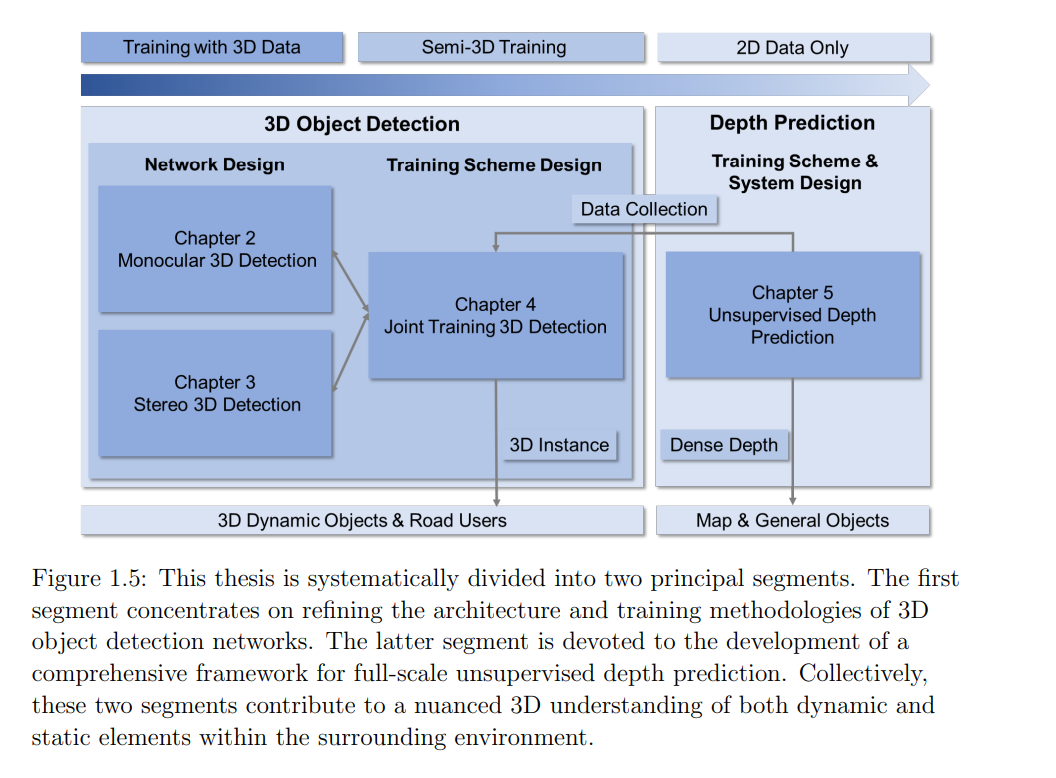
3D 感知在自动驾驶领域中起着至关重要的作用。基于视觉的 3D 感知方法依赖于仅使用相机输入来重建 3D 环境,随着深度学习技术的普及,这些方法取得了显著进展。尽管取得了这些突破,现有的框架仍面临性能瓶颈,并且通常需要大量的激光雷达(LiDAR)标注数据,这限制了它们在不同自动驾驶平台上大规模应用的实际可行性。 本论文对基于视觉的 3D 感知技术的发展作出了多方面的贡献。在第一部分,论文介绍了对单目和立体 3D 物体检测算法的结构性改进。通过将地面参考几何先验信息融入单目检测模型,本研究在单目 3D 检测的基准评估中取得了前所未有的精度。与此同时,本文通过将单目网络中的见解和推理结构融入立体 3D 检测模型,进一步优化了立体检测系统的操作效率。 第二部分专注于基于数据驱动的策略及其在 3D 视觉检测中的实际应用。论文提出了一种新颖的训练方案,结合了带有 2D 或 3D 标签的多种数据集。这种方法不仅通过使用大规模扩展的数据集增强了检测模型,还在实际场景中通过利用仅具有 2D 注释的数据集,使得模型部署更加经济。 最后,论文展示了一个创新的管道,旨在实现自动驾驶场景中的无监督深度估计。大量的实证分析验证了该新提出管道的鲁棒性和有效性。综合来看,这些贡献为基于视觉的 3D 感知技术在自动驾驶应用中的广泛采用奠定了坚实的基础。



成为VIP会员查看完整内容
相关内容
Arxiv
224+阅读 · 2023年4月7日



相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日