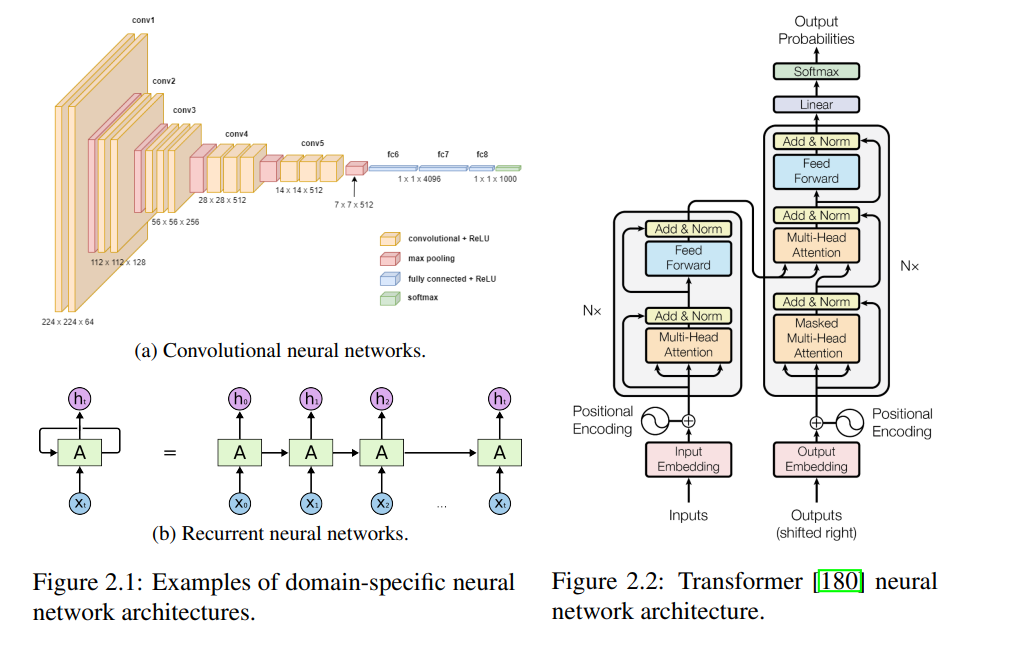
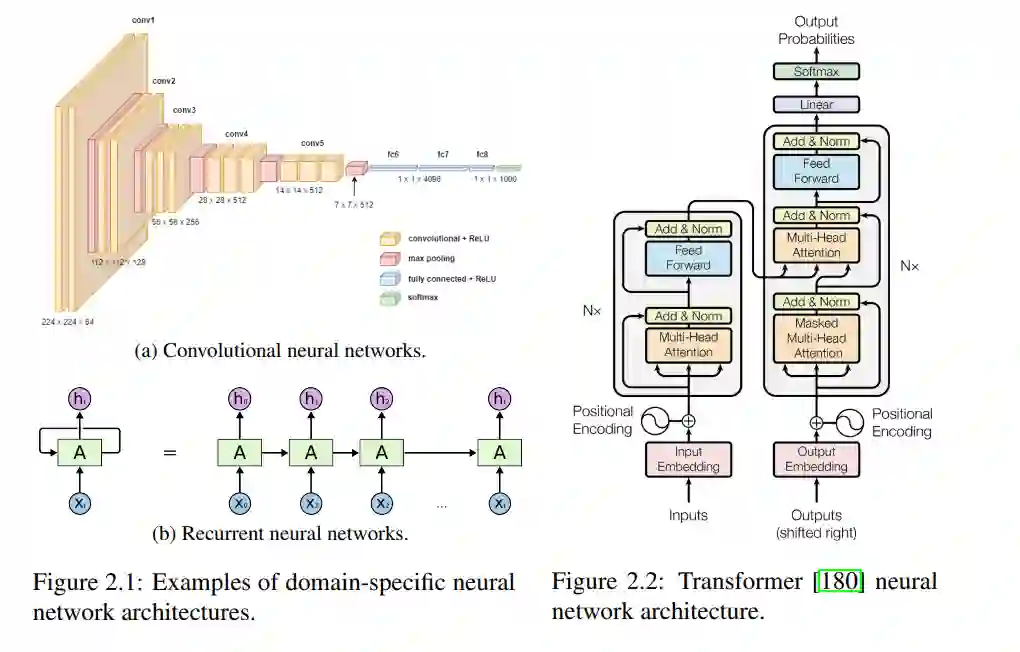
机器学习(Machine Learning, ML)越来越多地用于驱动复杂应用,如大规模网页搜索、内容推荐、自动驾驶汽车以及基于语言的数字助理。近年来,这些系统变得主要依赖数据驱动,通常以端到端学习复杂函数的深度学习模型为基础,这些模型通过大量可用数据进行训练。然而,纯粹的数据驱动特性也使得所学习的解决方案不透明、样本效率低下且脆弱。
为了提高可靠性,生产级解决方案通常采用混合形式的ML系统,这些系统利用深度学习模型的优势,同时通过系统中的其他组件来处理诸如规划、验证、决策逻辑和政策合规等辅助功能。然而,由于这些方法通常是在完全训练后的黑箱深度学习模型上后期应用的,它们在提高系统可靠性和透明性方面的能力有限。 在本论文中,我们研究了如何通过使用具有结构化中间表示(Structured Intermediate Representations, StructIRs)的机器学习模型来构建更可靠且透明的机器学习系统。与神经网络激活等非结构化表示相比,StructIRs 是通过优化明确的目标直接获得的,并且具有结构约束(例如归一化嵌入或可编译代码),同时仍然具有足够的表达能力来支持下游任务。因此,它们通过增加模块化并使建模假设显式化,可以使得所产生的ML系统更加可靠且透明。
我们探讨了StructIRs在三种不同机器学习系统中的作用。在我们的第一个工作中,我们使用由神经网络参数化的简单概率分布来构建一个有效的ML驱动的数据中心存储策略。在第二项工作中,我们展示了将文本生成嵌入到结构良好的向量表示空间中,可以通过简单、可解释的向量运算有效地转换文本的高层属性,如时态和情感。最后,在第三项工作中,我们进行了人类受试者研究,表明基于Bandit的推荐系统背后的平稳性假设在实践中并不成立,强调了验证ML系统背后假设和结构的重要性。