

大型语言模型(LLMs)在处理通用知识任务方面表现出色,但在用户个性化需求方面存在挑战,如理解个人情感、写作风格和偏好。个性化大型语言模型(PLLMs)通过利用个体用户数据,例如用户资料、历史对话、内容和互动,解决了这些问题,以提供在上下文上相关且量身定制的回答,满足每个用户的特定需求。这是一个极具价值的研究课题,因为PLLMs可以显著提升用户满意度,并在对话代理、推荐系统、情感识别、医疗助手等领域具有广泛的应用。 本综述从三个技术角度回顾了个性化大型语言模型(PLLMs)的最新进展:针对个性化上下文的提示设计(输入层)、个性化适配器的微调(模型层)以及个性化偏好的对齐(目标层)。为了提供更深入的洞察,我们还讨论了当前的局限性,并概述了未来研究的几个有前景的方向。有关本综述的最新信息,请访问Github仓库。
1 引言
近年来,像GPT、PaLM、LLaMA、DeepSeek及其变种等大型语言模型(LLMs)取得了显著进展。这些模型展现了卓越的多功能性,在各种自然语言处理任务中取得了最先进的表现,包括问答、推理和机器翻译 [Zhao et al., 2023],且几乎不需要针对特定任务的适应。
个性化LLMs(PLLMs)的必要性
虽然LLMs在通用知识和多领域推理方面表现出色,但它们缺乏个性化,导致在用户特定理解至关重要的场景中遇到挑战。例如,对话代理需要适应用户的偏好语气,并结合过去的互动,提供相关的个性化回应。随着LLMs的发展,集成个性化能力已成为推动人机交互在多个领域发展的一个有前景的方向。 技术挑战
尽管个性化LLMs具有巨大潜力,但个性化过程中仍面临若干挑战。这些挑战包括如何高效地表示和整合多样化的用户数据、解决隐私问题、管理长期用户记忆、适应用户的多样化需求以及应对用户行为的变化 [Salemi et al., 2023]。此外,实现个性化通常需要在准确性和效率之间找到平衡,同时解决偏见问题并保持生成结果的公平性。 贡献
尽管个性化LLMs日益受到关注,但该领域缺乏一篇系统性的综述文章来整合最新的研究进展。本文旨在填补这一空白,通过系统地组织现有的PLLMs研究,并提供对其方法论和未来方向的深入见解。本文的贡献可以总结如下:(1)结构化分类法:我们提出了一种全面的分类法,从技术角度对现有的PLLMs构建方法进行分析。(2)全面综述:我们系统地回顾了PLLMs的最先进方法,分析了各个方法的特点和优缺点。
2 预备知识
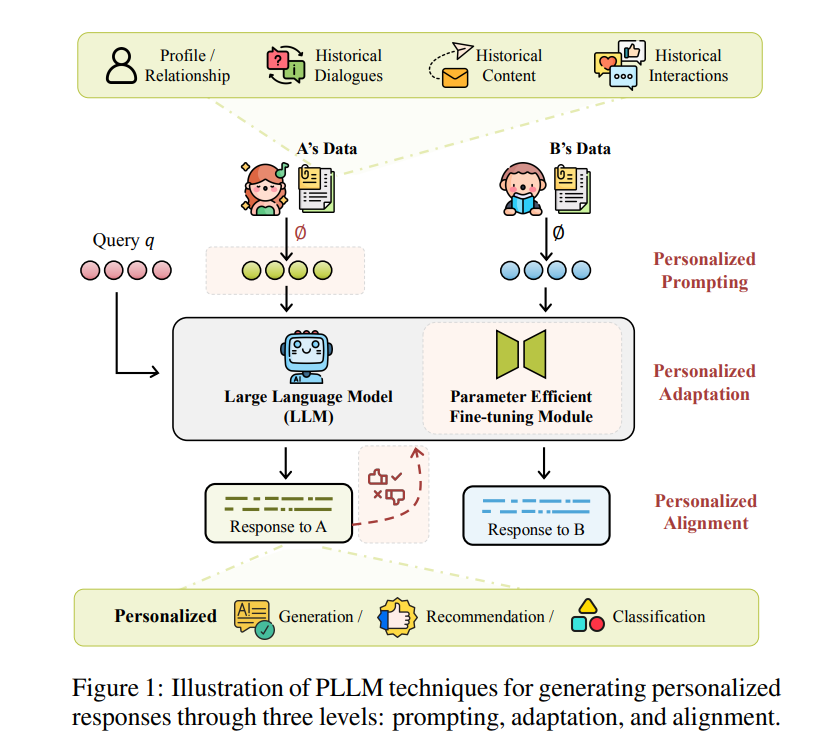
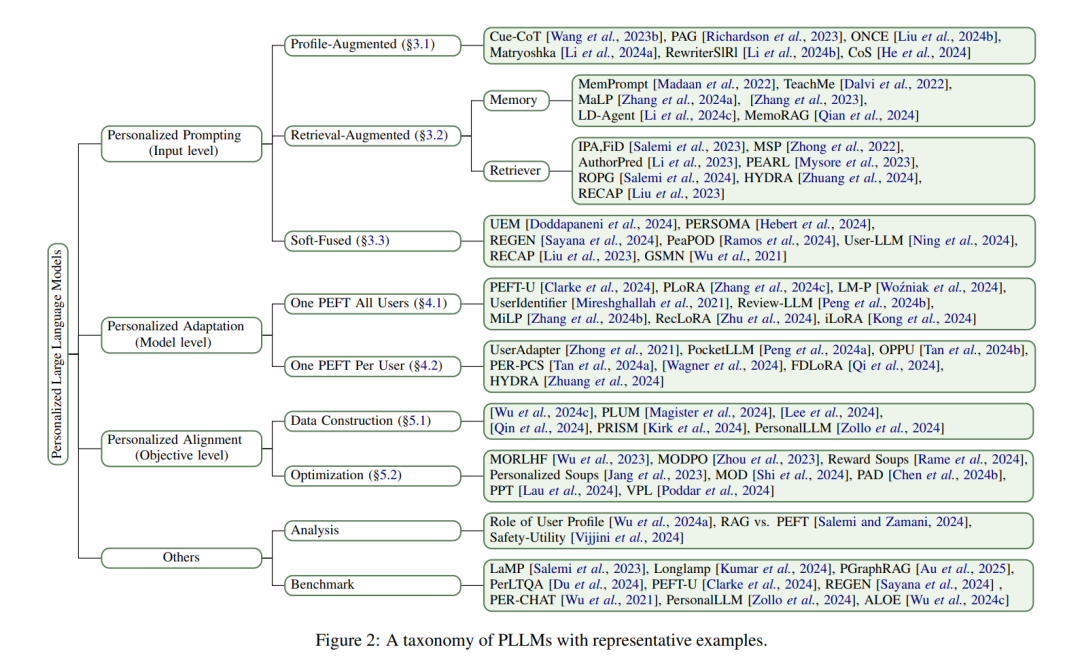
大语言模型 大语言模型(LLMs)通常指利用Transformer架构并配备数十亿参数的模型,这些模型在数万亿文本标记上进行训练。这些模型在自然语言理解和生成任务中表现出显著改进,越来越多地证明其在辅助人类活动中的益处。在本报告中,我们主要关注自回归LLMs,它们基于两种主要架构:仅解码器模型和编码器-解码器模型。编码器-解码器模型如Flan-T5和ChatGLM通过编码器分析输入以获取语义表示,使其在语言理解和生成方面表现出色。仅解码器LLMs专注于从左到右的生成,通过预测序列中的下一个标记,许多实例在此范式下实现了指令跟随和推理等高级能力的突破。 然而,这些模型通常在通用数据上进行预训练,缺乏对特定用户信息的理解。因此,它们无法生成适应用户独特品味、偏好和期望的响应,限制了其在需要用户特定适配的个性化应用中的有效性。 问题陈述 个性化大语言模型(PLLMs)生成与用户风格和期望一致的响应,为不同用户提供多样化的答案。PLLMs定义为不仅基于输入查询qq,还基于用户uu的个性化数据CuCu生成响应的LLMs。其目标是预测给定查询qq和个性化上下文CuCu的最可能响应序列yy,即:y=argmaxyP(y∣q,Cu)y=argmaxyP(y∣q,Cu)。个性化数据CuCu可能包含用户偏好、历史、上下文和其他用户特定属性的信息。这些信息可以包括(图1): 档案/关系:用户档案,包括属性(如姓名、性别、职业)和关系(如朋友、家人),例如Cu={A,18,学生,朋友{B,C,D}… }Cu={A,18,学生,朋友{B,C,D}…}。 历史对话:历史对话,如用户uu与LLM互动的问答对(例如Cu={(q0,a0),(q1,a1),…,(qi,ai)}Cu={(q0,a0),(q1,a1),…,(qi,ai)}),其中每个qiqi是查询,aiai是相应的答案。 历史内容:包括用户uu的文档、先前评论、评论或反馈。例如,Cu={1喜欢Avtar因为…,… }Cu={1喜欢Avtar因为…,…}。 历史互动:包括用户uu的历史互动、偏好、评分。例如,Cu={指环王:5,星际穿越:3… }Cu={指环王:5,星际穿越:3…}。 通过整合个性化数据,PLLMs增强了传统LLMs,改进了响应生成、推荐和分类任务。 注意,我们的报告与角色扮演相关的LLM个性化有显著不同。虽然角色扮演侧重于在对话中模仿角色,但本报告中的PLLMs侧重于理解用户的上下文和偏好,以满足其特定需求。与强调广泛类别的[29]相比,我们的工作提供了增强PLLM效率和性能技术的系统性分析,并提供了更详细的技术分类。 提出的分类法 我们提出了一个从技术角度出发的分类法(如图1和图2所示),将个性化大语言模型(PLLMs)的方法分为三个主要层面:(1)输入层面:个性化提示侧重于处理用户特定数据并将其注入模型。(2)模型层面:个性化适配强调设计框架以高效微调或适配模型参数以实现个性化。(3)目标层面:个性化对齐旨在优化模型行为以有效对齐用户偏好。由于篇幅限制,分析论文、数据集和基准测试总结在Github Repo中。 3 个性化提示
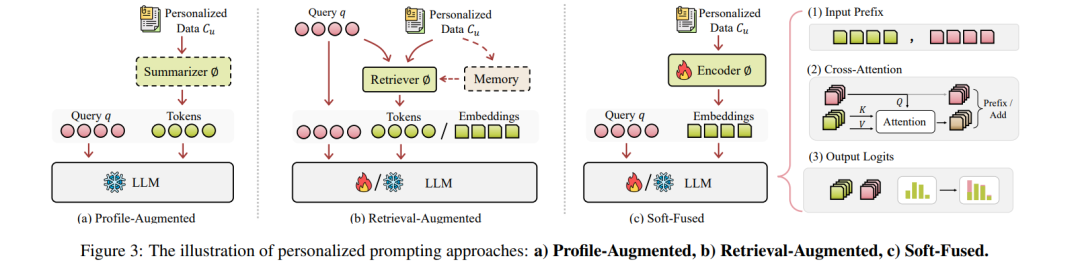
提示工程作为用户与LLMs之间的交互桥梁。在本报告中,提示涉及使用各种技术引导LLM生成期望的输出,从传统文本提示到软嵌入等高级方法。软嵌入不仅可以通过输入扩展,还可以通过交叉注意力或调整输出logits实现,从而实现更灵活和上下文敏感的响应。 该框架可以表示为,对于每个用户uu:
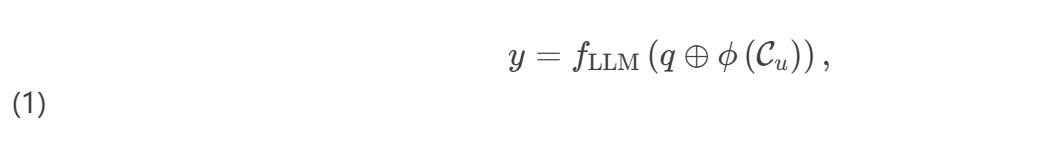
其中,fLLMfLLM是生成响应的LLM模型;ϕϕ是从用户个人上下文CuCu中提取相关上下文的函数;⊕⊕表示将查询qq和相关个性化上下文ϕ(Cu)ϕ(Cu)结合的组合运算符,为LLM生成丰富的信息。 档案增强提示 档案增强提示方法明确利用总结的用户偏好和档案的自然语言来增强LLMs的输入(ϕϕ是总结器模型)。图3(a)展示了该方法的示意图。 非调优总结器:冻结的LLM可以直接用作总结器,以总结用户档案,因其具有强大的语言理解能力,即ϕ(Cu)=fLLM(Cu)ϕ(Cu)=fLLM(Cu)。例如,_Cue-CoT_使用思维链提示进行个性化档案增强,利用LLMs从历史对话中提取和总结用户状态(如情感、个性和心理)。_PAG_利用指令调优的LLMs基于历史内容预总结用户档案。这些总结离线存储,从而在满足运行时约束的同时实现高效的个性化响应生成。_ONCE_提示闭源LLMs从用户的浏览历史中总结主题和兴趣区域,增强个性化推荐。 调优总结器:黑箱LLMs对输入噪声(如离题总结)敏感,难以提取相关信息。因此,训练总结器以适应用户偏好和风格至关重要。_Matryoshka_使用白箱LLM总结用户历史,类似于PAG,但微调总结器而不是生成器LLM。_RewriterSIRI_重写查询qq而不是连接总结,通过监督学习和强化学习进行优化。 _CoS_是一个特殊情况,假设一个简短的用户档案ϕ(Cu)ϕ(Cu),并通过比较有和没有档案的输出概率来放大其在LLM响应生成中的影响,从而在不微调的情况下调整个性化。 检索增强提示 检索增强提示[8, 10, 11]擅长从用户数据中提取最相关的记录以增强PLLMs(见图3(b))。由于用户数据的复杂性和体量,许多方法使用额外的记忆来实现更有效的检索。常见的检索器包括稀疏检索器(如BM25 [21])和密集检索器(如Faiss [23], Contriever [24])。这些方法有效地管理了LLM上下文限制内不断增长的用户数据量,通过整合用户个性化数据中的关键证据来提高相关性和个性化。 3.2.1 个性化记忆构建 这部分设计了保留和更新记忆的机制,以实现高效检索相关信息。 非参数记忆:此类记忆维护一个基于标记的数据库,以原始标记形式存储和检索信息,而不使用参数化向量表示。例如,_MemPrompt_和_TeachMe_维护基于字典的反馈记忆(错误和用户反馈的键值对)。MemPrompt侧重于基于提示的改进,而TeachMe强调通过动态记忆进行持续学习,随时间适应。_Mal.P_进一步整合了多种记忆类型,利用工作记忆进行即时处理,短期记忆(STM)进行快速访问,长期记忆(LTM)存储关键知识。 参数记忆:最近的研究将个性化用户数据参数化并投影到可学习空间中,参数记忆过滤冗余上下文以减少噪声。例如,_LD-Agent_维护具有独立短期和长期库的记忆,将长期事件编码为通过可调模块精炼的参数向量表示,并通过基于嵌入的机制进行检索。_MemoRAG_采用不同的方法,利用轻量级LLM作为记忆来学习用户个性化数据。它不维护用于检索的向量数据库,而是生成一系列标记作为草案以进一步指导检索器,提供更动态和灵活的检索增强方法。 3.2.2 个性化记忆检索 个性化检索器设计的关键挑战在于选择不仅相关而且具有代表性的个性化数据用于下游任务。_LaMP_研究通过两种机制(提示内增强(IPA)和解码器内融合(FiD))检索的个性化信息如何影响大语言模型(LLMs)的响应。_PEARL_和_ROPG_同样旨在通过个性化生成校准指标增强检索器,提高检索文档的个性化和文本质量。同时,_HYDRA_训练一个重排序器,从顶部检索的历史记录中优先选择最相关的信息以增强个性化。 软融合提示 软提示与档案增强提示不同,它将个性化数据压缩为软嵌入,而不是将其总结为离散标记。这些嵌入由用户特征编码器ϕϕ生成。 在本报告中,我们概括了软提示的概念,表明软嵌入不仅可以通过输入集成,还可以通过交叉注意力或调整输出logits集成,从而实现更灵活和上下文敏感的响应(见图3(c))。 输入前缀:软提示作为输入前缀,专注于嵌入级别,通过将查询嵌入与软嵌入连接,通常应用于推荐任务。_UEM_是一个用户嵌入模块(变换器网络),生成基于用户个性化数据的软提示。_PERSONA_通过采用重采样增强UEM,根据相关性和重要性选择用户互动的子集。_REGEN_通过协作过滤和项目描述结合用户-项目互动的项目嵌入,使用软提示适配器生成上下文个性化的响应。_PcaPOD_通过将用户偏好提炼为有限的一组可学习的动态加权提示来个性化软提示。与之前提到的方法不同,这些方法侧重于直接嵌入用户互动或重采样相关数据,PcaPOD通过加权共享提示集来适应用户兴趣。 交叉注意力:交叉注意力使模型能够通过允许其关注个性化数据和查询来处理和整合多个输入源。_User-LLM_使用自回归用户编码器通过自监督学习将历史互动转换为嵌入,然后通过交叉注意力集成。该系统采用联合训练来优化检索器和生成器以获得更好的性能。_RECAP_利用为对话域设计的层次变换器检索器获取个性化信息。该信息通过上下文感知前缀编码器集成到响应生成中,提高了模型生成个性化、上下文相关响应的能力。 输出Logits:_GSMN_从个性化数据中检索相关信息,将其编码为软嵌入,并与查询向量在注意力中使用。之后,生成的嵌入与LLM生成的嵌入连接,修改最终logits以生成更个性化和上下文相关的响应。 讨论 三种提示方法各有优缺点:1)档案增强提示通过压缩历史数据提高效率,但存在信息丢失和个性化降低的风险。2)检索增强提示提供丰富的上下文感知输入,适用于长期记忆,但可能受计算限制和无关数据检索的影响。3)软提示高效嵌入用户特定信息,捕捉语义细微差别而不冗余,但仅限于黑箱模型,缺乏明确的用户偏好分析。总体而言,基于提示的方法高效且适应性强,能够以最小的计算开销实现动态个性化。然而,它们缺乏更深入的个性化分析,因为它们依赖于预定义的提示结构来注入用户特定信息,并且由于提示范围狭窄,访问全局知识的能力有限。 4 个性化适配
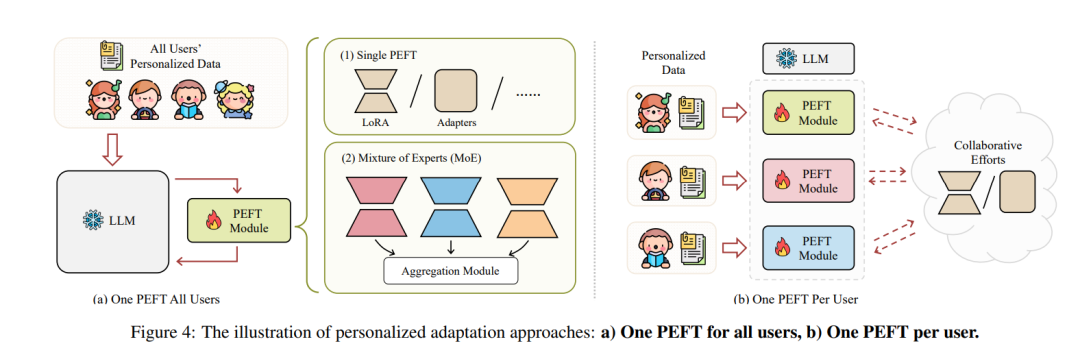
PLLMs需要在微调的深度适应性和提示的效率之间取得平衡。因此,需要专门为PLLMs设计的方法,利用参数高效微调方法(PEFT),如LoRA [Hu et al., 2021, Yang et al., 2024], IA3 [Liu et al., 2022]等(见图4)。 一个PEFT适用于所有用户 该方法使用共享的PEFT模块对所有用户的数据进行训练,消除了每个用户单独模块的需求。共享模块的架构可以进一步分类。 单一PEFT:_PLoRA_和_LMP_利用LoRA进行LLM的PEFT,分别通过用户嵌入和用户ID注入个性化信息。PLoRA进一步扩展并支持冷启动场景的在线训练和预测。_UserIdentifier_使用静态、不可训练的用户标识符来调节模型对用户特定信息的条件,避免了可训练用户特定参数的需求,降低了训练成本。_Review-LLM_将用户的历史行为和评分聚合到提示中以引导情感,并利用LoRA进行高效微调。然而,这些方法依赖于具有固定配置的单一架构(如隐藏大小、插入层),使其无法存储和激活多样化的个性化信息[Zhou et al., 2024]。为了解决这个问题,_MiLP_利用贝叶斯优化策略自动识别应用多个LoRA模块的最佳配置,从而实现高效和灵活的个性化。 专家混合(MoE):几种方法使用LoRA模块,但所有用户使用静态配置。这种缺乏参数个性化限制了适应用户动态和偏好变化的能力,可能导致次优性能[Cai et al., 2024]。_RecLoRA_通过维护一组并行、独立的LoRA权重并采用软路由方法聚合元LoRA权重来解决这一限制,从而实现更个性化和自适应的结果。类似地,_iLoRA_创建了一组多样化的专家(LoRA)以捕捉用户偏好的特定方面,并生成动态专家参与权重以适应用户特定行为。 共享PEFT方法依赖于集中式方法,其中用户特定数据被编码到集中式LLMs的共享适配器中。这限制了模型提供深度个性化体验的能力。此外,使用集中式模型通常要求用户与服务提供商共享个人数据,引发了对这些数据的存储、使用和保护的担忧。

每个用户一个PEFT
为每个用户配备用户特定的PEFT模块使LLM部署更加个性化,同时保护数据隐私。然而,挑战在于确保在资源有限的环境中高效运行,因为用户可能缺乏足够的本地资源来执行微调。 无协作:此类别中适配器之间或学习过程中没有协作或协调。_UserAdapter_通过前缀调优个性化模型,为每个用户微调唯一的前缀向量,同时保持底层变换器模型共享和冻结。_PocketLLM_利用基于MeZo [Malladi et al., 2023]的无导数优化方法,在内存受限的移动设备上微调LLMs。_OPPU_为每个用户配备一个LoRA模块。 协作努力:没有协作的“每个用户一个PEFT”范式在计算和存储方面非常密集,特别是对于大型用户群。此外,个人拥有的PEFTs阻碍了社区价值,因为个人模型无法轻松共享知识或从协作改进中受益。_PER-PCS_通过跨用户共享一小部分PEFT参数实现高效和协作的PLLMs。它首先将PEFT参数划分为可重用的部分,并存储在共享池中。对于每个目标用户,从其他用户自回归选择部分,确保可扩展性、效率和个性化适配,而无需额外训练。 另一种高效的协作策略基于联邦学习(FL)框架。例如,Wagner et al.[2024]引入了用于设备上LLM微调的FL框架,使用策略聚合LoRA模型参数并高效处理数据异质性,优于纯本地微调。FDLoRA_引入了一个个性化的FL框架,使用双LoRA模块捕捉个性化和全局知识。它仅与中央服务器共享全局LoRA参数,并通过自适应融合结合它们,在最小化通信和计算成本的同时提高性能。 还有其他框架可以探索,例如_HYDRA,它也采用基础模型来学习共享知识。然而,与联邦学习相比,它为每个个体用户分配不同的头以提取个性化信息。 讨论 微调方法通过修改大量模型参数实现深度个性化,而参数高效微调方法(如前缀向量或适配器)在保持高个性化水平的同时降低了计算成本和内存需求。这些方法通过针对特定用户需求定制模型来提高任务适应性,增强情感分析和推荐等任务的性能。它们还提供了灵活性,允许用户特定调整,同时利用预训练知识。然而,它们仍然面临过拟合的风险,特别是在有限或嘈杂的用户数据情况下,这可能影响对新用户或多样化用户的泛化和性能。 5. 个性化对齐
个性化对齐技术 [Bai et al., 2022; Rafailov et al., 2024] 通常旨在优化大型语言模型(LLMs),使其符合人类的通用偏好。然而,现实中,个体在语言风格、知识深度、价值观等方面对LLM回答的偏好可能存在显著差异。个性化对齐则力图进一步满足个体用户的独特偏好,超越通用的偏好。个性化对齐面临的一大挑战是构建高质量的用户特定偏好数据集,这比通用对齐数据集更为复杂,原因在于数据的稀缺性。第二个挑战来自于需要改进传统的基于强化学习的人类反馈(RLHF)框架 [Ouyang et al., 2022],以处理用户偏好的多样化问题,这对于整合个性化偏好而不妥协效率和性能至关重要。
5.1 个性化对齐数据构建
高质量的数据构建对于学习个性化大型语言模型(PLLMs)至关重要,主要涉及通过与LLM的交互生成自我生成的数据。Wu 等 [2024c] 构建了一个数据集,用于将LLM与个体偏好对齐,该数据集通过初步创建一个包含3,310个用户角色池,并通过迭代自我生成和过滤进行扩展。这种方法与PLUM [Magister et al., 2024] 相似,后者通过多轮对话树模拟动态交互,使得LLM能够推断并适应用户的偏好。为了让LLM能够在不重新训练的情况下适应个体用户的偏好,Lee 等 [2024] 使用了多样化的系统消息作为元指令来指导模型的行为。为此,创建了MULTIFACETED COLLECTION数据集,其中包含197,000条系统消息,代表了广泛的用户价值观。为了支持边缘设备上的实时隐私保护个性化,并解决数据隐私、存储有限和最小化用户干扰的问题,Qin 等 [2024] 提出了一个自监督方法,该方法能够高效地选择并综合重要的用户数据,从而在最小化用户交互的情况下改善模型适应性。 研究工作也越来越集中于开发能够评估模型理解个性化偏好的数据集。Kirk 等 [2024] 引入了PRISM Alignment Dataset,该数据集将来自75个国家的1,500名参与者的社会人口统计信息和偏好映射到他们与21个LLM的实时交互反馈中,重点关注关于有争议话题的主观和多文化视角。PersonalLLM [Zollo 等,2024] 提出了一个新型的个性化测试数据库,它策划了开放式提示和多个高质量的回应,以模拟用户之间的多样化潜在偏好。该方法通过从预训练的奖励模型生成模拟用户群体,解决了个性化中的数据稀缺问题。
5.2 个性化对齐优化
个性化偏好对齐通常被建模为一个多目标强化学习(MORL)问题,其中个性化偏好是由多个偏好维度的用户特定组合来决定的。基于此,典型的对齐范式包括使用从多个奖励模型派生的个性化奖励来指导LLM策略的训练阶段,以实现个性化目标。MORLHF [Wu 等,2023] 为每个偏好维度分别训练奖励模型,并使用邻近策略优化(PPO)重新训练策略语言模型,指导模型通过多个奖励模型的线性组合。这种方法允许重用标准的RLHF管道。 MODPO [Zhou 等,2023] 引入了一种新颖的无强化学习(RL-free)算法,扩展了直接偏好优化(DPO),以管理多个对齐目标。它将线性标量化直接集成到奖励建模过程中,使得通过简单的基于边际的交叉熵损失来训练语言模型,作为隐式的集体奖励函数。 另一种MORL策略是在解码阶段考虑多个训练好的策略LLM的即席组合,以实现个性化。Personalized Soups [Jang 等,2023] 和Reward Soups [Rame 等,2024] 通过首先独立训练多个具有不同偏好的策略模型,然后在推理阶段合并它们的参数来解决个性化人类反馈中的RL挑战。两种方法都允许根据用户偏好动态加权网络,增强模型对齐并减少奖励的误差。此外,策略LLM的个性化融合不仅可以通过参数合并来实现,也可以通过模型集成来实现。MOD [Shi 等,2024] 从所有基础模型的线性组合中输出下一个令牌,允许通过组合它们的预测来精确控制不同目标,而无需重新训练。与参数合并基准相比,该方法显示出了显著的效果。PAD [Chen 等,2024b] 利用个性化奖励建模策略生成令牌级别的个性化奖励,并用这些奖励来指导解码过程,从而动态地调整基础模型的预测,以适应个体偏好。图5可视化了上述典型的MORL方法,用于个性化对齐。 还有一些新兴的个性化对齐研究,超越了“多目标”范式。PPT [Lau 等,2024] 通过生成每个用户提示的两个潜在回答,要求用户对其进行排名,并将该反馈融入到模型的上下文中,以动态适应用户的个性化偏好,从而解锁了上下文学习在可扩展性和高效性上的潜力。VPL [Poddar 等,2024] 利用变分推断框架,通过用户特定的潜在变量来捕捉多样化的人类偏好。从少量偏好注释推断用户特定的潜在分布,能够以更高的数据效率实现更准确的个性化奖励建模。
5.3 讨论
当前主流的个性化对齐技术主要将个性化建模为多目标强化学习问题,其中通过经典的RLHF框架在策略LLM的训练阶段或通过参数合并或模型集成在解码阶段考虑个性化用户偏好。通常,这些方法限于少数(例如三个)预定义的偏好维度,并通过文本用户偏好提示来表示。然而,在现实场景中,可能存在大量个性化用户,并且他们的偏好向量可能并不完全已知,仅能访问到他们的交互历史。因此,开发更现实的对齐基准,以有效评估这些技术,是未来研究的一个关键方向。6. 未来方向尽管个性化大型语言模型(PLLMs)近年来取得了显著进展,但仍然面临许多挑战和机遇。本节将讨论一些关键的局限性和未来研究的有前景的方向。复杂的用户数据尽管当前的方法有效处理了基本的用户偏好,处理复杂的、多源的用户数据仍然是一个显著的挑战。例如,使用图结构表示用户关系的方法仍然局限于检索增强 [Du et al., 2024]。如何有效利用这些复杂的用户信息来微调LLM参数仍然是一个巨大的挑战。大多数方法主要关注文本数据,而针对多模态数据(如图像、视频、音频)的个性化基础模型仍然没有得到充分探索,尽管这些数据对现实世界的部署和应用至关重要 [Wu et al., 2024b; Pi et al., 2024]。边缘计算边缘计算中的一个关键挑战是如何在资源有限的设备(如手机)上高效地更新模型,这些设备的存储和计算资源有限。例如,微调可以提供更深层次的个性化,但它需要大量资源,并且难以扩展,尤其是在实时应用中。平衡资源和个性化需求是非常重要的。一种潜在的解决方案是为边缘设备构建个性化的小型模型 [Lu et al., 2024],利用量化和蒸馏等技术。边缘-云协作在现实世界场景中部署PLLMs会遇到边缘-云计算环境中的重大挑战。当前利用协作努力的方法通常缺乏云和边缘设备之间的高效同步机制。这突显了探索本地计算与云端处理之间平衡的必要性,尤其是在个性化模型(PLLMs)的部署中 [Tian et al., 2024]。高效适应模型更新当基础LLM参数更新(例如推出新版本时),如何高效地调整每个用户的微调PEFT参数成为一个挑战。考虑到用户数据的庞大量和资源的有限性,重新训练的成本可能非常高昂。未来的研究应该聚焦于高效的策略来更新用户特定的参数,而无需完全重新训练,例如利用增量学习、迁移学习或更具资源效率的微调技术。终身更新鉴于用户行为的多样性,一个关键的挑战是如何防止灾难性遗忘,同时确保长期和短期记忆的高效更新。未来的研究可以探索持续学习 [Wu et al., 2024d] 和知识编辑 [Wang et al., 2024b],以促进用户特定信息的动态更新。信任问题确保用户隐私至关重要,尤其是在使用总结或检索的数据生成个性化响应时。由于资源限制,LLMs无法本地部署,这可能导致隐私泄露的风险。未来的研究可以集中于隐私保护方法,例如联邦学习、安全计算和差分隐私,以保护用户数据 [Yao et al., 2024; Liu et al., 2024a]。7. 结论本文综述了个性化大型语言模型(PLLMs),重点强调了根据个体用户数据量身定制的个性化响应。我们提出了一个结构化的分类法,将现有的方法分为三个关键技术视角:个性化提示(输入层)、个性化适配(模型层)和个性化对齐(目标层),并在每个层次内进一步细分。我们还讨论了当前的局限性,并提出了几个有前景的未来研究方向。我们的工作为推动PLLMs的发展提供了宝贵的见解和框架。
