事件抽取指的是从非结构化文本中提取结构化信息,通常分为两个子任务:事件检测和事件参数抽取(Ahn,2006;Yang等,2019;Xu等,2023;Wang等,2021b;Shi等,2023;Yang等,2023;Wan等,2023;Liu等,2020;Chu等,2023;Peng等,2023;Wang等,2023)。目前的研究主要集中在一般新闻或金融领域,而对军事领域的研究相对较少。然而,军事事件抽取的重要性不容忽视。
军事领域包含大量文档,这些文档中包含丰富的事件信息。从文档中提取军事事件对于情报分析(Santucci,2022;Bang,2016;Freedman,1983;Ivanov,2011)、决策辅助(Skryabina等,2020)和战略规划(Schrodt,2012;Sankar,2023;Lyu,2022)等下游应用至关重要。图1展示了基于军事新闻的事件抽取示例。该军事新闻文档包含六个事件。需要在文档中识别触发器并确定其对应的事件类型,以及相关的参数和对应的角色。例如,在第六句话S06中,需要识别触发器“攻击”(attacking)和事件类型“冲突”(Conflict),此外,还需识别事件的“主体”英国海军(British Naval)、“对象”南斯拉夫的目标(targets in Yugoslavia)和“日期”1999年。
现有的事件抽取研究主要依赖于基于深度神经网络的模型,这些模型对数据的大小和质量有很强的依赖性。因此,高质量训练数据的缺乏显著限制了它们的性能。这些模型大多使用句子级文本进行分析,而句子级事件抽取研究相对成熟(Gao,2021;Hsu等,2021;Huang等,2023a),但这种技术在直接应用于文档级事件抽取任务时表现不佳。这是因为随着文本长度的增加,事件参数往往分散在不同的句子中。此外,现有的大多数事件抽取数据集都面向一般(Li等,2020,2021a)或金融领域(Han等,2022a;Zheng等,2019)。应用于不同语言和领域的数据集的方法的性能往往差异显著。目前,军事事件数据抽取主要依靠人工劳动,导致效率低下、标准不一致和信息不完整等问题。这些挑战使得基于事件的实际应用难以支持。因此,构建一个专门针对军事领域的文档级事件抽取数据集具有重要的实际意义和应用价值。
然而,由于军事领域数据的机密性和敏感性,以及获取事件模式的困难,长期以来用于该领域事件抽取任务的数据集存在缺口,这是导致军事事件抽取发展严重滞后于主流研究的主要原因。
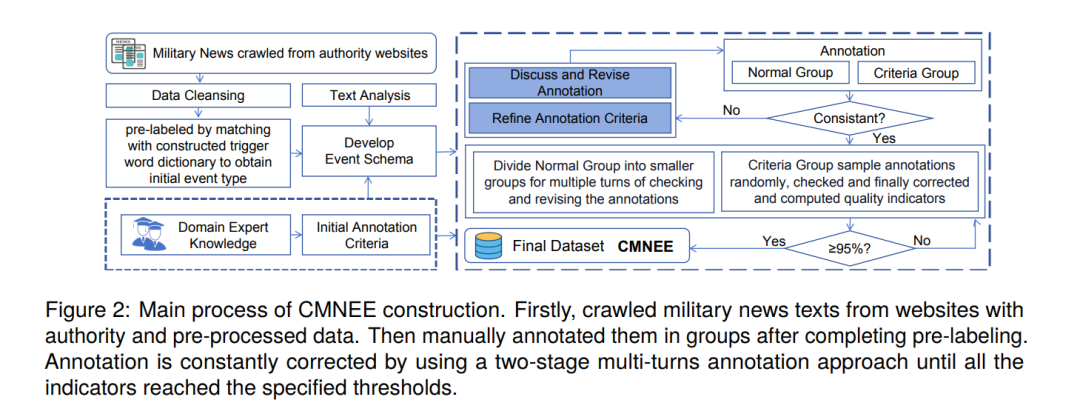
为了填补这一空白并缓解相关问题,我们提出了一个大规模的文档级开源中国军事新闻事件抽取数据集(CMNEE),该数据集涉及环球网、中国军网、新浪军事和百度百科等权威网站的语料库。获取的军事新闻文本本身是可靠的。在基于新闻进行数据注释的过程中,首先通过与构建的触发器词典匹配,结合领域专家的知识和相关新闻的分析,对文档中可能包含的事件类型进行预标注,形成事件模式。基于事件模式并参照数据注释标准,采用两阶段多轮次方式完成注释。注释要求对预标注结果进行人工判断,标注触发器和事件类型、事件参数及对应的参数角色。此外,考虑到事件参数抽取表现不佳的原因之一是识别出的参数是共指参数而非数据集中标注的参数(Lu等,2023),我们还对文本中涉及的共指参数进行了标注。设计了质量指标来评估CMNEE。注释和数据注释标准不断被修正,直到所有指标达到指定的阈值。
CMNEE目前是唯一一个针对军事领域文档级事件抽取任务的数据集。为了更好地评估CMNEE,我们实现了几种先进的模型并进行了系统评估。实验结果表明,CMNEE具有一些需要克服的独特挑战,值得进一步研究。我们希望CMNEE能够促进相关研究,吸引更多对军事领域事件抽取的关注。