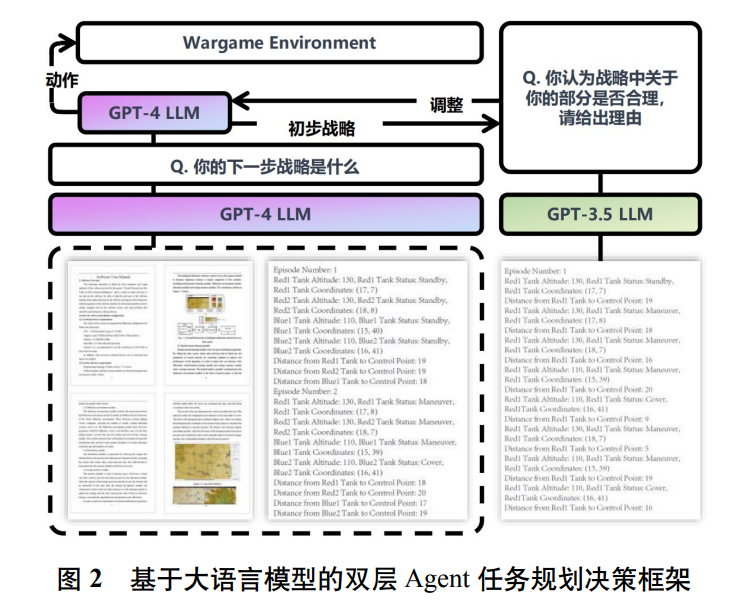
ChatGPT所代表的大型语言模型对AI领域产生了颠覆性影响。但它主要关注自然语言处理、语音识别、机器学习和自然语言理解。这篇论文创新地将大型语言模型应用于智能决策领域,将大型语言模型置于决策中心,并构建以大型语言模型为核心的Agent体系结构。基于此,进一步提出了双层Agent任务规划,通过自然语言的交互,发出和执行决策指令,并通过兵棋推演模拟环境进行仿真验证。通过兵棋对抗模拟实验,发现大型语言模型的智能决策能力明显优于常用的强化学习AI,智能性、可理解性都更强。通过实验证明,大型语言模型的智能与Prompt密切相关。这项工作还将大型语言模型从以往的人机交互领域拓展到智能决策领域,对智能决策的发展具有重要的参考价值和意义。 自 ChatGPT 于 2022 年 11 月 30 日正式推出以 来,它迅速成为最受欢迎的智能 Chatbot 之一[1-2]。自 问世以来,ChatGPT 已经在多个领域得到应用,如 代码纠正[3]、公共卫生和全球变暖[4-5]。2023 年 7 月, OpenAI 发布了 Code Interpreter 插件,进一步增强了ChatGPT 的数据解析能力,并解决了大语言模型在 数学和语言领域的固有缺点。这些发展为改进智能 决策推演领域的 AI 智能性和泛化性提供了新的启 发,即利用 ChatGPT 自生成的 AI 在兵棋推演中做 出智能决策。 尽管基于知识驱动的 AI 的发展和应用是智能 兵棋领域的起点,但近年来数据驱动 AI[6]、知识和 数据混合驱动 AI[7],逐渐成为研究的热点,其中强 化学习 AI 取得了一系列突破。在知识和数据混合驱 动 AI 方面,刘满等人[7] 设计了一个平衡规则和数 据的兵棋决策框架。在强化学习和深度学习 AI 领域 中,针对强化学习,张健等人[8] 提出一种基于 QMC 的蒙特卡洛聚类扩展算法,以解决多智能体决策问 题中的高计算复杂度和内存占用大的挑战。南京理 工大学的李琛团队[9] 设计了一种基于 Actor-Critic 框 架的多 Agent 决策方法,并取得了出色的智能表现。 Chen 等人[10] 将人类经验引入指导智能体,提出了 基于主动强化学习的目标分类人机交互智能体,以 提高分类准确性。后续该团队[11]] 提出了一种深度学 习架构,用于处理不完整信息的战争游戏中的意图 识别,提高识别稳定性,和准确度。徐佳乐、张海东 等人[12] 设计了一个基于卷积神经网络的策略学习模 型,以提高战局预测的准确性。Sun 等人[13] 创新性 地将强化学习、深度学习和自然语言处理技术应用 于游戏 AI,实现了高准确度的语义文本输出。Xu 团 队[14] 构建了一个用于多智能体不完整信息游戏的人 机博弈平台,庙算战争游戏平台,用于智能体的训 练和评估。腾讯 AI 实验室[15-16] 采用深度强化学习 在《王者荣耀》游戏中实现了游戏对抗,并战胜了 职业选手。Dong 等人[17] 提出了一种改进方法,通过 利用专家演示以提高深度强化学习的学习效率。总 之,通过深度学习、强化学习和智能兵棋的深度结 合,Agent 的智能水平不断提高[18-21]。 尽管基于规则的 AI 无需长时间的训练,但由于 受规则限制,其智能水平的上限难以突破;而数据 驱动型 AI 和强化学习型 AI 通过处理大量数据并采 用强化学习算法来提高智能性和灵活性,但它们的 可解释性较差,难以在场景和关键点变化下实现模 型迁移[22-25]。因此,在智能兵棋领域提升 AI 的智能 性和可理解能力成为下一步研究的重点。 此外,对抗性游戏的决策是复杂且连续的。为了 使决策更具备更强的智能性和泛化性,本文着重介 绍了一种基于大语言模型的自生成 AI 兵棋架构。构 建了一个涉及战略 Agent 和战术 Agent 互相交互的 决策机制,该机制也可以拓展到涉及多个生成 Agent 交互的决策机制,通过该机制生成具备可信、可解 释的兵棋对抗智能决策。 本文的核心工作和创新点如下: 1) 自生成的 AI 兵棋架构是以大语言模型为中 心的智能 Agent 体系结构。该架构由多个生成 Agent 组成,每个 Agent 都拥有自己的大语言模型(本文使 用 ChatGPT 作为驱动工具)。这些智能 Agent 可以通 过反射流和记忆流进行通信和合作,共同制定决策。 通过相互对话,它们可以共享信息、分析情况,并基 于对话内容进行推断和决策。 2) 建立一个双层 Agent 任务规划模型,分别面 向战略 Agent 和战术 Agent,以规划兵棋对抗过程中 的任务。战略 Agent 描述了所有当前 Agent 观察到 的具体情况,规划涉及基于所有观察到的情境信息, 进行任务分配和执行。战术 Agent 仅关注单个 Agent 算子所观察到的情况,并根据战略规划 Agent 执行 相关任务。同时,战术 Agent 也可以根据战略 Agent 发布的提示自行判断并提供反馈。 3) 以兵棋作为实验平台,通过三种推演想定进 行实验验证,实验结果表明,大语言模型的智能决 策能力、稳定性和泛化性明显强于强化学习 AI,而 且其智能性、可理解性都更出色,还发现专门为大 语言模型提供领域专家的先验知识可以显著提高它 们的智能化水平。