文本聚类:从非结构化数据快速获取见解
点击上方
Datartisan数据工匠
可以订阅哦!
自由分组和聚类文本是充分利用文本的重要进步。我们提出了一种用于无监督文本聚类方法的算法,使得业务能够以编程方式将该数据进行存储。
在这两个系列中,我们将探讨文本聚类以及如何从非结构化数据获得见解。第一部分将侧重于动机。第二部分将是实现。
这篇文章是两系列的第一部分,介绍如何使用文本聚类获取非结构化数据的见解。我们将以模块化的方式构建它,以便它可以应用于任何数据集。此外,我们还将重点介绍作为 API 的功能,以便它可以作为随时可用的模型,而不会对现有系统造成任何破坏。
文本聚类:如何从非结构化数据快速获得见解 - 第 1 部分:动机
文本聚类:如何从非结构化数据快速获得见解 - 第 2 部分:实现
如果你心急,你可以在我的 Github 页面 找到完整的项目代码
先睹为快,最终输出如何看起来像:
无可置疑的是,数据是「新石油」。全球各地的组织正在大力建立内部分析功能,来利用未开发的宝藏。然而,由分析计划所带来的可持续的商业利益仍然难以捉摸,组织尚未发现使其全部起效的秘诀。
根据最近的一项研究,大多数组织的分析计划的平均 ROI 仍然是负数。大多数组织正处于成为数据驱动组织的以下阶段之一

处理非结构化数据
当今,组织坐拥大量数据,不幸的是,大部分数据是非结构化的。数据库中存在大量流文本形式的数据。
尽管有许多有助于处理和分析结构化数据的分析技术,但是少有针对分析自然语言数据的技术存在。
解决方案
为了克服这些问题,我们将设计一种无监督的文本聚类方法,使业务能够以编程方式对这些数据进行存储。基于算法对数据的理解,这些数据块本身是基于理解数据的算法以编程方式生成的。这将有助于缓解大量数据,轻松了解更广泛的领域。因此,不要试图理解数百万行,只需理解大约 50 个集群中的顶级关键字。
在此基础上,开创了一个机会世界:
在客户支持模块中,这些集群有助于识别展示项目障碍,并可能成为焦点增加或自动化的主题。
可以总结对特定产品或品牌的客户评价,这将为组织制定路线图
调查数据可以轻松划分
HR 世界中的简历和其他非结构化数据可以毫不费力地查看......
这个列表是无止境的,但重点是一个通用的机器学习算法,可以帮助从大部分非结构化文本的中获得适合形式的见解。
文本聚类:一些理论
该算法首先对自由流文本数据进行一系列变换(在后续部分中详述),然后对变换后的数据的向量化形式执行 k-means 聚类。随后,该算法创建了集群标签,也称为聚类中心,它们代表了这些集群中包含的数据。
该解决方案宣称拥有 end-to-end 的自动化功能,并且通用于任何数据集。
文本聚类算法分为五个阶段:
原始的自由流文本的转换
创建词文件矩阵
TF-IDF(词频 - 逆向文档频率)标准化
使用欧几里得距离的 K-means 聚类
基于聚类中心的自动标记
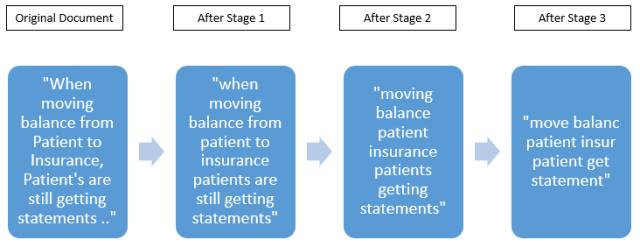
详细说明如下: 流文本数据首先在以下阶段进行处理:
阶段1
删除标点符号
转化为小写
语法标记句子和删除预定的停顿短语(chunk)
删除文档中的数字
剔除任何多余的空格
阶段2
删除一般的英文单词,即:限定词,冠词,连词和其他词性。
阶段3
使用 Porter 干扰算法减少每个单词的词根的文档源。
由下图,很好的解释这些步骤:
一旦语料库中的所有文档如上所述被转换,则创建一个词条文档矩阵,使用 1-gram 向量化算法将文档转换成向量空间(见下文)。其他更复杂的实现包括 n-gram(其中 n 属于适当的整数中)
TF-IDF(词频 - 逆向文档频率)标准化
这是一个可选的步骤,如果文档语料库的变异性很高,语料库中的文档数量非常大(大约数百万),那么可以执行该操作。这种标准化增加了在同一文档中出现多次的词条的重要性,同时降低了许多文档中出现的词条的重要性(这主要是通用词条)。词条权重计算如下:
使用欧几里得距离的 K-means 聚类
发布 TF-IDF 变换后,文档向量通过 K-Means 聚类算法,计算这些文档之间的欧几里德距离,并将附近的文档集中在一起。
基于聚类中心的自动标记
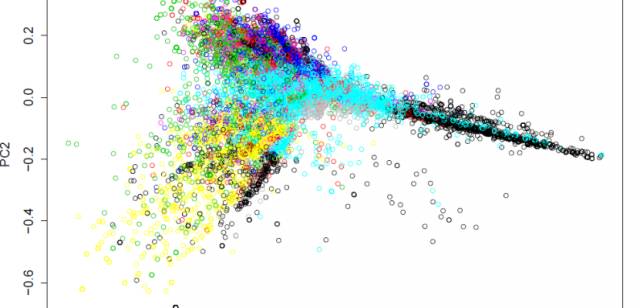
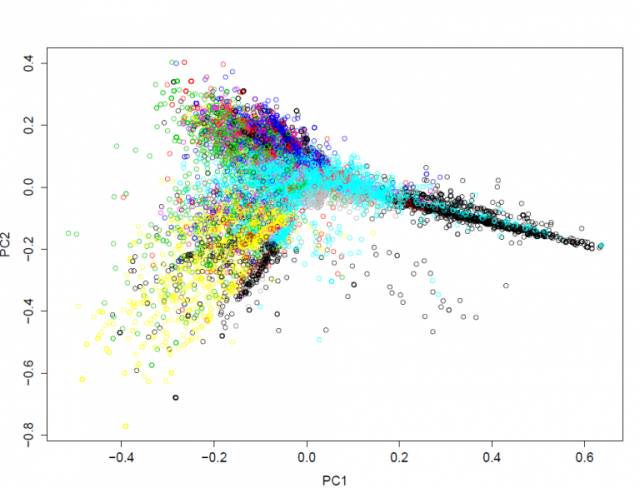
然后,该算法生成集群标签,称为聚类中心,它们表示这些集群中包含的文档。在下图中,聚类和自动生成的标签最好描绘(主成分 1 和 2 分别沿 x 和 y 轴绘制):
为了让越来越多的用户从此解决方案中受益并分析其非结构化文本数据,我创建了一个 RESTful Web 服务,用户可以通过两种方式访问它们:
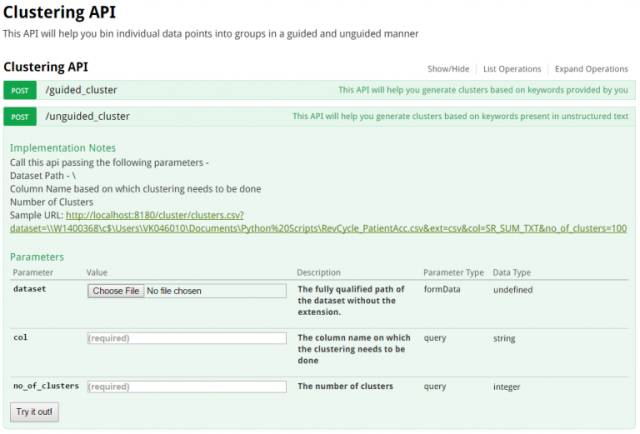
该服务的 Web 界面是 Swagger API 文档的前端。这是 RESTful Web 服务非常受欢迎的解决方案。用户可以通过 Web 界面 URL,上传数据集,指定包含需要分析的自然语言数据的列和所需的集群数,并在几分钟之内输出将显示为包含分析结果的可下载链接。
由于 Web 服务基于 API 的概念,执行分析的计算引擎是一个单独的组件,可扩展,便携,并可通过 RESTful HTTP 从任何其他应用程序访问。
由于所有的计算都是在内存中进行的,所以结果是很快的。
结论
理解和分析自然语言数据的数学方法能证明有助于解锁目前被困在其中的巨大价值和见解,并大大提高了我们对组织及其生态系统的理解。下一篇文章将包含基层实施细节。代码可以在我的 Github 页面中找到。

更多课程和文章尽在微信号
「datartisan数据工匠」




