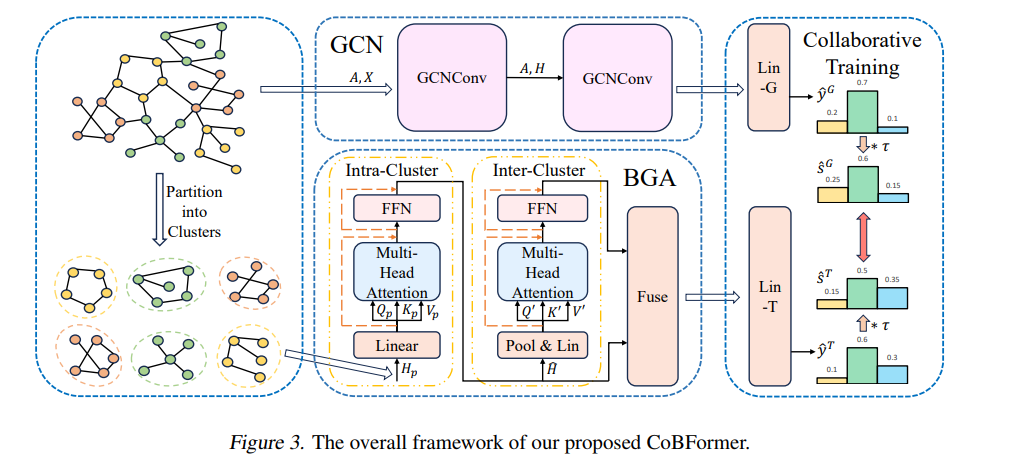
![]() Graph Transformer,由于其强大的全局注意力机制,受到研究者的大量关注并已经成为处理图结构数据的一类重要方法。人们普遍认为,全局注意力机制以全连接图的形式考虑了更广泛的感受野,使得许多人相信 Graph Transformer 可以从所有节点中有效地提取信息。在本文中,我们对这一信念提出了挑战:Graph Transformer 的全局化特性是否总是有益呢?我们首先通过实验证据和理论分析,揭示了 Graph Transformer 中的过全局化问题 (Over-Globalizing Problem),即当前 Graph Transformer 的注意力机制过度关注那些远端节点,而实际上包含了大部分有用信息的近端节点则被相对忽视了。为了缓解这一问题,我们提出了一种新的采用协同训练的两级全局 Graph Transformer 方法 (CoBFormer)。该方法首先将全图划分成不同的簇,然后分别在簇内以及簇间采用注意力机制来捕获解耦的近端节点信息以及全局信息。同时,我们提出以协同训练的方式来促使我们的两级全局注意力模块 (BGA) 与一个图卷积网络模块 (GCN) 相互学习并提升彼此的性能表现。我们通过理论保证了该协同训练方式可以有效提升模型性能的泛化能力。我们在多个数据集上与 SOTA 模型进行充分比较,实验表明了我们的方法的有效性。 论文链接:https://arxiv.org/abs/2405.01102 代码链接:https://github.com/null-xyj/CoBFormer
Graph Transformer,由于其强大的全局注意力机制,受到研究者的大量关注并已经成为处理图结构数据的一类重要方法。人们普遍认为,全局注意力机制以全连接图的形式考虑了更广泛的感受野,使得许多人相信 Graph Transformer 可以从所有节点中有效地提取信息。在本文中,我们对这一信念提出了挑战:Graph Transformer 的全局化特性是否总是有益呢?我们首先通过实验证据和理论分析,揭示了 Graph Transformer 中的过全局化问题 (Over-Globalizing Problem),即当前 Graph Transformer 的注意力机制过度关注那些远端节点,而实际上包含了大部分有用信息的近端节点则被相对忽视了。为了缓解这一问题,我们提出了一种新的采用协同训练的两级全局 Graph Transformer 方法 (CoBFormer)。该方法首先将全图划分成不同的簇,然后分别在簇内以及簇间采用注意力机制来捕获解耦的近端节点信息以及全局信息。同时,我们提出以协同训练的方式来促使我们的两级全局注意力模块 (BGA) 与一个图卷积网络模块 (GCN) 相互学习并提升彼此的性能表现。我们通过理论保证了该协同训练方式可以有效提升模型性能的泛化能力。我们在多个数据集上与 SOTA 模型进行充分比较,实验表明了我们的方法的有效性。 论文链接:https://arxiv.org/abs/2405.01102 代码链接:https://github.com/null-xyj/CoBFormer ![]()