

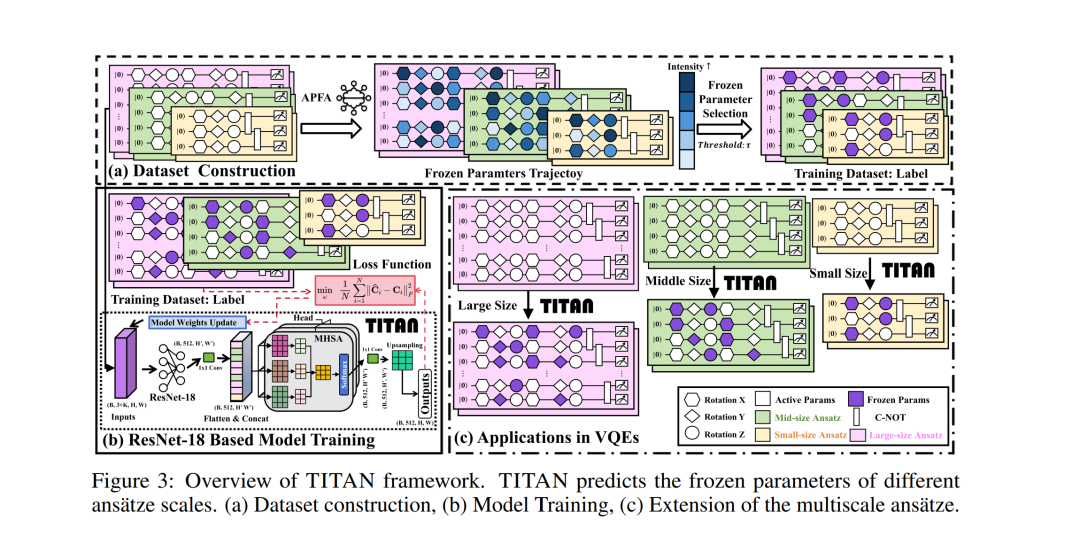
变分量子本征求解器(Variational Quantum Eigensolver,VQE)是利用量子计算机推动量子化学与材料模拟的领先候选方法,但其在处理大规模哈密顿量时的训练效率会迅速恶化。导致这一瓶颈的根本原因有两点:(i)由于不可克隆定理(no-cloning theorem),每步梯度计算中的电路评估次数会随参数数量呈线性增长;(ii)更深的电路会遭遇“贫瘠高原”(barren plateaus, BPs),从而导致测量开销呈指数级增长。为应对这些挑战,我们提出了一个深度学习框架——TITAN,其核心思想是在初始化阶段识别并冻结特定类别哈密顿量下给定参量化形式(ansätze)中的“非活跃”参数,从而在不牺牲精度的前提下减少优化开销。TITAN 的动机源于我们的实证发现:部分参数在训练动态中始终几乎没有影响。其设计结合了两方面:一是理论支撑的数据构造策略,确保每个训练样本都具备信息性并对 BPs 具备鲁棒性;二是自适应神经结构,能够推广到不同规模的参量化形式。
在横场 Ising 模型、Heisenberg 模型及多分子体系(规模达 30 个量子比特)的基准测试中,TITAN 实现了最高 3 倍的收敛加速和 40%–60% 的电路评估减少,同时在估计精度上与当前最先进的基线方法相当或更优。通过主动裁剪参数空间,TITAN 降低了硬件需求,并为利用 VQE 推动量子化学与材料科学的实际应用提供了一条可扩展路径。
成为VIP会员查看完整内容
相关主题