

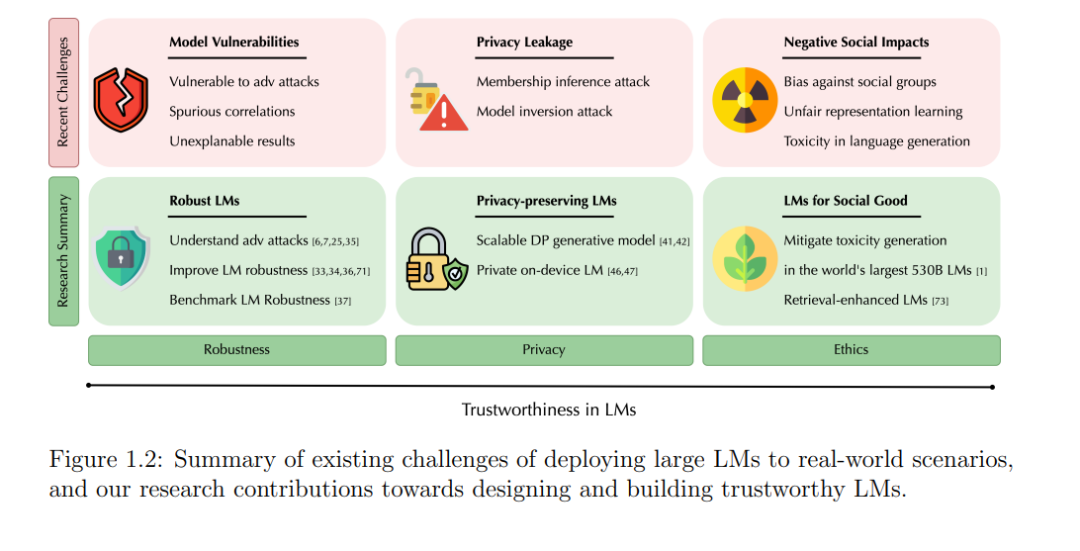
在人工智能的新时代,大型语言模型(LLM)在广泛的自然语言处理(NLP)任务中取得了前所未有的成功,显著提升了对人类语言的理解和生成能力。然而,随着这一显著进展,人们对其安全性和可靠性的担忧也在增加。潜在的错误行为、对抗性攻击的脆弱性、伦理问题以及敏感数据的隐私泄漏,都是面临的重大挑战。本文深入探讨了LLM的可信性,涵盖了鲁棒性、隐私、伦理和全面评估等方面。首先,以可信机器学习和NLP的基础原则为起点,我们进入应用领域,通过我们新颖的目标对抗性攻击框架和多样的扰动函数,识别并剖析现有LLM的脆弱性。针对这些脆弱性,我们设计了InfoBERT学习框架,从信息论的角度提高鲁棒性。接着,本文延伸到LLM的隐私领域,我们提出的方法DataLens利用生成模型和梯度稀疏性提供严格的差分隐私保证。我们还探讨了联邦学习,提出了一种在设备上训练模型时确保数据隐私的新范式,利用现有的公共LLM。针对伦理维度,我们重点研究了LLM的去毒化,确保其输出符合社会可接受的规范。为了严格评估LLM的可信性,我们引入了Adversarial GLUE基准,在具有挑战性的对抗条件下揭示模型的脆弱性。此外,我们还关注了检索增强语言模型,深入研究了可扩展的预训练检索增强模型Retro,并将其性能与标准模型进行比较。这项研究揭示了未来基础模型的有前途方向。深入到可信性评估领域,我们通过细粒度的可信性评估引入了DecodingTrust,特别关注最先进的LLM,包括GPT-4和GPT-3.5。通过这一深入探讨,我们发现了潜在的错误行为,包括生成偏见输出的易感性、潜在的数据隐私泄漏以及GPT-4等最先进LLM面临的复杂挑战。总之,本文对现有LLM中的脆弱性提供了若干关键见解,并为符合人类价值观的下一代LLM铺平了道路。本文的主要目的是推动可信大型语言模型领域的发展,促进可靠和无偏LLM的演进和发展。
https://www.ideals.illinois.edu/items/129170




