

扩散模型是一种通过模拟扩散过程的概率模型,逐步向数据中添加和去除噪声,从而生成逼真的样本。这些模型由于能够生成高质量的样本,已经在图像处理、语音合成和自然语言处理等领域中获得了广泛的关注。随着扩散模型在各个领域的广泛应用,现有的文献综述往往集中在特定领域,如计算机视觉或医学影像,因此可能无法满足跨多个领域的更广泛受众。因此,本综述对扩散模型进行了全面概述,涵盖了其理论基础和算法创新。我们重点介绍了它们在媒体质量、真实性、合成、图像转换、医疗保健等各个领域的应用。通过整合当前的知识并识别新兴趋势,本综述旨在促进对扩散模型的更深入理解和更广泛的应用,并为来自不同学科的未来研究人员和实践者提供指导。
关键词:扩散模型 · 生成建模 · 合成数据生成 · 图像合成 · 图像到图像转换 · 文本到图像生成 · 音频合成 · 时间序列预测 · 异常检测 · 医学影像 · 数据增强 · 计算效率 · 不确定性量化 · 黎曼流形 · 分子动力学 · 超分辨率 · 语义图像合成 · 零样本分类 · 大气湍流校正
1 引言
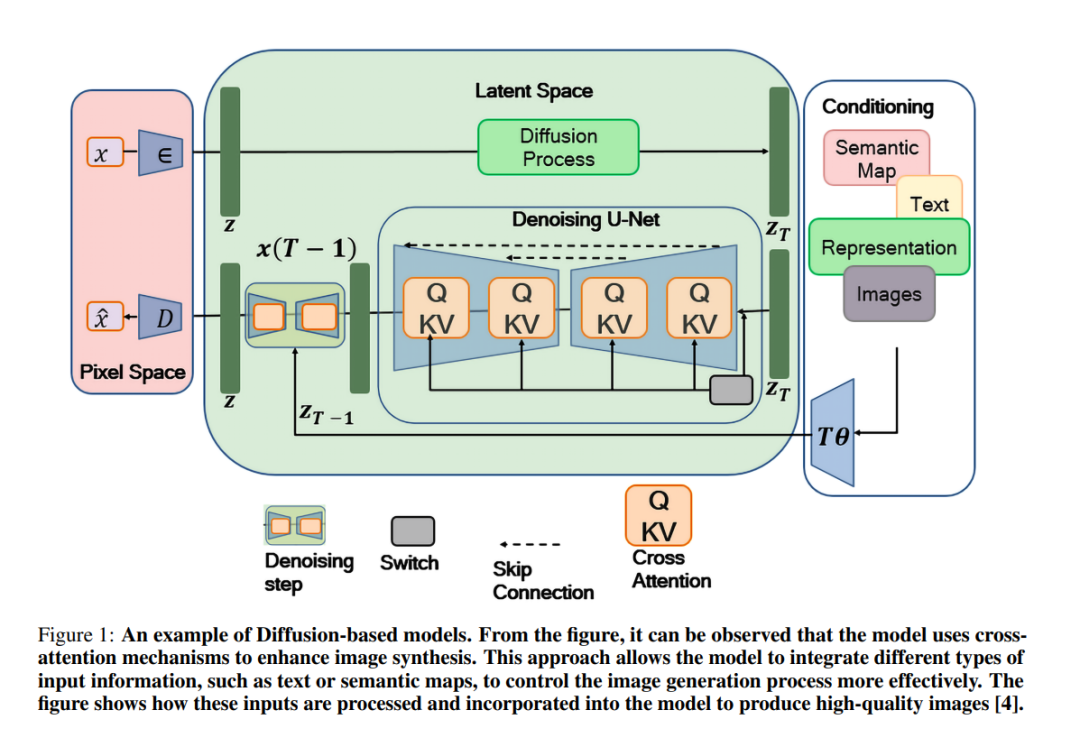
扩散模型(Diffusion Model,DM)是一类通过逆向扩散过程生成数据的生成模型,该过程逐步向数据中添加噪声,直至其变为高斯分布。这些模型首次由Sohl-Dickstein等人于2015年提出,已在图像、音频和视频合成等多个领域展示了出色的性能,能够生成高质量的样本 [1, 2]。该过程涉及一个迭代程序,模型在每一步训练时预测已添加到样本中的噪声,实质上是在学习对数据进行去噪。这种方法显著推动了生成细致且连贯输出的能力,使得DM成为诸如文本到图像合成和提高低分辨率图像等任务的强大工具 [3]。图1展示了用于高分辨率图像合成的扩散模型。
扩散模型(DM)已在多个领域中变得流行,尤其是在图像生成领域,它们能够基于文本描述创建逼真的图像、艺术作品和编辑内容 [3, 5]。在自然语言处理(NLP)中,DM也逐渐流行,用于文本生成和增强,展现了生成连贯且上下文相关文本的能力 [6]。在音频合成中,DM被用于生成逼真的声景、音乐和拟人化的语音,推动了创意和交流人工智能(AI)应用的边界 [7]。此外,它们的应用还扩展到分子和材料科学领域,用于设计新的化学化合物和材料,展示了其多样性。DM的流行源于其稳健性、灵活性和生成高保真度输出的能力,使其成为AI驱动的创意和科学领域中的突破性工具 [8]。
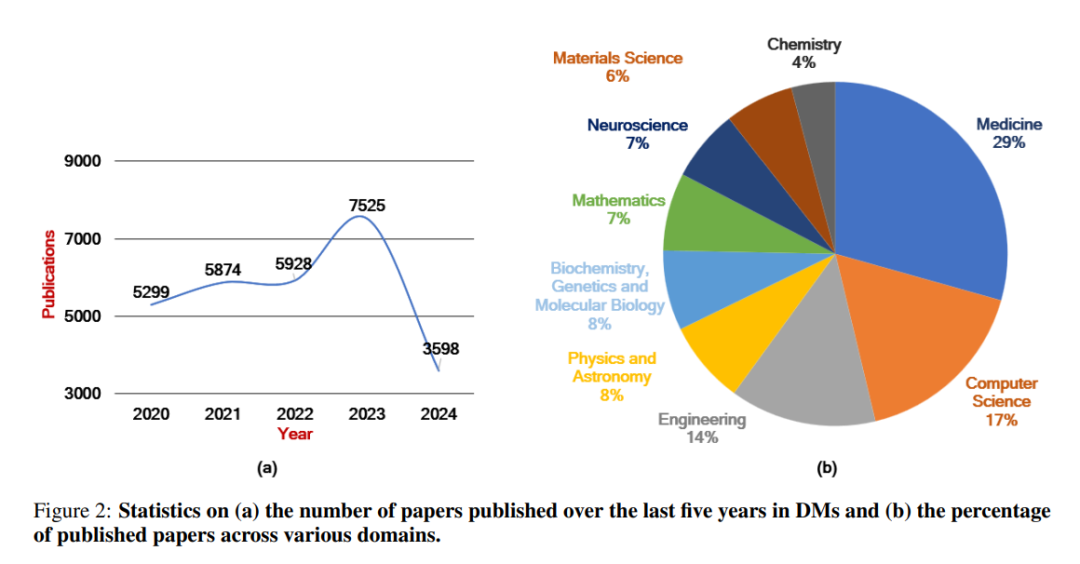
图2提供了过去五年在各种学科中发表的关于DM的论文的统计概览。从图2(a)中可以看出,自2020年以来,发表的论文数量一直在不断增长。图2(b)显示,医学领域的论文占比29%,居首位,其次是计算机科学,占17%,以及工程学,占14%。化学和材料科学等领域的论文较少,分别占总量的4%和6%。这些趋势突显了DM在医学和计算机科学中的广泛应用,而在其他领域的潜力尚未得到充分探索。
本综述旨在为DM在各个领域的应用提供全面概述,帮助广泛受众理解其能力和多样性。通过展示多样的应用,本综述鼓励跨学科合作和创新,潜在地解决超出传统应用如计算机视觉领域的未探索领域中的开放挑战。
1.1 本综述的动机与独特性
DM在各个领域的快速进展展示了其潜力和多样性。尽管相关出版物数量不断增加,但现有的综述通常集中于特定应用或狭窄领域,未能涵盖DM应用的广泛范围。考虑到这一机会,本综述旨在通过提供DM的全面概述来填补现有文献中的空白。
我们的贡献总结如下: ❑ 本综述涵盖了DM的多个关键方面,包括理论、算法、创新、媒体质量、图像转换、医疗应用等。我们概述了截至2024年3月的相关文献,突出最新的技术和进展。 ❑ 我们将DM分为三大类:去噪扩散概率模型(DDPM)、噪声条件分数网络(NCSN)和随机微分方程(SDE),有助于理解其理论基础和算法变种。 ❑ 我们重点介绍了与DM应用相关的创新方法和实验方法,涵盖数据类型、算法、应用、数据集、评估和限制。 ❑ 最后,我们讨论了研究结果,识别了未解决的问题,并提出了关于DM未来研究方向的疑问,旨在为研究人员和实践者提供指导。 图3基于本研究中引用的文献展示了DM的框架,在第2至第8节中进行了讨论。
1.2 搜索策略
数据来源于Scopus,初步通过标题、摘要和关键词使用搜索词“Diffusion Model” AND (“image” OR “audio” OR “text” OR “speech”)筛选出3746篇文章。将搜索范围限制为2020年至2024年间发表的英文、同行评审和开放获取的论文后,数量减少至473篇。进一步过滤排除了“human”(人类)、“controlled study”(对照研究)、“job analysis”(工作分析)、“quantitative analysis”(定量分析)、“comparative study”(比较研究)、“specificity”(特异性)等无关的关键词,最终筛选出326篇文章。
一位研究人员(Y.L.)将这326篇期刊文章导入Excel CSV文件以供详细分析。随后,利用Excel的重复检测工具识别并删除重复项。两位独立评审者(M.A.和Z.S.)评估了剩余论文的标题和摘要,确定了65篇相关文献。此外,还纳入了另外20篇相关文献,最终涵盖了来自各个领域的85篇论文。
扩散模型概述
**
初始化:从原始数据形式x0x_0x0 开始。
前向过程(噪声添加):在TTT 个时间步内逐渐添加噪声,根据预定义的噪声计划β\betaβ,将数据从x0x_0x0 转化为xTx_TxT。
反向过程(去噪):利用学习到的参数θ\thetaθ 从xtx_txt 顺序估计xt−1x_{t-1}xt−1,有效地逆转噪声添加,以重建原始数据或生成新的数据样本。
输入:原始数据X={x1,x2,…,xn}X = {x_1, x_2, \dots, x_n}X={x1,x2,…,xn}、总时间步数TTT、噪声计划β\betaβ。
输出:去噪或合成的数据X′X'X′。
训练:通过学习条件分布pθ(xt−1∣xt)p_\theta(x_{t-1}|x_t)pθ(xt−1∣xt) 来训练模型,以近似逆向噪声添加过程,对每个时间步ttt 从TTT 到 1 进行训练。 * 数据合成:从一个随机噪声样本xTx_TxT 开始,迭代地应用学习到的逆向过程:xt−1′=从pθ(xt−1∣xt)中采样x'{t-1} = 从 p\theta(x_{t-1}|x_t) 中采样xt−1′=从pθ(xt−1∣xt)中采样最终得到x0′x'_0x0′,即最终的合成或重建数据。
扩散模型的类型
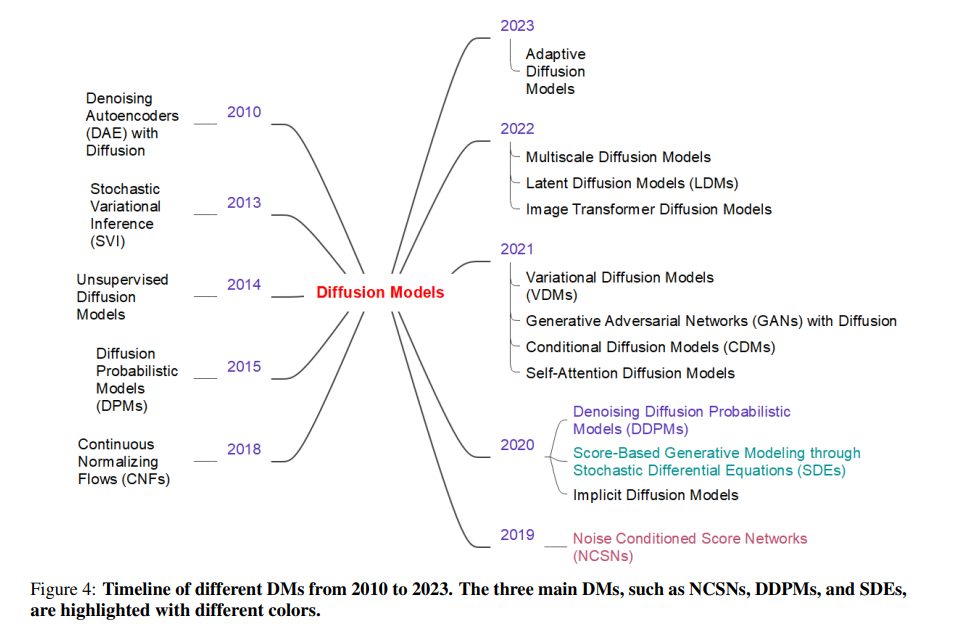
多年来,已经提出了几种基于扩散的模型,每一种都在生成建模的进步中作出了独特贡献。图4展示了一些重要和有影响力的扩散模型及其时间线。其中,有三种扩散模型因其对各种应用的影响而非常流行并广泛采用:去噪扩散概率模型(DDPMs)、噪声条件分数网络(NCSNs)和随机微分方程(SDEs)。
扩散模型应用
近年来,由于扩散模型(DM)能够生成高质量、逼真且多样化的数据样本,其受到了极大的关注,使得它们在多个前沿应用领域中得到了广泛部署。DM广泛应用于以下几个最受欢迎的领域: ❑ 图像合成:DM用于从噪声分布中创建详细的高分辨率图像。它们可以生成新图像或通过提高清晰度和分辨率来改善现有图像,使其在数字艺术和图形设计等领域中尤为有用 [13]。 ❑ 文本生成:DM能够生成连贯且上下文相关的文本序列。这使其适用于诸如创作文学内容、在虚拟助手中生成逼真的对话以及自动生成新闻文章或创意写作的内容 [14]。 ❑ 音频合成:DM能够从噪声信号中生成清晰且逼真的音频。这在音乐制作中非常有价值,因为需要创建新的声音或改善录制音频的清晰度,还包括在各种辅助设备中使用的语音合成技术 [7]。 ❑ 医疗保健应用:尽管不限于医学影像,DM在合成医疗数据方面发挥了重要作用,包括磁共振成像(MRI)、计算机断层扫描(CT)以及其他影像模态。这种能力对于培训医疗专业人员、改进诊断工具以及开发更精确的治疗策略至关重要,同时不会影响患者隐私 [15]。
表1总结了2020年至2023年间一些著名的DM论文,提出的算法、使用的数据集和应用。不同颜色用于区分各种算法和应用类型。从表1中可以看出,大多数论文主要集中在基于图像的应用上,如图像生成、分割和重建。

结论
扩散模型(DM)通过生成逼真的样本来解决数据生成和处理中的挑战,有望在许多领域带来变革。因此,解决当前的局限性并在DM的优势基础上进行改进,将使其在未来各个领域得到更广泛的应用并产生更大的影响。我们的研究发现,DM生成高质量合成数据的能力提高了应用中的表现,如文本到图像生成,其中像Diffusion Transformers(DT)用于稳定扩散的模型在数据隐私方面展示了进展 [35]。在网络物理系统安全中,时序和特征TFDPM通过使用图注意网络(Graph Attention Networks)关联通道数据来帮助检测攻击 [36]。此外,在云服务异常检测中,像Maat这样的模型通过结合度量预测和异常检测来实现更高的准确性 [37]。 在图像处理方面,基于扩散的技术在图像去模糊和超分辨率等任务中表现出色。例如,使用DM进行的随机图像去模糊在感知图像块相似性和结构相似性指数测量上取得了高分 [31]。此外,用于MRI重建的加速CMD在提高图像质量方面展现了潜力 [32]。此外,选择性扩散蒸馏方法在平衡图像保真度和可编辑性方面表现出色,适用于各种图像操作任务 [33]。 然而,尽管DM可以生成逼真的数据,它们也引发了伦理问题。一个主要问题是潜在的滥用,例如创建深度伪造和合成媒体,可能会传播虚假信息或侵犯隐私。为了降低这一风险,建立强大的检测机制至关重要。确保模型保持公正性也同样重要,这可以通过引入公平性算法和多样化的训练数据来实现。此外,DM的透明度和可解释性至关重要,LIME和SHAP等技术可以提供模型生成结果的洞见。除此之外,还需要确保数据符合GDPR和健康隐私保护法(HIPAA)等法规的要求 [99, 100, 98]。 高计算需求和对更好采样或网络架构的需求是DM中反复出现的问题。模型通常需要广泛的超参数调优,并且可能在离散信号建模或在不同上下文中泛化方面遇到困难 [36, 37]。此外,对某些模型而言,为语义引导选择正确的时间步可能会限制其灵活性 [33]。较慢的推理速度和高资源需求阻碍了实时部署和可扩展性 [32, 31]。 因此,未来的研究应通过开发更高效的算法和利用计算技术的进步来解决这些局限性。探索半监督或无监督学习方法,并结合预训练模型的迁移学习,可以帮助克服数据稀缺问题。提高DM对噪声的鲁棒性及其处理不同数据类型的能力至关重要。此外,持续的跨学科合作和明确的伦理准则对于在各个领域中负责任且有效地使用DM至关重要。
