
本文介绍被ICML 2022接收的新工作。我们提出了首个防御数据注毒攻击的集体鲁棒性认证方法(针对袋装算法Bagging)。 论文题目:On Collective Robustness of Bagging Against Data Poisoning 作者信息:Ruoxin Chen, Zenan Li, Jie Li*, Chentao Wu, Junchi Yan 关键词:可信防御,数据注毒攻击、鲁棒性认证、袋装法
动机:
**1)数据注毒攻击的可信防御:
数据注毒攻击是一种被广泛研究的攻击方式,现在已有许多工作研究相关的可信防御(certified defense), 包括:1)Deterministic bagging; 2)Random bagging; 3)Finite aggregation 等等,事实上,这些可信防御都可以归纳为Bagging的一种特殊形式。其主要思想为:1. bagging的子模型都是在子数据集上训练得到,这防止了一个训练样本影响所有的训练模型,即更改一个训练样本所影响的子模型数量是有限的。2. bagging输出所有子模型投票最多的那个类别,top1票数与top2票数之间存在的差值成就了bagging为基础的可信防御的鲁棒性。
**2)鲁棒性验证 (robustness certification):
现在的鲁棒性认证都集中于认证单个预测值的鲁棒性(sample-wise robustness certification),即:判断是否存在一种数据注毒攻击,能够改变指定的模型预测结果。然而,数据注毒攻击是一种天然的全局攻击,即:数据注毒攻击将会使得训练后的模型发生改变,这种改变可能会影响所有的模型预测结果。所以理所当然的,相比于验证单个预测结果是否会被数据注毒攻击改变,我们更需要关注数据注毒攻击对于整个测试集的全局影响,即:一个攻击强度受限(我们论文中定义攻击强度为:攻击者可以插入个任意的恶意训练样本,删除个已存在的训练样本以及任意修改个任意已存在的训练样本)的数据注毒攻击,最多能够改变多少个预测结果。实际上,现有的单点验证方法对测试集的每个样本一个个地验证也能给出预测改变数量的一个上界,但是该上界往往与真实上界差距极大,这是因为现有的鲁棒性认证方法并非将测试集看作一个总体,导致过于高估攻击的危害。
**预先知识(Preliminary):
威胁模型(Threat model):因为我们追求的是可信防御,且由于我们防御是适用于任意的模型的,所以我们假设攻击的最坏情况:对于分类模型而言,一旦其训练集被任意修改,那我么我们就认为该模型已经完全被攻击者操控(即攻击者能够任意指定其输出结果)。 单点鲁棒性验证(sample-wise robustness certification): 给定bagging的每个子训练集(对应每个子分类器的训练集)的分布,以及每个子分类器的输出类别,假设我们只能改变个训练样本,那么对于攻击者来说策略是:找到个训练样本,控制这些训练样本所能影响的子分类器的预测结果,使得最终的其他类别的票数大于等于原先top1类别的票数,则攻击成功。
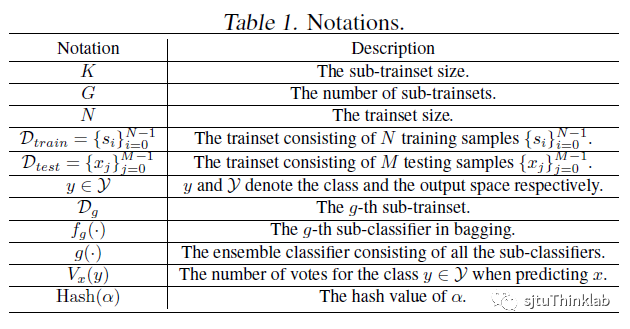
**符号:
为了方便理解论文内容,我们先讲清楚我们的符号表示,如下:
**集体鲁棒性认证 (Collective certification):
我们主要思路就是非常简单,就是:在给定的攻击强度下(),我们该选择去攻击哪些训练样本,使得改变的预测结果数量最大化:

这里所求出的即是我们所能改变的预测结果数量的最大值。接下来我们分别解释每隔公式的含义: 式(2):为指示函数,表示攻击之后top1类别的得票数,表示攻击之后除top1类别之外的的得票数最大值,该式其实就在统计有多少的预测被改变了。 式(3):为01向量表示我们选择攻击哪些训练样本,其中表示选择攻击第个训练样本。 式(4),式(5):分别计算出攻击后的对于top1类别的最小投票数与其他类别的最大投票数。 最后我们求解该01线性整数规划问题(binary integer linear programming),即可求出,而不变预测数量至少为.
**鲁棒性上界 (Upper bound of robustness):
在探索了集体鲁棒性验证方法之后,我们接下来想要提升Bagging鲁棒性。我们提升鲁棒性的思路为:找到bagging的哪些因素会制约鲁棒性,然后改善那些因素。所以,我们给出以下结论,明确地给出bagging能容忍的注毒样本上界与bagging之间的关系:
**更好的bagging方案
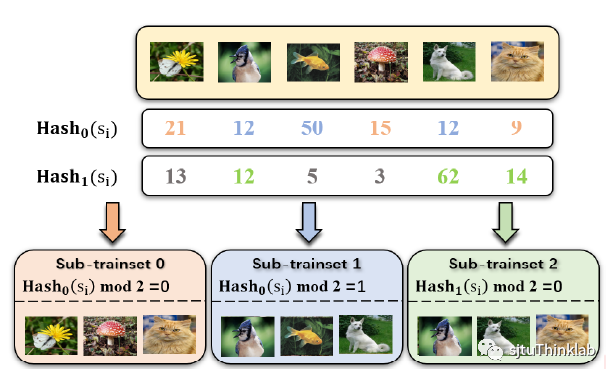
根据鲁棒性上界的思想(限制),我们重新设计了Bagging的子训练集构造机制,Hash Bagging。其思想就是,将所有样本尽可能地平均分配到每个子训练集中,具体为:假设我们要将N个训练样本分成G个子训练集,我们计算出每个训练样本的哈希值,然后将训练样本分配到 第个子训练集。论文中我们还设计了更加泛用的子训练集构造方案,能够同时指定子训练集的数量与子训练集的大小,细节请看我们的论文。
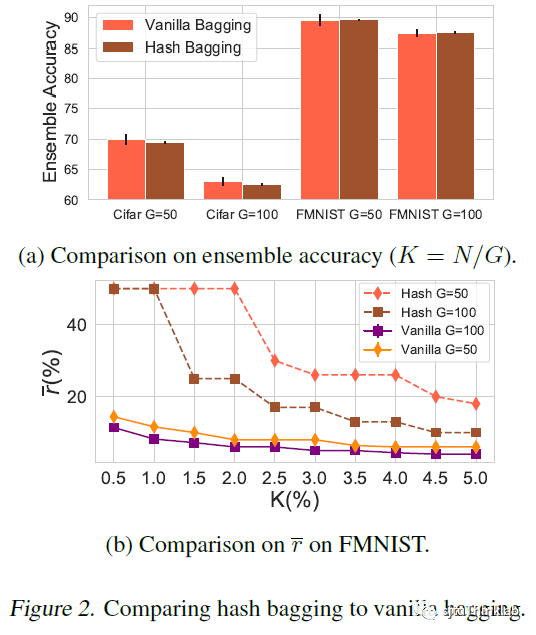
**实验结果 (Experiment):
1) 我们对比了hash bagging与普通的bagging(随机选取训练样本分配到子训练集之中)效果
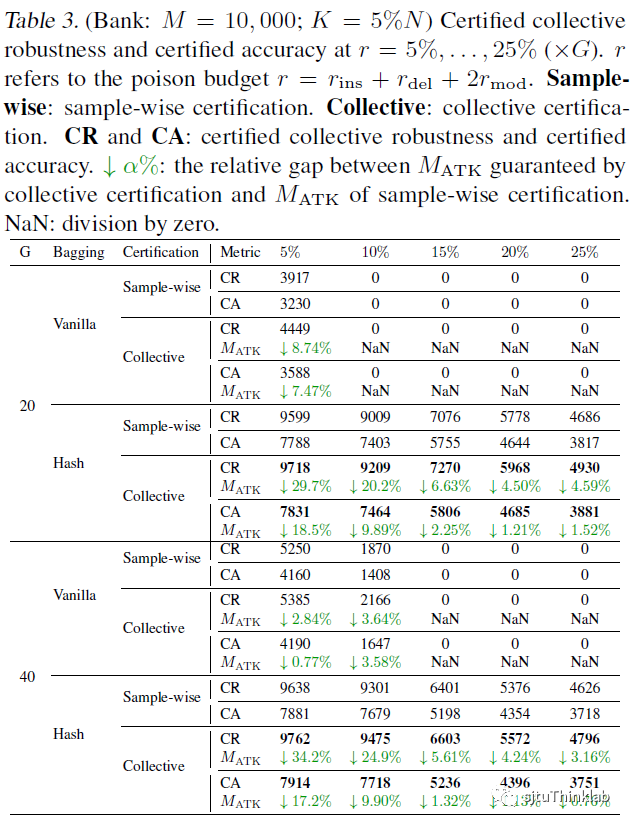
2) 在认证集体鲁棒性方面,我们对比了我们的collective certification与sample-wise certification:
更多的实验结果请看我们的论文~
**未来展望 (Future Work):
现在在防御数据注毒攻击方面,关于集体鲁棒性认证的工作还很少,我们希望能够将集体鲁棒性认证能够推广到更多的可信防御上。
