
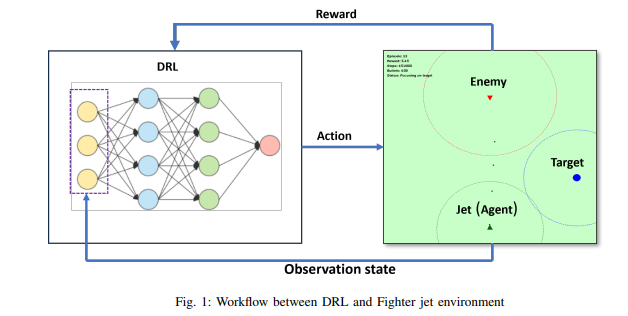
本文开发了一种基于人工智能的战斗机智能体,通过定制化Pygame模拟环境实现多目标任务求解。该智能体采用深度强化学习(DRL)算法,核心功能包括环境高效导航、目标点抵达、选择性接敌/避敌。研究通过奖励函数平衡多目标优化,结合超参数调优提升学习效率,实现超过80%的任务完成率。为增强决策透明度,采用事实-反事实对比分析方法:通过比较智能体实际选择动作(事实动作)与替代动作(反事实动作)的奖励差异,揭示其决策逻辑。本研究表明DRL与可解释AI(XAI)在多目标问题求解中的协同潜力。
近年来,AI技术快速发展,已在多个领域展现变革性力量。从1997年国际象棋超越人类,到攻克复杂围棋博弈,AI逐步实现高风险战略任务的自主执行。强化学习(RL)作为AI子领域,通过试错机制使智能体自主探索有效行动策略,摆脱了对人类专家数据的依赖。
在战机导航与作战领域,已有研究存在以下局限:仿真模型聚焦空战场景模拟,缺乏DRL算法设计与奖励函数优化;虽涉及强化学习,但未通过事实-反事实分析实现决策可解释性,且未阐明智能体效率提升机制;飞行员训练系统侧重训练场景构建,其奖励机制局限于训练目标导向,未实现效率与资源管理的复杂平衡;采用简单奖励函数(如击落目标/规避坠毁),难以支持长短期决策权衡的精细化学习
本研究针对上述缺陷进行系统性改进,主要贡献包括:
- 多目标平衡奖励框架:融合效率优化、资源管理与智能决策的复合奖励机制
- 可解释性增强方法:通过事实-反事实对比分析,提升智能体决策透明度与逻辑可溯性
研究分为以下几个主要部分:首先,开发了一个定制的模拟环境。接下来,使用双深度 q 学习(DDQN)算法训练战斗机智能体做出战略交战决策。然后,重点优化任务资源,并通过事实和反事实情景解释智能体的决策过程。通过解决优先级排序、自适应行为和风险评估等挑战,这项研究旨在推动复杂多目标场景下智能自主系统的发展,最终增强人工智能在高风险环境中的作用。
成为VIP会员查看完整内容
相关内容

Arxiv
36+阅读 · 2023年4月19日
Arxiv
195+阅读 · 2023年4月7日
Arxiv
76+阅读 · 2023年4月4日
Arxiv
136+阅读 · 2023年3月29日


相关VIP内容
相关资讯
相关论文
Arxiv
36+阅读 · 2023年4月19日
Arxiv
195+阅读 · 2023年4月7日
Arxiv
76+阅读 · 2023年4月4日
Arxiv
136+阅读 · 2023年3月29日