

在安全关键型应用中,验证和认证人工智能驱动的自主系统(AS)所做的决策至关重要。然而,这些系统中使用的神经网络的黑盒性质往往使实现这一目标具有挑战性。这些系统的可解释性有助于验证和认证过程,从而加快其在安全关键型应用中的部署。本研究通过语义分组奖励分解研究了人工智能驱动的空战智能体的可解释性。论文介绍了两个使用案例,以展示这种方法如何帮助人工智能和非人工智能专家评估和调试RL智能体的行为。
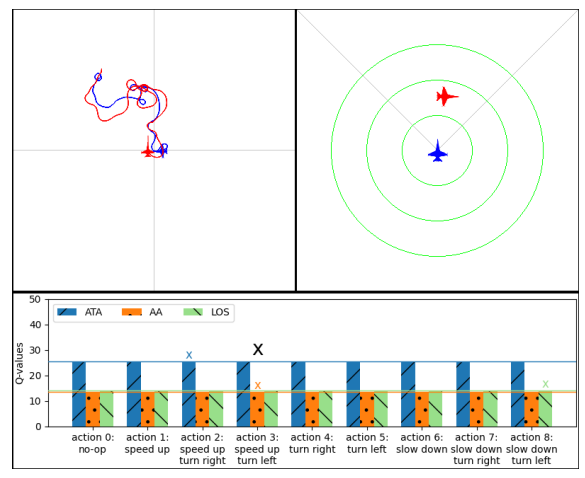
图 3. 训练有素的 RL 智能体跟踪性能。左上图为鸟瞰图。右上图是从蓝色智能体框架透视的,每个绿色圆圈的半径为 1000 米。下图是分解奖励条形图,黑色 x 符号代表选择的行动,其他 x 符号代表与每个 DQN 的最大预期奖励相关的行动,它们分别代表各自的奖励类型。
成为VIP会员查看完整内容
相关内容

Arxiv
152+阅读 · 2023年3月29日




相关VIP内容
相关资讯
相关论文
Arxiv
152+阅读 · 2023年3月29日