

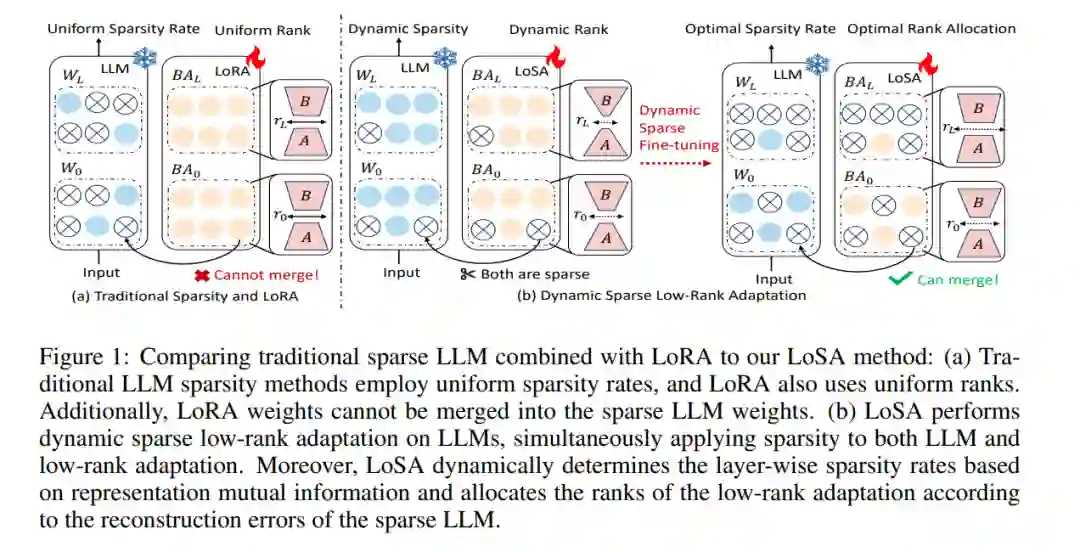
尽管网络稀疏性在缓解大型语言模型(LLM)部署压力方面具有一定效能,但仍存在显著的性能下降问题。将低秩适应(LoRA)应用于微调稀疏LLM提供了一种直观的方法来应对这一困境,但其存在以下不足:1)训练后无法将LoRA权重集成到稀疏LLM中,2)在高稀疏比率下性能恢复不足。本文介绍了动态低秩稀疏适应(LoSA),一种新颖的方法,在统一框架内将低秩适应无缝地集成到LLM稀疏性中,从而提升稀疏LLM的性能,同时不增加推理延迟。特别地,LoSA在微调过程中基于对应的稀疏权重动态稀疏化LoRA结果,从而确保LoRA模块能够在训练后集成到稀疏LLM中。此外,LoSA利用表示互信息(RMI)作为指标来确定各层的重要性,从而在微调过程中有效地确定各层的稀疏率。基于此,LoSA根据层级重构误差的变化调整LoRA模块的秩,为每一层分配合适的微调量,以减少稠密LLM和稀疏LLM之间的输出差异。大量实验表明,LoSA可以在几小时内有效提升稀疏LLM的效能,而不会引入任何额外的推理负担。例如,LoSA将稀疏LLaMA-2-7B的困惑度降低了68.73%,并将零-shot准确率提高了16.32%,在CPU上实现了2.60倍的加速,在GPU上实现了2.23倍的加速,仅需在单个NVIDIA A100 80GB GPU上进行45分钟的微调。代码可在https://github.com/wzhuang-xmu/LoSA获取。
成为VIP会员查看完整内容
相关内容
相关VIP内容
相关资讯
相关论文