基于深度学习的视频目标检测综述
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者: 李为
https://zhuanlan.zhihu.com/p/67608224
本文已授权,未经允许,不得二次转载
最近对深度学习在视频任务中的应用做了个简单调研,切入点是视频目标检测,刚开始调研的时候很乐观,本想着作为研究课题继续研究,但是随着调研深入,到最后发现这个领域还是慎入,在这里把调研报告放出来吧。
摘要:近些年来,深度卷积神经网络在图像目标检测领域迅速普及,而且相较于传统方法取得了很好的效果,基于深度学习的图像目标检测也逐渐合称为一个统一的深度网络框架。在图像目标检测任务取得了不错的效果后,深度学习又迁移到基于视频的目标检测任务上。本文系统总结基于深度学习的视频目标检测方法,归为2类:基于检测和跟踪的深度学习视频目标检测方法以及基于光流等动态信息的深度学习目标检测算法。本文通过细致探究这些方法,并进行横向的对比,结合在ImageNet VID数据集上的实验,相近分析每个方法的优势和劣势以及他们之间的联系。
关键词:深度卷积网络,视频目标检测,光流信息,循环神经网络
绪论(东拼西凑)
目标检测是计算机视觉领域的一个经典的任务,是进行场景内容分析和理解等高级视觉任务的基本前提。视频中的目标检测任务更是和现实生活的需求贴近,现实生活中的智能视频监控、机器人导航等应用场景都需要对视频进行处理,对视频中的目标进行检测。视频中的目标检测需要在静态图像目标检测的基础上对目标因运动产生的各种变化进行处理,这是其中的难点。
传统的目标检测方法主要使用方向梯度直方图 ( Histogram of Oriented Gradient, HOG)、尺度不变特征变换( Scale-Invariant Feature Transform,SIFT)特征对滑动窗口进行判别,主要代表方法为部位形变模型( Deformable Part Model,DPM) 及其扩展。由于滑动窗口需要大量的计算开销,基于候选窗口的目标检测方法后来居上,目前较通用的候选窗口产生方法包括选择提取 ( Selective Search )、边缘窗口 ( Edge- Box)等。
随着深度学习的发展,深度卷积神经网络迅速应用到计算机视觉的每个领域,相较传统方法取得了比较大的进步。深度卷积网络主要通过权值共享策略将网络的层次不断加深,使网络具有更强的解析能力。ImageNet、COCO等大规模图像数据库的建立极大促进深度网络的发展。具有 7 层的 AlexNet卷积网络在 ImageNet 图像分类大赛中以绝对的优势获得冠军,其有效性也得到越来越多的验证.随后,VGG网络、GoogleNet及残差网络[20]等将卷积网络推向更深层次,大幅提高网络的性能,使大规模图像分类的准确率提升到很高的水平。
同时,研究人员也开始寻求深度卷积网络在其它领域的扩展.在目标检测方面,基于区域的卷积神经网络( Region Based Convolutional Neural Network,RCNN)成功连接目标检测与深度卷积网络,将目标检测的准确率提升到一个新的层次.RCNN由 3 个独立的步骤组成: 产生候选窗口、特征提取、SVM 分类及窗口回归.RCNN主要采用 Selective Search 的方法产生许多候选窗口.随后将所有产生的候选窗口一次送入深度网络提取特征.最后训练 SVM 分类器对所有候选窗口进行分类及窗口回归. 由于RCNN分为 3 个独立的过程,所以检测效率很低.基于此种情况,学者们改进 RCNN,提出尺度金字塔池化网络( Spatial Pyramid Pooling Net,SPPnet)和快速基于区域的神经网络( Fast Region Based Convolutional Neural Network,Fast- RCNN).不需要将所有的候选窗口送入网络,只需将图像送入深度网络一次,再将所有的候选窗口在网络中某层上进行映射,大幅提升模型的检测速度.
更快的基于区域的卷积神经网络( Faster RegionBased Convolutional Neural Network,Faster- RCNN)利用候选窗口网络( Region Proposal Network,RPN) 产生候选窗口,利用与 Fast-RCNN 相同的结构进行分类及窗口回归,RPN 和 Fast-RCNN 共享主要的深度网络.Faster-RCNN 将目标检测合成一个统一的深度网络框架.基于区域的全卷积网络( Region Based Fully Convolutional Network,RFCN)在此基础之上进行进一步改进,分析发现感兴趣区域( Region of Interest,ROI) 池化后的网络层不再具有平移不变性,并且 ROI 池化后层数的多少会直接影响检测效率.因此,RFCN 设计位置敏感的 ROI 池化层,直接对此池化之后的结果进行判别,大幅提升检测效率. YOLO( You Only Look One)与 SSD( Single Shot Multibox Detector)的提出旨在提升目标检测的检测效率,试图使目标检测达到实时检测的程度.特别地,SSD 能在提升目标检测效率的同时保持检测精度,是在检测精度与检测效率上双赢的算法。
基于视频的目标检测任务相比于静态图像的目标检测任务,目标的外观、形状、尺度等属性会随着目标的运动发生变化,在检测过程中如何保持时间顺序上目标的一致性从而不会使目标在中间某帧丢失,这是视频目标检测任务的主要难点。由于视频比静态图像多了一个时间维度上的信息,所以很多视频目标检测算法利用该信息来增强检测性能。本文对近几年深度学习在视频目标检测任务上的工作进行了总结,将其分为两个不同的技术流派。第一种是对视频中每一帧进行目标检测,然后在使用跟踪算法对目标框进行跟踪,使用跟踪的结果对之前的检测结果进行修正。另一种是利用目标在视频中因为运动产生变化的信息直接在视频上进行目标检测,比如光流就是其中一种比较有效地运动信息,会随着时间的推移,成为目标运动有效地判别信息,利用这些信息算法可以将发生变化的目标也高效的检测出来,保证了检测的准确性和鲁棒性。
2. 基于深度学习的视频目标检测
2.1 视频目标检测任务中的挑战
视频目标检测任务中最大的困难就是如何保持视频中目标的时空一致性。众所周知,视频是由多个有序列关系的图像组成的,该序列关系是一种时间的序列关系,因此其中的目标如果在运动,那么空间位置以及其自身的属性会发生变化,而且这种变化与时间存在紧密的关系,但即使发生了变化,每一帧的发生变化的目标还是属于同一个目标,这就叫做时空一致性。
具体的挑战分为以下五类:
(a). 运动模糊:目标在现实中的运动实际上是一个连续的过程,但是摄像机是按照一幅一幅图的取景,每次捕捉图像的时候,会用快门控制外景进入相机内部成像组件,而快门闭合的速度就决定每次取景有多长时间外景被捕捉到,所以就会出现目标一段运动中多个被合成为一个的情况,也就产生了运动模糊。这个时候,目标的外观并不容易被分辨,如图1所示。

(b). 虚焦:这是因为摄像设备并没有一直准确的对目标进行对焦产生的问题。这种情况可能会使视频一种一些包含目标的帧中目标出现模糊或者使视频一些帧的图像产生整体的模糊,如图2所示。

(c). 遮挡:目标在运动过程中,可能会出现运动到一些物体的后方,而被该物体遮挡,如图3所示。

(d). 外观变化:视频中目标可能会出现外观上的变化,例如图4中所示变色龙出现罕见的姿势。

(e). 尺度变化:目标在运动过程中,从镜头中远的地方运动到近的地方,其外观的尺寸可能会发生变化。
2.2 检测和跟踪结合的视频目标检测算法
保持目标时空一致性的一个直接的思路就是,对目标进行跟踪,在视频中跟踪检测出来的目标。代表工作是T-CNN[1]。接下来我们将对该方法进行简要介绍。
本文的发现是视频目标追踪任务学习到的时间信息与静态目标检测任务学习到的空间特征相结合可以提升视频目标检测任务的性能。
T-CNN提出了一个基于深度学习的目标检测和跟踪的多阶段的框架,具体由管道提取模块和管道分类以及重打分模块构成,如图5所示:
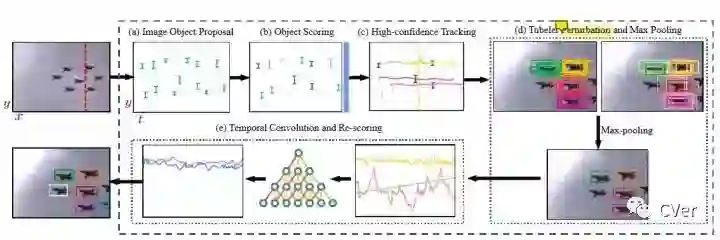
管道指的是视频对每个目标在每一帧提取的检测框按照时间序列顺序连接在一起,就构成了一个管道。这里管道提取模块主要由三个步骤完成:静态图像的目标检测,先用Selective Search方法提取很多目标候选框,然后使用CNN对这些框进行分类,去除背景框;第二,使用R-CNN对目标框进行分类别的打分;第三,对高置信度的框进行跟踪。
重打分模块,利用一个Temporal Convolutional Network(TCN)网络进行时域卷积。TCN的输入是每个管道的各种属性,例如检测得分,跟踪得分,坐标以及时间区段。最后会输出重打分的结果。
本文利用跟踪算法来与目标检测算法相结合,两者相辅相成,增强了视频目标检测的性能。但是该方法也有一定局限性:1、依赖视频目标追踪算法的性能;2、算法过程较为复杂,实时性不够高;3、并没有直接的针对模糊、运动等视频信息的进行利用并加以解决视频中为出现类似的实际情况。
2.3 利用运动信息的视频目标检测算法
考虑到上述方法的局限性,研究者希望直接利用视频中的运动信息进行视频目标检测。目前使用的比较多的运动信息是光流。是空间运动物体在观察成像平面上的像素运动的瞬时速度,是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。一般而言,光流是由于场景中前景目标本身的移动、相机的运动,或者两者的共同运动所产生的。举例如图6所示:

(1)Flow-Guided Feature Aggregation
这方面比较早的尝试是Flow-Guided Feature Aggregation[2]。本文的发现是视频中的光流信息和时间信息可以提升视频目标检测任务的性能。
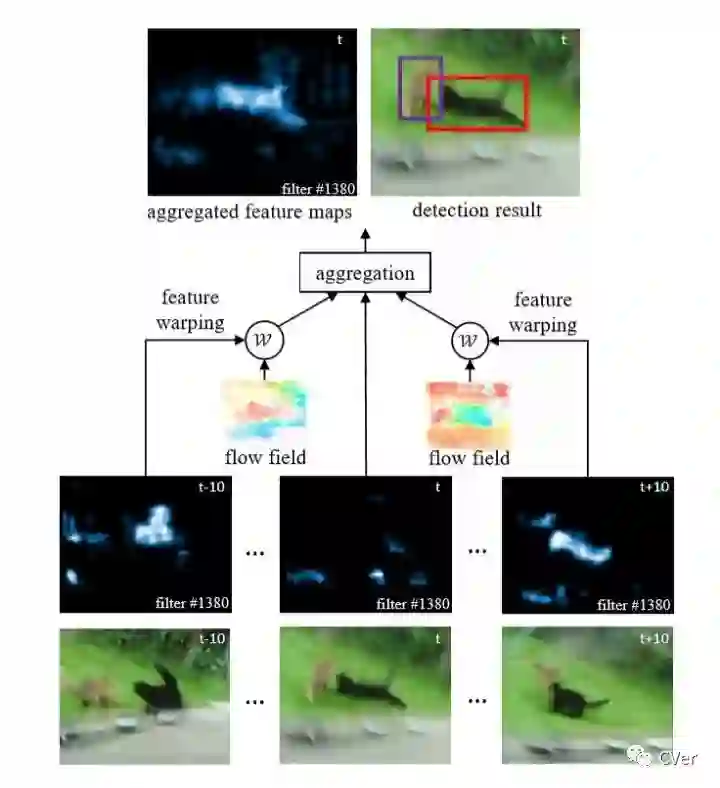
FGFA主要由光流提取和特征融合两个模块构成。光流利用FlowNet[flownet]网络进行提取。每次提取当前帧到相邻帧的光流,并将相邻帧的特征按照提取到的光流和当前帧的特征组合在一起。组合完成后,就进入特征融合阶段,将当前特征和与其相邻的多个特征进行融合。本文中使用了元素直接记性权值求和的方式进行融合。这里的权值衡量的是光流提取阶段得到的组合特征与相邻帧的特征的相似程度,文中利用余弦相似度进行描述。算法的具体架构如图7所示。
本文利用了光流信息,并用特征融合增强了特征的判别度,因此在视频目标检测中取得了比较好的效果。但是仍然有一些不足:1、计算多帧的光流然后进行特征融合的计算量非常大;2、特征融合的权重是一个cosine权重,该方法比较简单粗暴,有提升的空间。
(2)Association LSTM
FGFA离线提取光流导致一方面计算量非常大,这和视频应用所要求的实时性不符;另一方面,离线的光流提取网络并不能在训练阶段进行反向传播修正。因此有研究者提出了在线利用运动信息的视频目标检测算法,Association LSTM[3]。
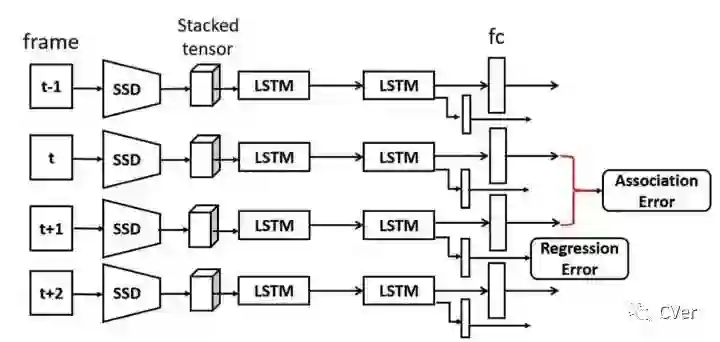
本文的研究基础是认为LSTM可以充分学习视频序列中的时间信息。本文提出的方法主要由静态图像目标检测算法SSD和LSTM组成。SSD在视频的每一帧进行目标检测,按照SSD检测结果提取目标的特征,然后进行堆叠,送入LSTM,LSTM可以在同一时间处理多个目标框,同时也有记忆特性,这一特性十分适合基于时序的视频目标检测任务。本文的LSTM对每一帧处理完后,除了边框的Regression Error,还会在相邻两帧LSTM的输出结果上额外计算一个Association Error。Association Error就体现了两帧在时序上的一致性差异,最小化该loss就能保持目标的时空一致性。算法流程如图8所示。
本文的想法很直观,而且很有效,充分的利用了LSTM的优势,增强了视频目标检测算法的鲁棒性。但是本方法存在一些局限性:1、严重依赖与进行定位检测跟踪算法的性能;2、相邻帧所反映的目标变化信息有局限性,只能反映出短期的运动信息,而对长时间的运动信息无能为力。
(3)Aligned Spatial-Temporal Memory
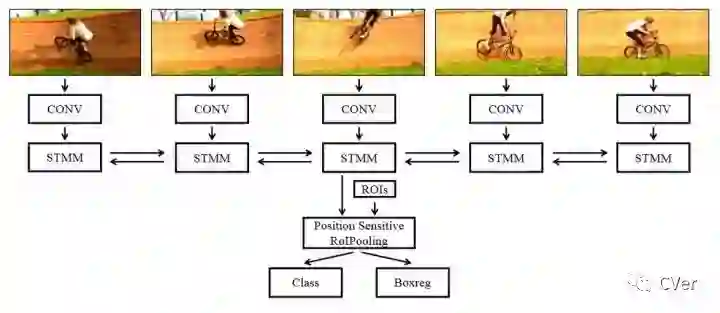
相比Association LSTM方法,本文对多帧体现的运动信息进行学习。本文提出的算法结构叫做Spatial-Temporal Memory Network(STMM)[4],实际上是一种循环卷积网络。对于当前帧,通过在相邻多个连续帧上进行卷积堆栈以获得保留了空间特性的特征,然后将其送入STMM模块。然后将来自当前帧的STMM输出送到分类和回归子网络中。
STMM是一个双向的循环卷积网络,所以该模块既可以利用少数几帧相邻帧之间目标的运动信息,也可以学习到目标长时间段的运动和外观变化信息。具体算法结构如图9所示。
本文在运动信息的利用方面更进一步,可以学习到长期的运动信息,从而提升视频目标检测算法的性能。但是本文的方法仍然有一些缺陷:1、LSTM算法并行程度不高,训练效率受限;2、相邻帧所反映的目标变化信息有局限性,因为本文虽然学习了长期的运动信息,但是从相距比较远的帧的运动信息还是通过相邻帧一步一步从STMM单元传送到当前帧的,这样是一种间接的方式,效率并不算太高。
(4)MANet
本文也是试图学习多个相邻帧所以先出的目标运动信息。相比较于STMM方法,本文还使用了多帧特征融合的方法,可以直接学习到长时间段的运动信息。
本文的研究发现是全局目标和光流特征与局部目标和光流特征的结合可以增强检测器的性能。MANet[5]先在图像提取全局特征,同时计算帧之间的光流信息,然后将图像提取的特征和光流信息一起融合,这两个步骤完成了特征和光流提取以及像素级别的特征校准。接下来在全局特征中针对目标实例利用运动信息继续进行特征校准。最后将像素级别校准后的特征和实例级别校准后的特征进行融合,用来训练和测试。整个算法结构如图10所示。
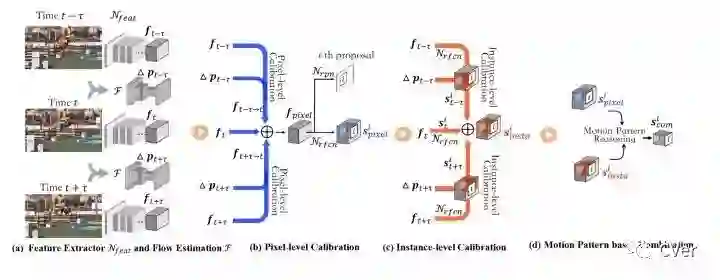
本文的想法集合了前人研究中的优势,取得了足够好的性能。可能存在的不足之处就是特征融合使用了直接相加的方法,该方法比较简单粗暴,可能成为性能进一步提升的瓶颈。
3. 实验及结果分析
视频目标检测任务中主要由两个数据集。第一个是ImageNet VID数据集,该数据集由三个不同的分割组成。 1)训练集包含1952个完全标记的视频片段,每个片段从6帧到5213帧不等。 2)验证集包含281个完全标记的视频片段,每个片段从11帧到2898帧。 3)测试集包含458个片段,实际上真实的标注尚未公开,所有的算法都将验证集上进行验证。第二个数据集是YTO数据集,该数据集包含10个类别,它们是ImageNet VID数据集的子集。与包含所有视频帧上的完整注释的VID数据集不同,YTO数据集被弱注释,即每个视频仅被确保包含相应类的一个对象,并且每个视频仅注释非常少的帧。
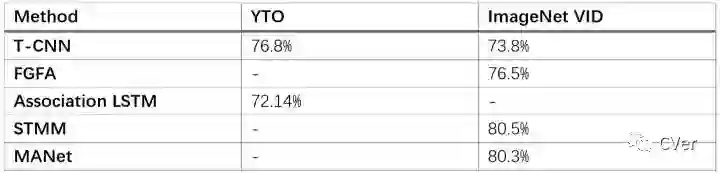
表1体现了上述五种算法在两个数据集上取得的性能。在YTO数据集上Association LSTM的效果比T-CNN差一些,这是因为YTO并不是强标注的,没有强标注数据对于深度神经网络来说训练比较困难,而T-CNN中使用了跟踪的方法,实际上也算是对弱标注的一种加强型标注,所以效果会好一些。而ImageNet VID这种严格标注的数据集上,T-CNN方法的效果就是最差的,利用离线光流学习的FGFA会好一些,最好的两个方法是利用了在线而且多帧的光流运动信息学习的STMM和MANet方法。
4. 结语
近几年基于深度学习的视频目标检测算法发展迅猛,具有如下研究热点:学习帧之间的光流等运动信息,因为运动信息是保持视频目标时空一致性的重要判别信息,所以算法利用离线或者在线的方式进行学习,离线学习方法不能方向传播就修正,而在线光流学习的方法可以在训练期间进行修正,因此会有更好的性能;另一个研究热点是对多帧特征进行融合,这种方式会更好的利用视频序列中帧之间的运动所产生的变化信息。目前阶段视频目标检测算法的性能已经不错,而计算量和实时性是一个制约其应用的亟需解决的问题。
题外话:该领域还是慎入= =
参考文献:
[1] KK.Singh, FY Xiao, YJ Lee. Track and Transfer: Watching Videos to Simulate Strong Human Supervision for Weakly-Supervised Object Detection. CVPR2016
[2] XZ. Zhu, YJ. Wang, JF. Dai, Y. Lu, YC. Wei. Flow-Guided Feature Aggregation for Video Object Detection. ICCV2017
[3] YY. Lu, CW. Lu, CK. Tang. Online Video Object Detection using Association LSTM. ICCV2017
[4] FY. Xiao, YJ. Lee. Video Object Detection with an Aligned Spatial-Temporal Memory. ECCV2018
[5] SY.Wang, YC. Zhou, YJ.Yan, ZD. Deng. Fully Motion-Aware Network for Video Object Detection. ECCV2018
CVer-目标检测交流群
扫码添加CVer助手,可申请加入CVer-目标检测交流群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群
这么硬的干货分享,麻烦给我一个在在看

▲长按关注我们
麻烦给我一个在看!

