

强化学习(RL)提供了在游戏中寻找最佳策略的模拟方法。近年来,深度神经网络的发展为在更复杂的场景中使用 RL 提供了可能,例如 DeepMind 的 AlphaGo。我们将讨论在复杂战场模拟中使用深度强化学习的可能性。双方都可能有一个或多个角色。在给定的影响范围内,每个角色都会被分配一定数量的传感器特性和武器能力。对给定场景进行强化学习的神经网络训练有可能为这些场景提供最佳策略。此外,改变代表特定特征(如传感器范围或攻击能力)的参数值可能有助于确定战场上的战略重点。
在复杂的战场场景中,两个或两个以上的行动者自主行动,并根据传感器的输入做出决策,本文希望开发一种工具,用于寻找最优--或至少是良好或更好--的战术或策略,以完成预定任务。将实际场景限定为最终结局,即行动者的传感器和效应器相互影响的区域。就目的而言,传感器和效应器可以通过模拟器在对立行动者之间的模拟游戏中进行描述和表示。这种模拟游戏是观察和收集数据的来源。与现实生活中的测试和实验相比,模拟的成本要低得多。近年来,机器学习的发展和图形处理器(GPU)的计算能力与海量数据相结合,为研究此类问题提供了一套新的工具。由于很难甚至不可能获得复杂战场场景的大量数据,因此需要进行模拟观察。强化学习(RL)作为机器学习的一个子领域,已被证明能够在复杂的棋盘游戏中发挥超人的能力。新的吸引力来自于利用 RL 取得的几项成果,例如 DeepMind 的 1970 年代 ATARI 游戏;AlphaGo 的中国围棋战略游戏和 AlphaZero;或 AlphaZero 的国际象棋和将棋。每个角色都是在信息、传感器视野和可用武器射程受限的情况下进行模拟的。在每个时间步骤中,行为体也只能采取数量有限的可能行动。在使用 RL 配合决策制定过程时,信息状态和最佳决策之间的映射将逐渐得到加强。在这一过程中,最佳战略方针可能会显现出来。使用 RL 而非传统方法(即蒙特卡罗模拟)的优势在于,它有可能揭示一般政策。
这些策略可用于更通用的环境,而不是仅适用于某一特定场景的结果。通用策略可为多个领域的决策过程提供支持,例如战场机动或研究与创新方法。
本文的结构如下: 在第 2 节中,将论证 RL 终局的最优策略对于军事规划的重要价值。第 3 节是主要部分,包括方法和结果,其中介绍了 RL,包括游戏和行动者。对于行动者,我们描述了各个特征区域和决策区域,它们是终局分析的基本结构。给出了一个简短的概念演示,并介绍了一些挑战和未来工作。
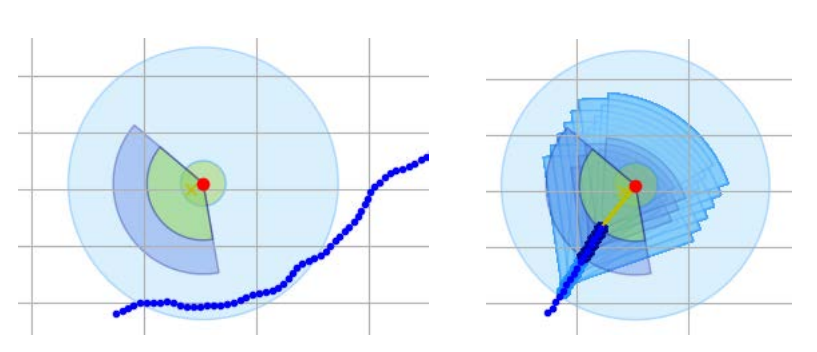
图 3-8:左边是一个失败的例子,以损失值作为奖励。右图是收敛学习后的成功案例。这两幅图都是从蓝色行动者的视角绘制的。


