摘要——多模态指代分割旨在根据文本或语音格式的指代表达,在图像、视频和三维场景等视觉场景中分割目标物体。这一任务在需要根据用户指令进行精准目标感知的实际应用中发挥着关键作用。过去十年间,得益于卷积神经网络、Transformer 以及大语言模型的快速发展,该任务在多模态领域受到广泛关注,极大推动了多模态感知能力的提升。本文对多模态指代分割进行了全面综述。我们首先介绍该领域的背景,包括问题定义和常用数据集。随后,总结了一种统一的指代分割元架构,并系统回顾了在图像、视频和三维场景三类主要视觉场景中的代表性方法。我们还进一步探讨了解决真实世界复杂性挑战的广义指代表达(GREx)方法,以及相关任务与实际应用。此外,文中还在标准基准上提供了广泛的性能对比。我们持续维护相关工作的追踪链接:https://github.com/henghuiding/Awesome-Multimodal-Referring-Segmentation。 关键词——综述,多模态指代分割,指代表达分割,指代视频目标分割,指代视听分割,三维指代表达分割,多模态学习,视觉-语言
1 引言
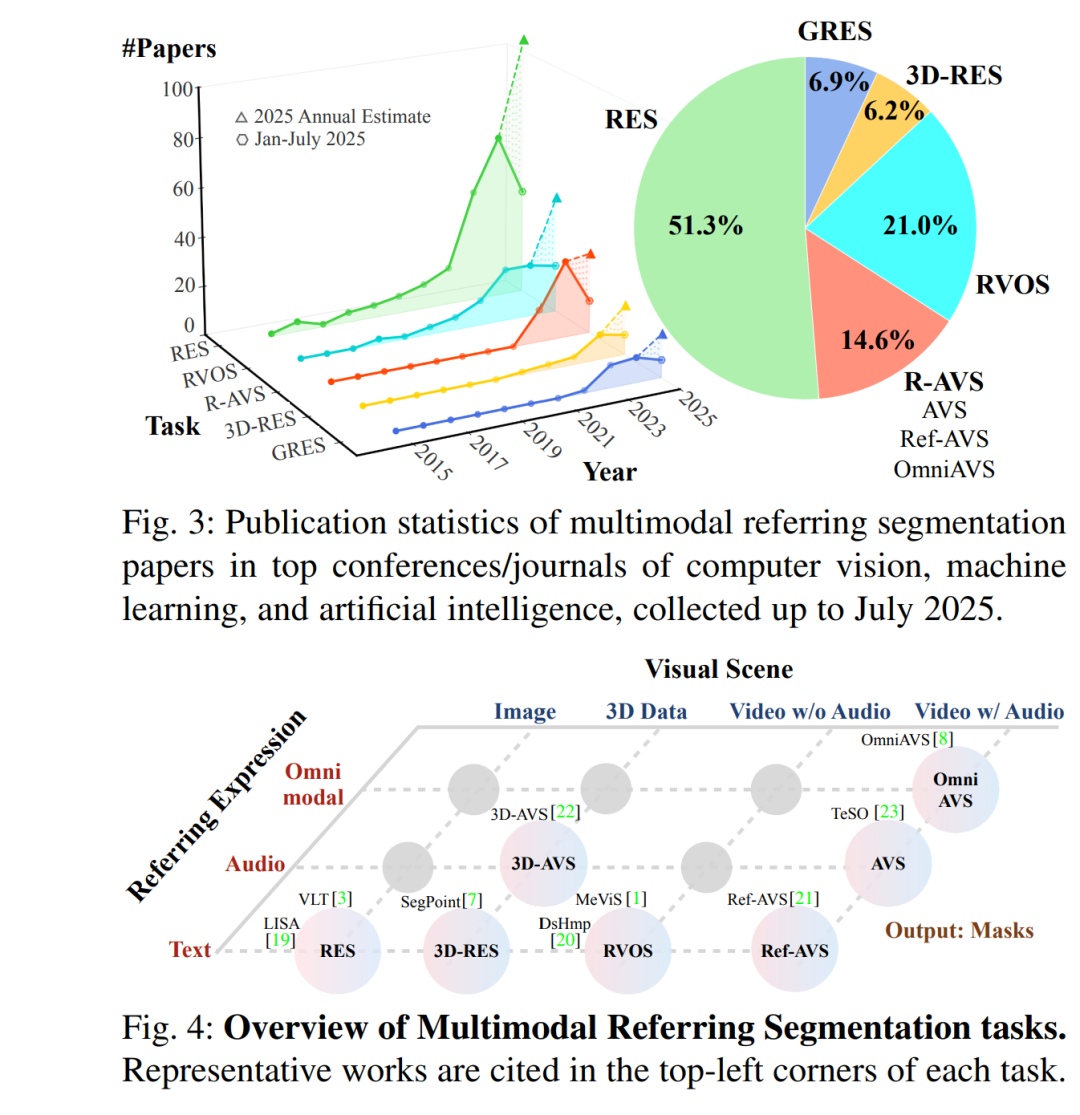
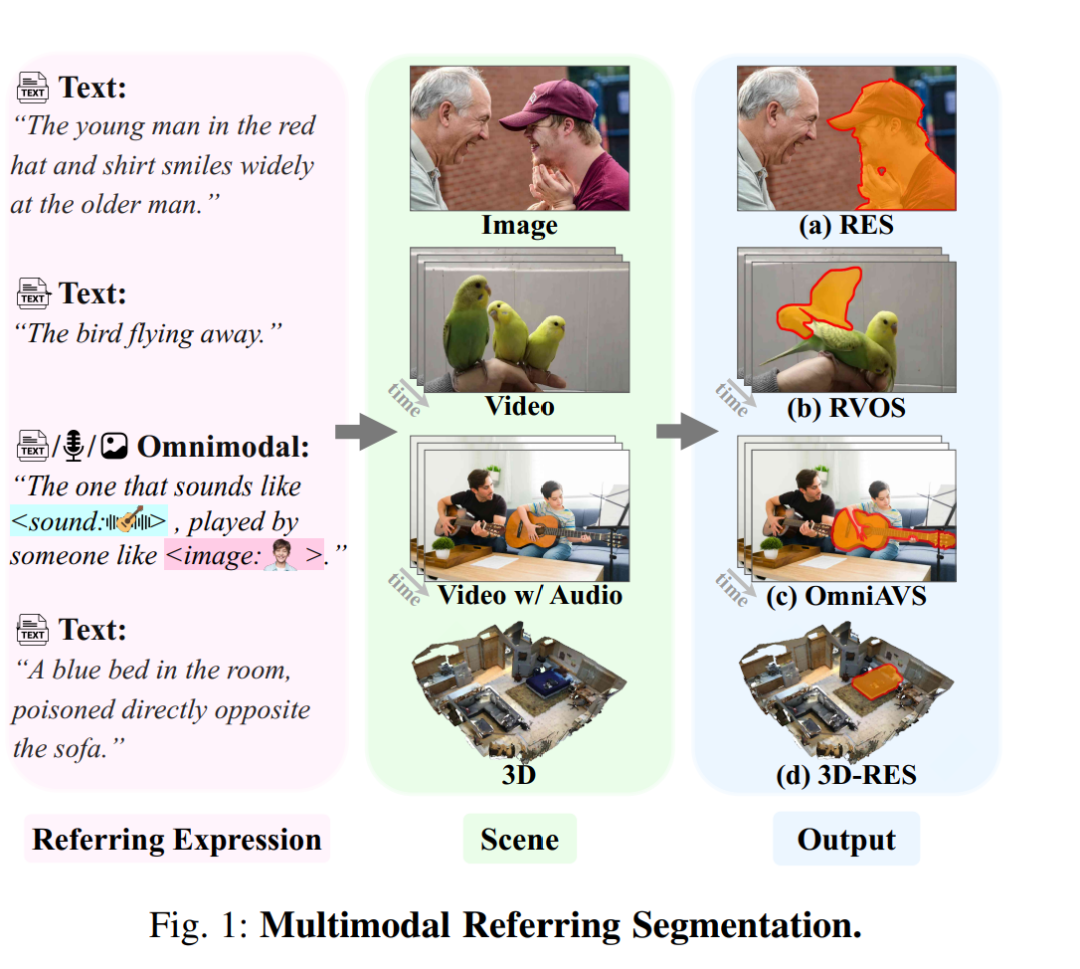
多模态指代分割(Multimodal Referring Segmentation)[1]–[7] 旨在根据指代表达(referring expression),如自由文本或音频,对图像 [2][3]、视频 [1][8] 或三维场景 [7][9] 中的目标对象进行分割。例如,如图 1(b) 所示,给定文本指代表达 “The bird flying away”,模型应能在视频中分割并跟踪所描述的目标对象。该任务是多模态理解中的一个基础且具有挑战性的问题,支持广泛的实际应用,如图像/视频编辑 [10][11]、机器人 [12]、自动驾驶 [13] 等。由于其在实际中的巨大应用潜力,多模态指代分割在近年来引起了越来越多的关注,如图 3 所示。 分割(Segmentation)[14]–[16] 是计算机视觉中的基本任务之一,构成了许多视觉理解任务和应用的基础 [17]。传统的分割方法,如语义分割(semantic segmentation)[14] 和实例分割(instance segmentation)[15],通常将视觉场景划分为一组预定义类别。尽管开放词汇分割(open-vocabulary segmentation)[18] 扩展了类别覆盖范围,但其仍依赖于显式的类别名称(如“人”、“车”等)。与这些经典分割任务不同,指代分割通过利用自由形式的指代表达,实现了更灵活、以用户为中心的分割,能够识别场景中的特定目标对象。 所谓指代表达,是一种人类可理解的语言表达方式,用于以任何能够唯一、明确指代对象的方式对其进行描述。这类表达不局限于类别命名,还可以涉及目标对象的位置、视觉属性、运动状态或与其他对象的关系。只要表达能够实现对目标的唯一识别,其描述策略均被视为有效。这种高度表达自由性带来了对细粒度多模态理解与对齐的重大挑战,也对模型在应对多样表达风格与语言-视觉变异方面的鲁棒性提出了更高要求。 根据指代表达的模态(如文本或音频)和视觉场景的类型(如图像、视频、视听视频或三维场景),指代分割任务可进一步细分,如图 1 所示。
尽管不同指代分割任务之间具有一定的共性,但现有综述文献 [24]–[28] 大多局限于特定模态或任务类型。例如,近期一篇综述 [29] 仅关注二维图像上的指代表达分割,忽略了对视频和三维场景的扩展。因此,当前文献仍存在关键空白,缺乏系统覆盖多样任务形式、输入模态与挑战的综合性综述。填补这一空白对于加深该领域理解、推动通用化和多模态方法的发展至关重要。 为此,我们对多模态指代分割领域中 600 多篇论文进行了全面回顾。本文旨在统一不同视觉场景下的多样指代模态,为该领域提供连贯、结构化的理解,以提升其可接近性并促进跨任务洞察。此外,我们也强调了指代表达技术在实际应用中的潜力,特别是在具身智能(Embodied AI)等新兴领域中的变革性作用。

综述范围:本文聚焦于图像、视频(包括显著性视频与视听视频)和三维场景三大类视觉场景中的指代分割研究,以及文本、音频与全模态(omnimodal)三种主要指代模态,如图 4 所示。我们主要回顾基于深度学习的方法,重点介绍发表于顶级会议和期刊的代表性研究成果,并纳入具有前瞻性的近期预印本,以反映新兴趋势与未来方向。 * 文章结构:如图 2 所示,本文结构如下:第 2 节介绍任务定义与常用数据集;第 3 节提出统一的指代分割元架构;在该架构下,第 4 至第 7 节系统回顾图像、视频与三维场景中的代表性方法。第 8 节讨论面向真实复杂场景的广义指代表达(GREx)方法;第 9 节探讨相关任务与应用;第 10 节为总结与未来讨论。附录中还提供了基准性能对比结果。