

摘要——理解和复现真实世界是人工通用智能(AGI)研究中的关键挑战。为实现这一目标,许多现有方法(如世界模型)试图捕捉物理世界的基本规律,以实现更精确的模拟和更有意义的交互。然而,当前的方法通常将不同模态(包括2D图像、视频、3D和4D表示)视为独立的领域,而忽略了它们之间的相互关联。此外,这些方法通常仅关注现实世界的某个孤立维度,而未能系统性地整合它们的联系。因此,在本综述中,我们提出了一个统一的多模态生成模型综述,研究数据维度在真实世界模拟中的演进过程。具体而言,我们从2D生成(外观)出发,扩展到视频生成(外观+动态)和3D生成(外观+几何),最终达到整合所有维度的4D生成。据我们所知,这是首次尝试在单一框架内系统性地统一2D、视频、3D和4D生成的研究。为引导未来研究,我们提供了对数据集、评测指标和未来方向的全面回顾,并为初学者提供深入见解。本综述旨在作为一座桥梁,推动多模态生成模型与真实世界模拟在统一框架下的发展。 索引词——生成模型,图像生成,视频生成,3D生成,4D生成,深度学习,文献综述
【2 基础知识】 本部分对深度生成模型的基本原理做了简要回顾。论文中介绍的各类生成模型都旨在通过深度神经网络近似真实数据的分布。文中详细讨论了几种主流模型:
- 对抗生成网络采用生成器与判别器相互博弈的方式,使得生成样本逐步逼近真实数据;
- 变分自编码器通过构建编码和解码网络,并借助变分推断思想,对数据进行低维压缩与重构,尽管存在后验坍缩与生成图像模糊的问题;
- 自回归模型将多维数据分解为条件概率的乘积,从而使得每一步的生成都依赖于前面生成的内容,虽然这一方法便于明确建模概率密度,但并行化能力较弱;
- 正则化流模型利用可逆网络将简单分布映射到复杂数据分布,虽然能够明确计算概率密度,但其表达能力存在一定限制;
- 扩散模型则通过逐步添加噪声和逆过程重建数据,实现高质量样本生成,但相对计算过程较为昂贵。
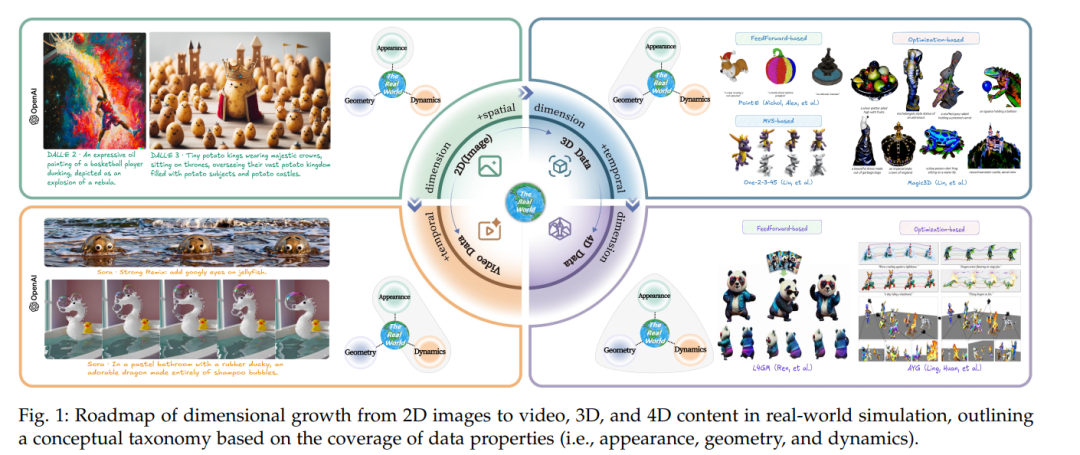
──────────────────────────── 【3 各范式下的真实世界模拟】 论文按照数据维度的增长,系统地将真实世界模拟划分为四个层次,即二维生成、视频生成、三维生成和四维生成,每个层次均着眼于不同的属性建模。 【3.1 二维生成】 在二维生成部分,重点讨论了文本到图像的生成技术。利用扩散模型、预训练语言模型及自编码器等技术,现有方法已能够从文本描述中生成高质量、语义准确的图像。论文中详细介绍了Imagen、DALL-E、DeepFloyd IF、Stable Diffusion及其扩展版本(如SDXL和FLUX.1)等模型,这些模型通过多阶段生成、跨模态编码以及高效的降噪技术,在图像外观建模方面取得了显著成效。

【3.2 视频生成】 视频生成技术在二维图像生成的基础上增加了时间维度,面临更高的时空一致性要求。论文将当前视频生成方法归纳为基于变分自编码器与对抗生成网络、基于扩散模型以及自回归模型三大类:
- 基于变分与对抗方法的研究通过分离内容与运动分量来实现视频帧的连续合成;
- 扩散模型则在原有图像生成架构上进行扩展,引入时空联合训练和多分辨率超分辨技术,确保生成视频在运动和细节上都具有高保真性;
- 自回归方法通过将视频帧编码成离散的潜在符号序列,再对这些序列进行建模,从而在多模态信息(如文本、图像和音频)的协同作用下完成视频生成。论文同时指出,视频生成在视频编辑、视角合成及人物动画等应用中具有广泛前景,并详细讨论了相关技术的优势与不足。
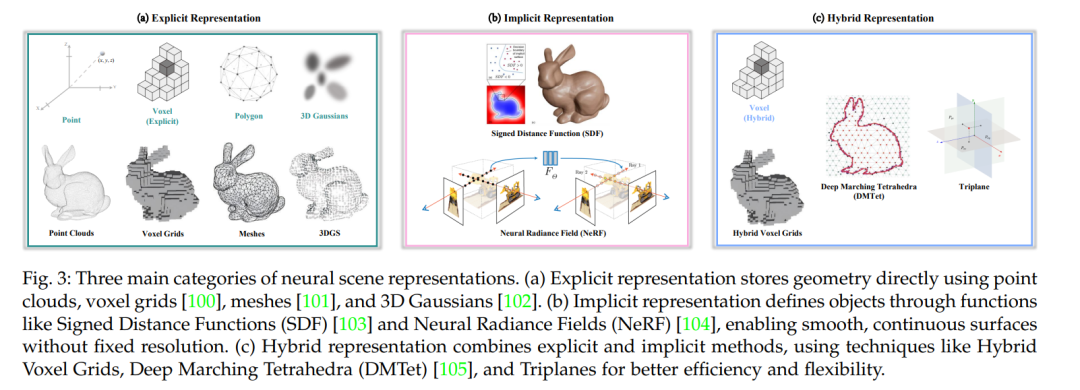
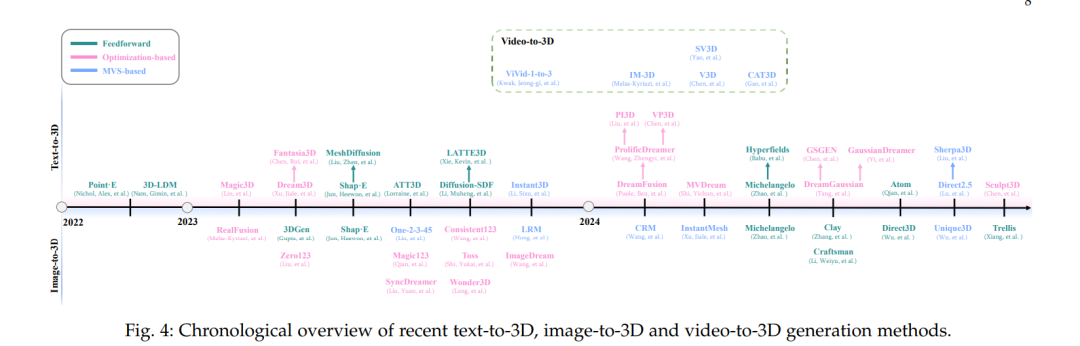
【3.3 三维生成】 三维生成部分主要关注对物体几何和外观信息的全面建模。论文首先讨论了三维数据表示方式,分为明确表示(如点云、体素网格、网格模型和三维高斯分布)、隐式表示(通过连续函数描述物体表面,如符号距离函数与神经辐射场)以及混合表示(结合前两者优点,通过混合体素或基于四面体网格等方法实现高效表达)。在算法层面,论文介绍了文本到三维生成、图像到三维生成以及视频到三维生成三种任务。 (1)在文本到三维生成中,有两大类方法:一种是前向传播方法,直接从文本编码中得到紧凑的三维表示;另一类是基于优化的方法,通过利用文本到图像的预训练模型产生中间视角,再借助扩散模型或其他损失函数进行三维结构的精细化优化。 (2)图像到三维生成主要利用已有图像数据,通过编码压缩网络和生成模型得到符合输入图像特征的三维资产; (3)视频到三维生成则利用视频中的多视角信息,通过时空一致性训练,生成既具有细节又满足多视角约束的三维结构。论文中对各类方法的优缺点进行了详细比较,并讨论了如何利用大规模三维数据集以及多视角预训练模型来提高三维生成的精度和一致性。
【3.4 四维生成】 四维生成则是在三维生成的基础上进一步引入时间维度,用以描述动态场景的演变。此部分面临空间连续性和时间一致性的双重挑战。论文介绍了四维数据表示方法,包括基于静态三维表示扩展时间信息、采用时空分解与哈希映射等技术以降低重建单个场景的计算成本。当前,四维生成主要分为两类方法:
- 前向传播方法依赖于预训练模型,结合时空先验一次性生成动态场景,适用于实时交互与轻量部署;
- 基于优化的方法则采用迭代式调整(例如利用分数蒸馏损失)对预训练扩散模型进行细化,以生成在运动动态上更为逼真的四维场景。论文对这些方法在效率、视觉质量与场景灵活性等方面进行了系统讨论,并提出了未来改进的方向。
──────────────────────────── 【4 数据集与评测指标】 论文还对真实世界模拟中常用的数据集与评测指标做了综述。针对二维、视频、三维和四维生成,不同任务所采用的数据集具有各自特点,如大规模图文数据集、视频编辑数据集以及用于三维重建和视角合成的专用数据集。同时,评测指标不仅包括图像质量、视频时空连贯性,还涵盖三维模型的几何精度、表面细节以及多视角一致性等多个方面。对这些指标的详细比较和应用场景的讨论为后续研究提供了重要参考。 ──────────────────────────── 【5 未来方向与挑战】 尽管当前多模态生成模型在模拟真实世界方面已取得显著进展,但论文仍指出存在若干开放性挑战: 一是如何在保证生成内容高保真和细节丰富的前提下进一步提高生成速度与计算效率; 二是如何在多模态、多维度之间建立更加紧密的联系,克服单一维度模型带来的局限; 三是如何借助更大规模、更高质量的数据集,推动文本、图像、视频到三维乃至四维生成方法的统一与协同; 此外,在应用层面,如虚拟现实、自动驾驶、机器人等场景中对生成模型的鲁棒性、实时性以及交互性提出了更高要求,这些均为未来研究的重要方向。 ──────────────────────────── 【6 结论】 本文系统性地综述了多模态生成模型在真实世界模拟中的研究进展,详细讨论了从二维到四维生成的各个技术范式。通过对比传统图形学方法与基于深度学习的生成模型,论文不仅明确了当前各类方法的优势和局限,也为未来研究指明了方向。总体来说,本综述为研究人员提供了一个统一的视角,帮助大家在跨模态、跨维度的真实世界模拟领域进行更深入的探讨和创新。