

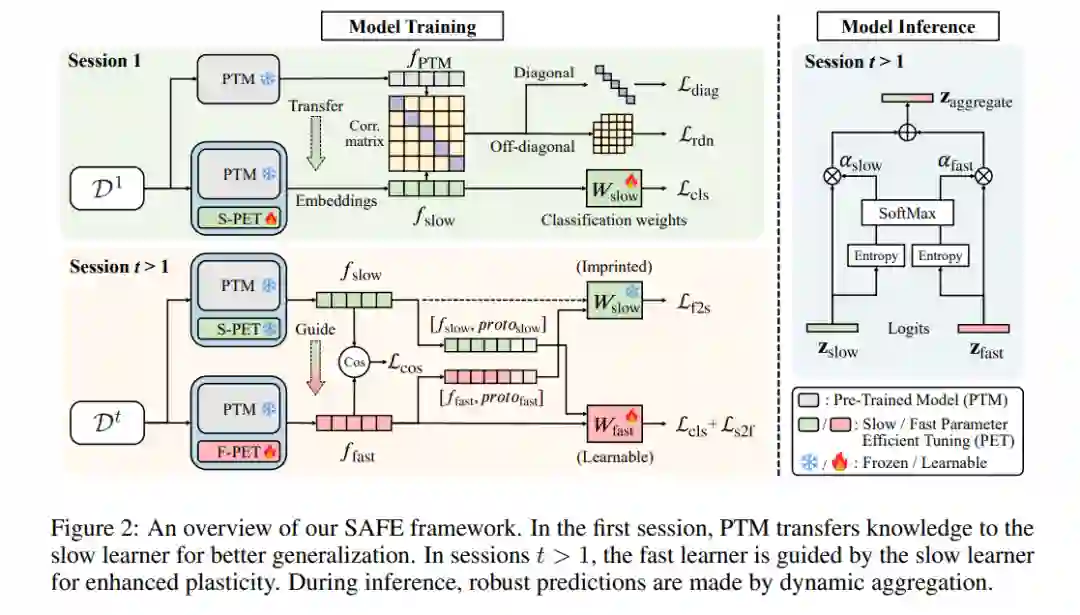
持续学习旨在从数据流中逐步获取新概念,同时避免遗忘先前的知识。随着强大**预训练模型(PTMs)的兴起,越来越多的研究关注如何使用这些基础模型来训练增量学习系统,而不是从头开始学习。现有的研究通常将预训练模型视为一个强大的起点,并在第一阶段直接应用参数高效调优(PET)**以适应下游任务。在随后的阶段,大多数方法会冻结模型参数,以解决遗忘问题。然而,直接将PET应用于下游数据并不能充分挖掘预训练模型中的固有知识。此外,在增量学习阶段冻结参数会限制模型对第一阶段未涵盖的新概念的适应性。
为了解决上述问题,我们提出了一个慢速与快速参数高效调优(SAFE)框架。具体来说,为了继承基础模型中的通用知识,我们通过衡量预训练模型与应用PET后的模型之间的相关性,加入了一个迁移损失函数。在第一阶段进行校准后,慢速高效调优的参数能够捕捉到更多的信息特征,从而提高对后续类别的泛化能力。此外,为了进一步融入新概念,我们在稳定性和适应性之间找到了平衡,通过固定慢速高效调优参数并持续更新快速参数来实现这一目标。具体而言,我们提出了一种跨分类损失与特征对齐方法,用以规避灾难性遗忘。在推理阶段,我们引入了一种基于熵的聚合策略,动态地利用慢速和快速学习者之间的互补性。 在七个基准数据集上的广泛实验验证了我们方法的有效性,显著超越了当前的最新技术。代码将在 https://github.com/MIFA-Lab/SAFE 上发布。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
相关主题


相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日