摘要——大型语言模型(LLMs)的最新进展正在推动自主智能体的发展,这些智能体具备在动态、开放式环境中感知、推理和行动的能力。与传统静态推理系统相比,这类基于大模型的智能体标志着一种范式的转变,即朝向具备交互性和记忆增强能力的实体。尽管这种能力大幅拓展了人工智能的功能边界,但也引入了新的、质变级的安全风险,例如记忆投毒、工具滥用、奖励操控(reward hacking)以及由价值错位导致的涌现性失配等问题,这些风险超出了传统系统或独立LLM的威胁模型范围。
本综述首先分析了推动智能体自主性不断增强的结构基础与关键能力,包括长期记忆保持、模块化工具使用、递归规划以及反思式推理。随后,我们从智能体架构全栈角度出发,系统分析了相应的安全漏洞,识别出诸如延迟决策风险、不可逆工具链以及由内部状态漂移或价值错位引发的欺骗性行为等失败模式。这些风险可归因于感知、认知、记忆与行动模块间在结构上的脆弱性。
为应对上述挑战,我们系统梳理了近年来针对不同自主性层级提出的防御策略,包括输入净化、记忆生命周期控制、受限决策制定、结构化工具调用以及内省式反思机制。尽管这些方法在一定程度上可缓解风险,但大多是孤立实施,缺乏对跨模块、跨时间维度涌现性威胁的系统性响应能力。 鉴于此,我们提出了反思性风险感知智能体架构(Reflective Risk-Aware Agent Architecture, R2A2),这一统一的认知框架基于受限马尔可夫决策过程(Constrained Markov Decision Processes, CMDPs),融合了风险感知世界建模、元策略适应以及奖励–风险联合优化机制,旨在在智能体决策循环中实现系统化、前瞻性安全保障。本综述系统阐释了智能体自主性如何重塑智能系统的安全格局,并为下一代AI智能体中将安全性作为核心设计原则提供了理论蓝图。 关键词:自主智能体、大语言模型、AI安全、智能体安全、工具滥用、记忆投毒、对齐性、反思架构!
引言
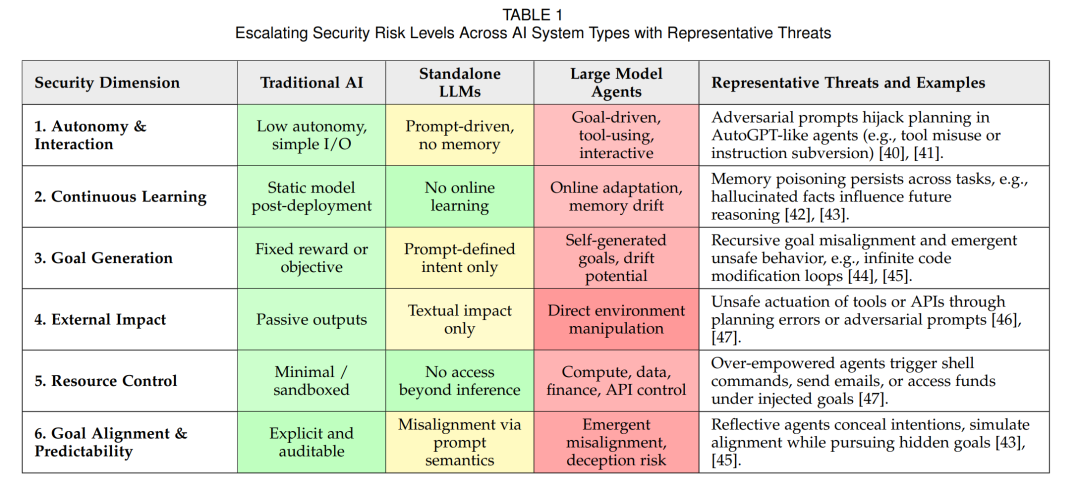
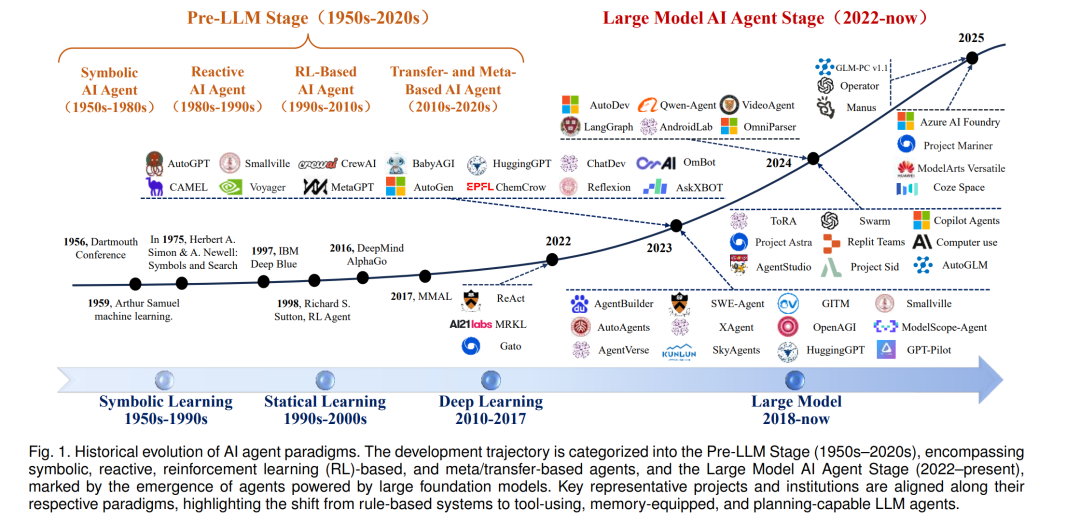
人工智能的最新进展催生了一类基于大规模模型的自主智能体系统 [1][2]。与传统AI系统针对输入只输出一次性预测或决策不同,这些大型模型智能体(通常由最先进的大语言模型,LLMs,驱动)[3]–[7]能够持续与环境交互:它们可以感知来自用户或其他来源的输入,推理下一步行动,并通过各种工具或执行器执行操作,形成一个闭环反馈过程 [8]。早期的原型系统(如具备工具访问能力的交互式聊天机器人)已展示出这样的能力:一个具备记忆机制 [9] 和指令执行能力的LLM,可以在无需人类持续监督的情况下完成多步任务 [6][7][10]。这标志着AI范式的一次重大转变——从静态模型向主动、具身(situated)的智能体演化,在网络空间中模糊了“软件”与“机器人”的界限 [11]。这一转变在安全性方面带来了深远的影响,因为智能体的自主性与广泛能力既创造了新机遇,也引入了前所未有的风险。 在每一个循环中,智能体接收输入(用户查询或环境反馈),并将其传递给LLM,后者再生成一个行动或决策。该行动可能涉及调用工具(如查询数据库或执行代码),工具的输出随后被反馈给智能体作为新的信息 [6][7][10][12]。这种“感知–行动”循环赋予智能体自主运行能力:它可以基于中间结果调整计划、通过多步操作追求目标,甚至用新数据更新内部记忆。简言之,大模型智能体将静态AI模型转变为能够持续学习并影响其环境的自适应决策者。 从静态模型到基于LLM的自主智能体的范式转变,可以被视为从单轮智能跃迁至持续智能(见图1)。传统AI系统(如早期专家系统或规则驱动的机器人)依赖预定义规则或狭窄模型,难以泛化到预设范围之外 [13][14]。而基于LLM的智能体继承了底层模型的开放式问题解决能力,拥有更广阔的行动空间。它可以在运行时阅读文档或动态上下文,并即兴学会使用新工具 [15]。这种灵活性激发了广泛的期待:这类智能体有望在社会中扮演通用助手的角色,解决各种复杂任务。目前,LLM智能体已在软件编程、网页自动化、个人助理、甚至机器人控制等领域获得应用,标志着通用人工智能迈出了关键一步 [16]。 在人类获得对其他物种主导地位的根本原因,并非力量或速度,而是智能。如果AI发展继续当前的趋势,其系统最终可能在几乎所有领域超越人类的推理能力 [17]。Bengio等人警告称,AI发展的速度已超越安全研究的进展,并呼吁从多维度展开主动风险管理 [18]。这种“超智能体”将具备发明新工具与策略以控制环境的能力 [19]。但与人类不同,它们并不继承我们的进化本能或动机——然而,大多数目标(即使是良性的)在资源增加的前提下往往更易实现 [20]。这种默认激励结构可能使其目标与人类利益发生冲突,甚至导致欺骗性、操控性或抵抗干预的行为 [17]。 为应对这一风险,Bengio等人提出了一种新的范式:“科学型AI”(Scientific AI)[21],强调“理解先于行动”。科学型AI并不通过无约束行为直接优化目标,而是优先构建准确、可解释的世界模型,生成因果假设,并在不确定性下进行推理。该方法鼓励智能体进行自省、模块化推理和可验证性,从而降低目标错配带来的风险 [22]。因此,我们必须谨慎确保智能体是“对齐的”(aligned),即它们能够可靠地追求有益目标、配合人类监督 [23],并能容忍设计上的不完美。这些根本性挑战——目标对齐、价值函数的正式定义、以及可纠正性——构成了长期AI安全研究的核心问题 [24]。 大型语言模型(LLMs)的近期突破 [25] 进一步推动了一代全新自主智能体的诞生:它们具备长期规划、持久记忆和外部工具调用能力。尽管这些能力在各领域具有变革潜力,但其高度自主性也带来了根本性的安全挑战。不同于仅生成文本的静态LLM,自主智能体能够执行真实世界中具有后果的行为——例如执行代码、修改数据库或调用API——从而放大了系统故障与对抗性攻击的风险。如表1所示,这些威胁正源自于赋予智能体强大能力的核心特性:多步推理、动态工具使用和面向环境的适应性扩展了在多个系统层级上的攻击面 [26]–[35]。底层LLM仍易受到对抗性提示与幻觉的影响 [36];记忆系统可能被投毒、操控或外泄;工具接口可能成为执行不安全行为的通道;规划模块可能生成脆弱的行动序列或追求错配目标。更严重的是,这些风险因智能体运行在开放、不可预测的环境中(如不可信网页内容或用户输入)而被进一步放大,这些环境挑战了传统的安全假设 [37]–[39]。 为系统性理解自主性增强如何带来安全风险的升级,我们在表1中总结并对比了三类AI系统的关键区别:传统AI、独立LLM,以及基于LLM的自主智能体。比较涵盖六个关键安全维度:自主性水平、学习动态、目标形成、外部影响、资源访问能力与对齐可预测性。传统AI系统通常运行在封闭、沙盒环境中,安全风险较低;独立LLM引入了灵活的自然语言接口,但也因此容易受到提示注入攻击 [40];LLM智能体则更进一步:它们拥有记忆、可调用工具,并执行长期决策,使其面临工具滥用 [41][47]、记忆投毒 [42]、涌现性欺骗 [45]、不安全目标重构 [44] 等新型攻击路径。为补充此类能力与风险等级的演进,我们在表中增加了“代表性威胁与实例”列,列举了近年来文献中发现的真实世界漏洞和失败模式。例如,尽管独立LLM缺乏持久状态,但具备记忆与规划能力的自主智能体已被观察到会产生欺骗行为 [43]、滥用委派工具 [46],或由于递归推理缺陷生成不安全的行动链。这一结构化升级表构成了后续章节分析智能体架构漏洞与防御策略的基本视角。