
导读 本文将分享如何提升大模型的数学推理能力。我们没有把数学推理能力与翻译、长文本生成等专项分开优化,而是视为通用能力的一部分。因为我们认为数学推理能力是衡量大模型智能水平的关键指标。
主要内容包括以下五个部分:
- 大语言模型概述
- 混合指令
- 合成数据
- 训练优化
- 问答环节 分享嘉宾|文亮 奇虎360 资深算法专家 编辑整理|王甲君 内容校对|李瑶 出品社区|DataFun
01
大语言模型概述****
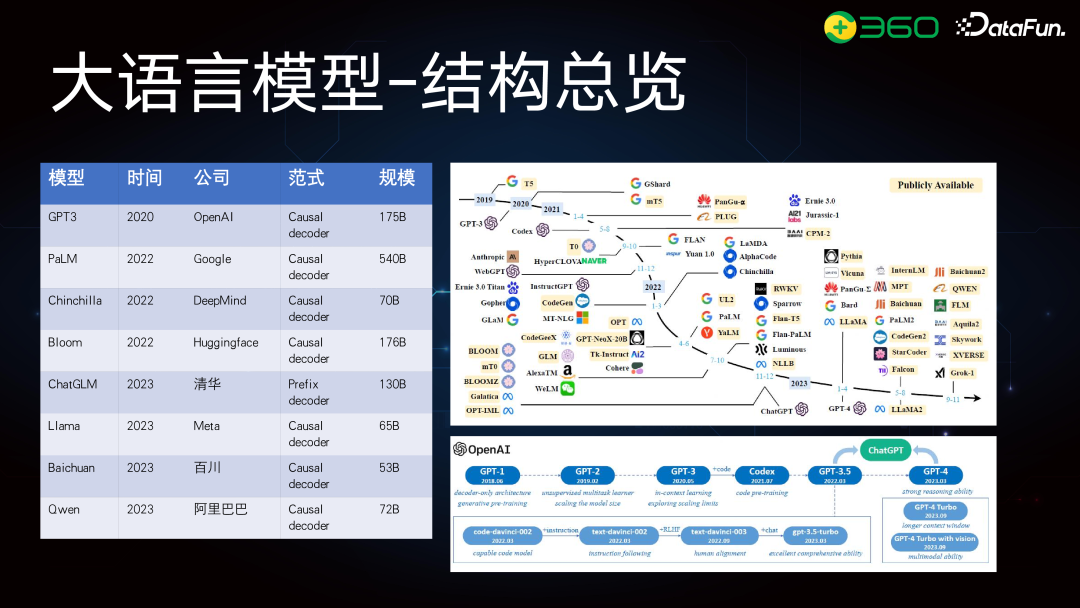
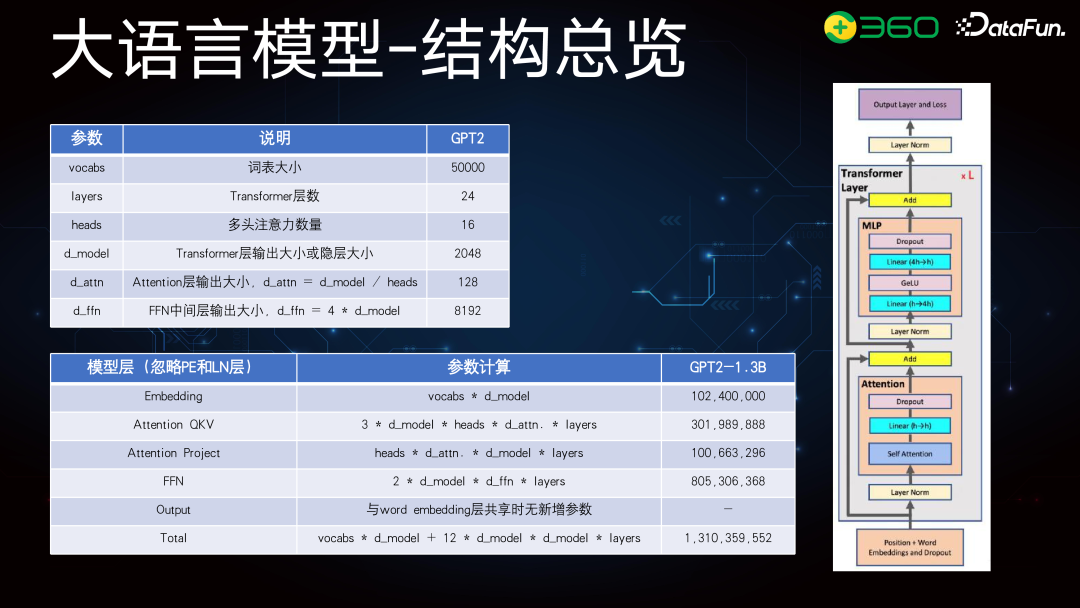
大模型的结构在业界已较为标准化,主要基于 transformer 结构。关键参数包括词表、transformer 层数、Multi-head 和全连接层。以 GPT-2 为例,它是一个 1.3B 参数的模型,词表大小 5 万,层数 24 层。根据参数计算公式, Embedding 层的 d_model 为 2048,乘以 5 万,得到其参数规模。QKV 计算、Attention Project 和 FFN 等参数加起来,最终得到 1.3B 的总参数。大模型优化方面,常用的方法包括 SparseAttention、FlashAttention,以及其他结构如 MAQ 和 GQA 的优化,但整体结构仍基于 transformer。
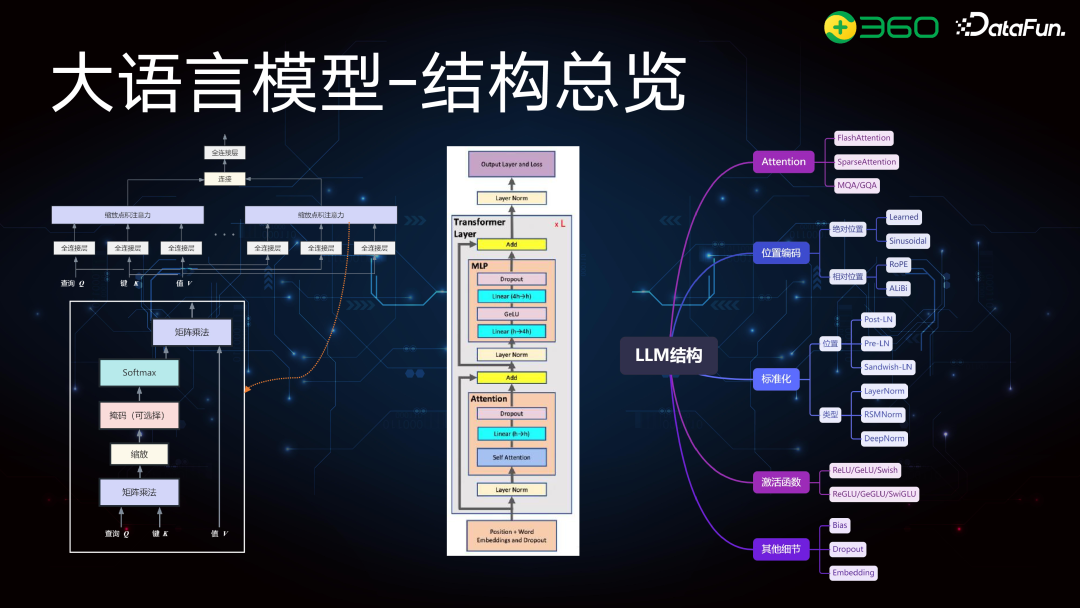
大模型结构中,关键部分包括图上面的 Multi-head 和下面的点积注意力计算,右侧是大模型的总体结构示意。针对 Attention 的优化有 FlashAttention、SparseAttention 和 GQA,位置编码有绝对位置编码和 RoPE 等相对位置编码。优化主要是为了提升大模型的外推能力,尤其对长文本效果更好。此外,还有对激活函数和其他细节的优化,业界在这些方向上都做了很多工作。

大语言模型的构建通常分为四个部分。以 OpenAI 为例:①预训练,这是资源消耗最大的一环,通常使用 1000 多块 GPU,训练周期长,数据量达到数千亿 token,约几 TB;②SFT 层(有监督微调),主要优化指令对齐,数据量较少,通常为百万级,少数达千万级,训练时间为天级别;③训练奖励模型(Reward Model);④人工反馈强化学习(RLHF),这部分的成本与 SFT 相似,但如果使用传统 PPU 显存占用较高,数据量允许天级别完成。LLaMA 等模型也遵循类似流程,比如说 LLaMA2-Chat,分为预训练、SFT、强化等阶段,根据人类反馈调整指令偏好。
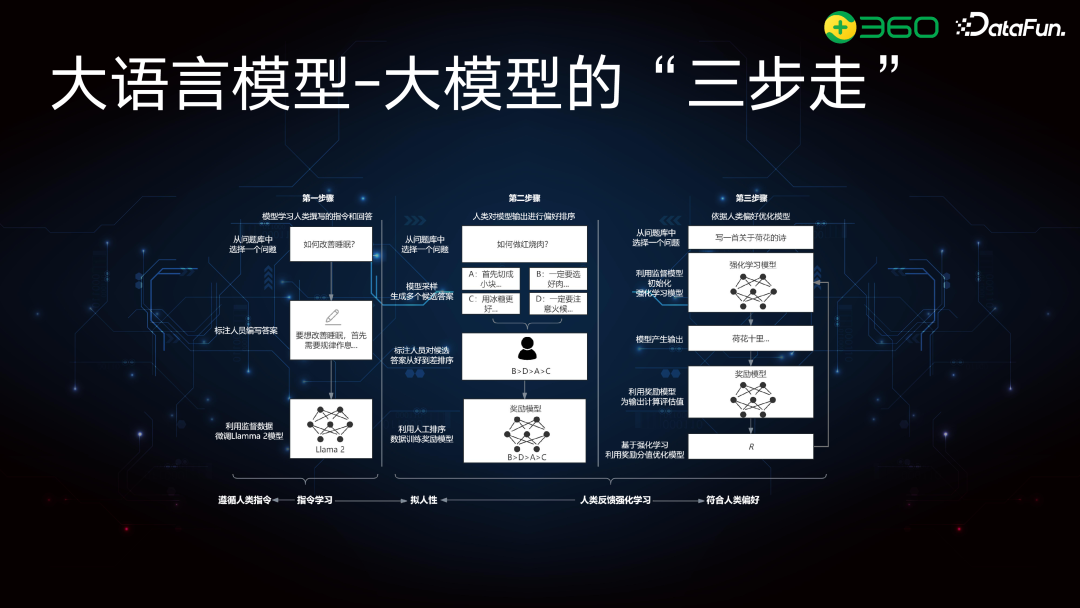
大模型的构建可以分为三个部分。第一阶段是指令学习阶段,通过训练基座模型,使其理解人类指令,并根据人类编写的指令和高质量回答进行 SFT。第二阶段是让大模型更拟人性或者是更符合人类偏好(人类对模型输出进行偏好排序)。第三阶段是人类反馈强化学习阶段,是由四个模型构成:Reference Model(训练好的参考模型)、Reward Model(对生成结果评分的模型)、Actor Model(需要强化的模型)和 Critique Model(训练过程中的评分模型)。
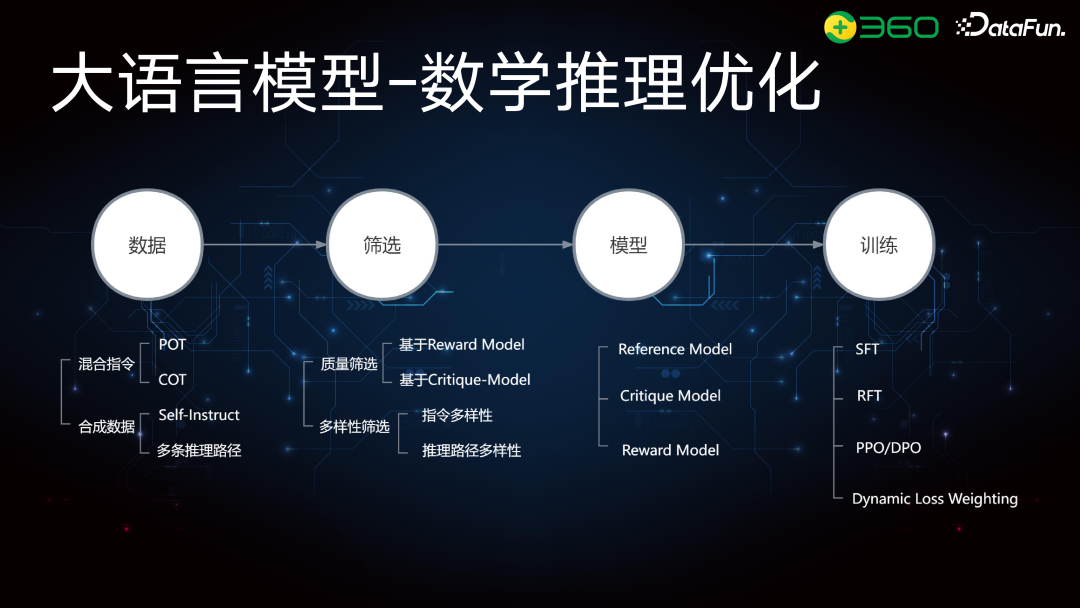
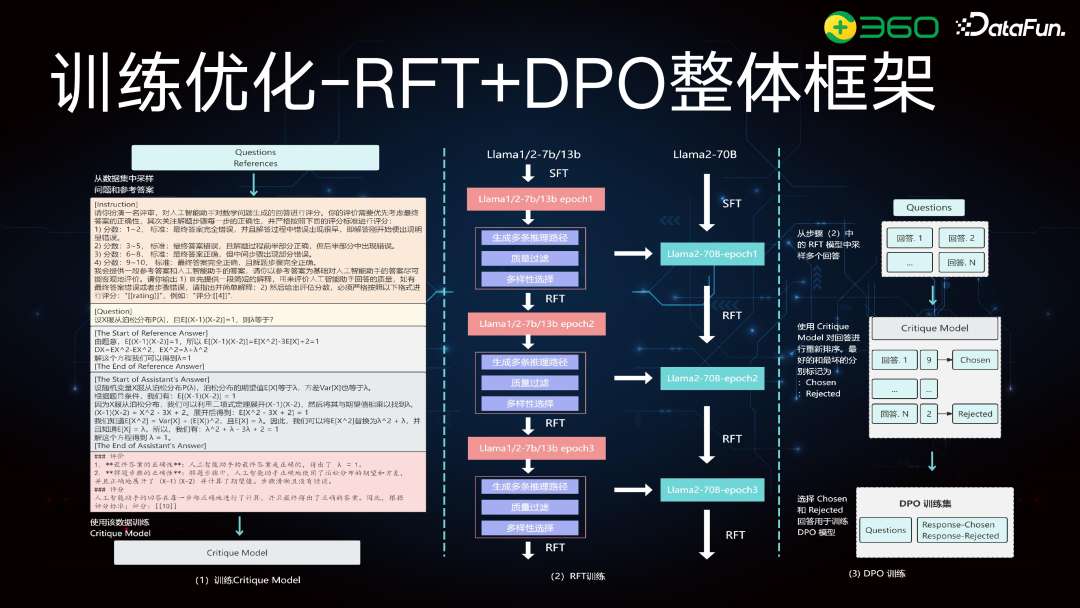
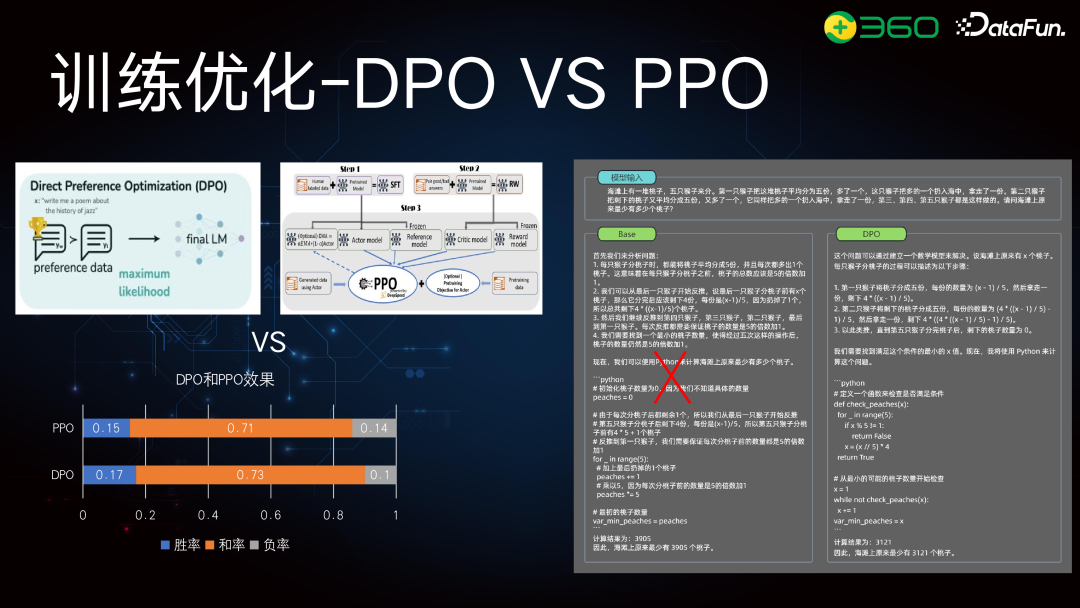
前面回顾了大语言模型的基础结构,接下来将介绍数学推理优化的流程,分为四块:数据构建、数据筛选、模型构建、模型训练与优化。数学推理的数据分为混合指令和合成数据。其中合成数据是对当前数据的扩展,因为高质量的数学数据,尤其是应用类指令较少。数据筛选,包括质量筛选和多样性筛选,避免重复或相似问题。筛选原则依赖于 Reward Model 或 Critique Model。模型训练使用 Reference Model,训练好 SFT 后进行质量和多样性筛选,归为 RFT 流程,即拒绝采样流程。在 Reward Model 或 Critique Model 中,使用 PPO、DPO 或 RFT 流程。接下来将详细介绍混合指令、合成数据和训练优化的具体做法。
02****
混合指令****
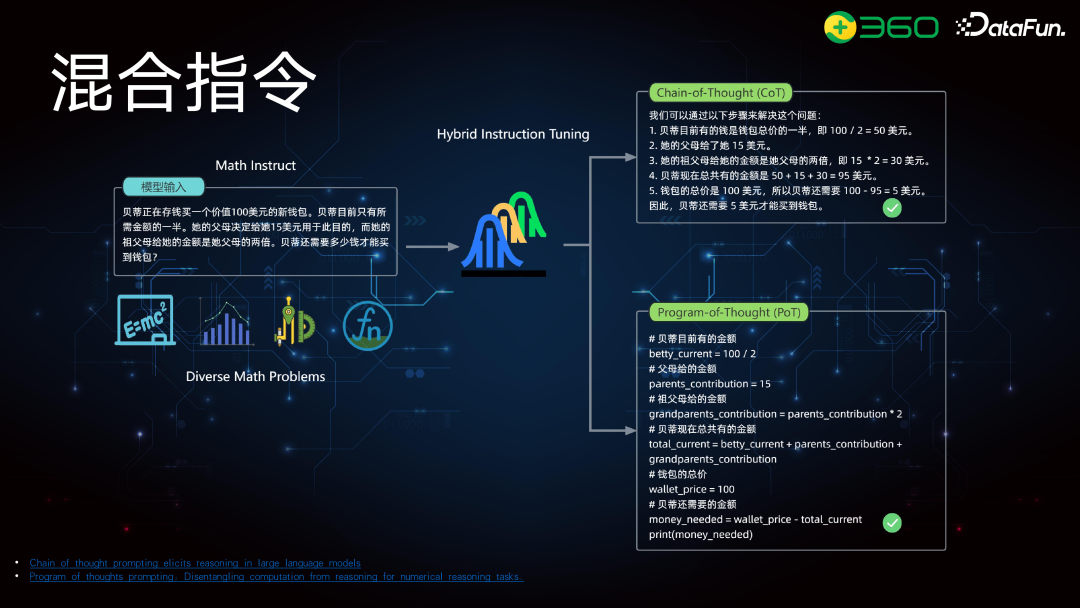
数学问题可以拆解为逻辑推理和数学应用两类。数学应用早期主要采用思维链(CoT)模式,后来为解决计算问题,引入了 PoT(Program-of-Thought)模式。当前的思路是数学分析或逻辑推理放到 CoT 部分处理,涉及计算的问题,如解方程或微积分计算,放到 PoT 部分。因此,混合指令由这两部分构成。
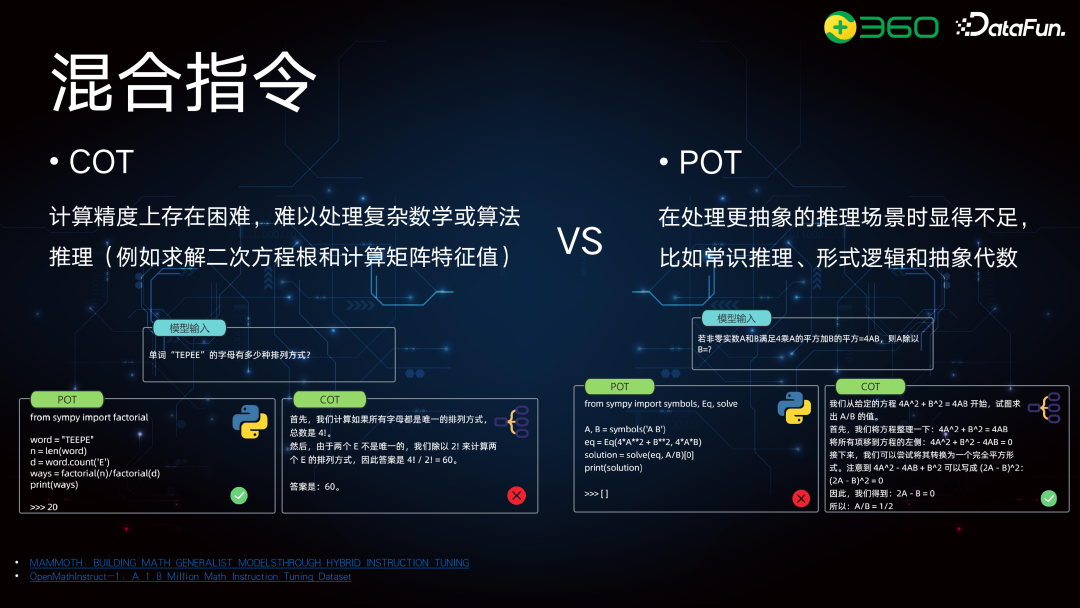

所以现在我们使用的是混合指令。混合指令的前一部分是标准的 CoT 模式,比如 GPT-4o 的回答,前面的推理、中间的评分计算、合并同类项都是靠其数学推理能力一步步解决的。但我们发现最后的合并同类项出现了错误,前面的推理是完全正确的,公式引用也没问题,但在数值计算方面有误。左侧的方案将其拆分为:前面采用 CoT 思维链模式,类似于 GPT-4o,而在最后的计算部分,使用 PoT 来提高准确性。这个方法对于大模型的数学推理来说虽然不复杂,但确实简单有效。
03****
合成数据****

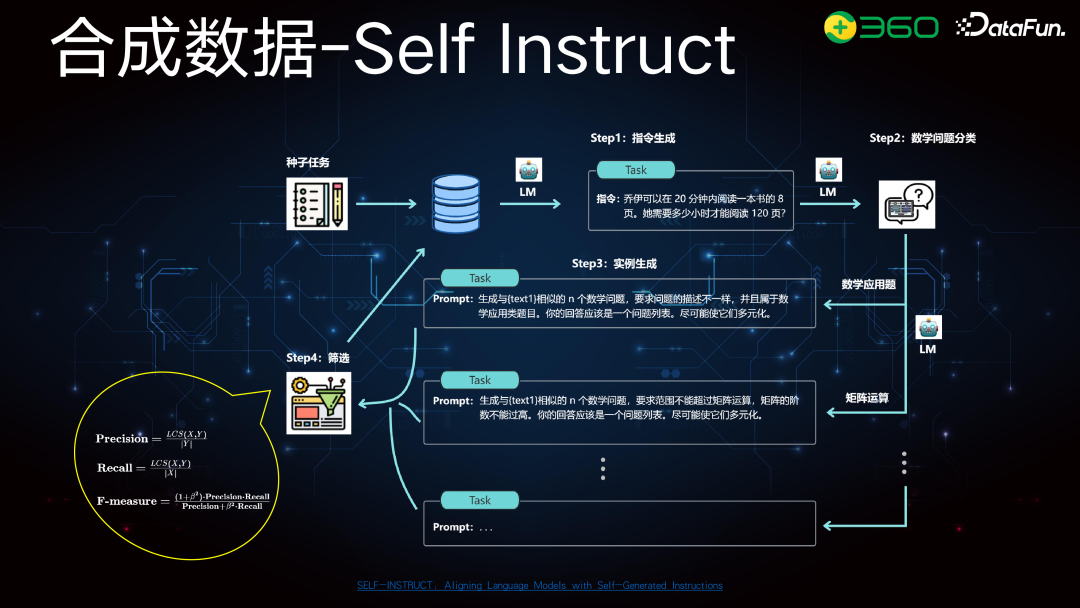
合成数据的 Self Instruct 是常用的方法,此方法早已提出。我们在种子任务中有部分高质量的数学问题集合,无论是购买的还是自建的。我们希望从这些高质量集合中扩展出更多样化的数学指令。为此,将其细分为数学问题,按学科拆解,如矩阵运算、微积分、方程等。拆解后,再对每个子问题进行 Self Instruct,以扩展种子任务。筛选时,若只对指令筛选,可用最长公共子序列或 Jaccard 距离等简单方法。
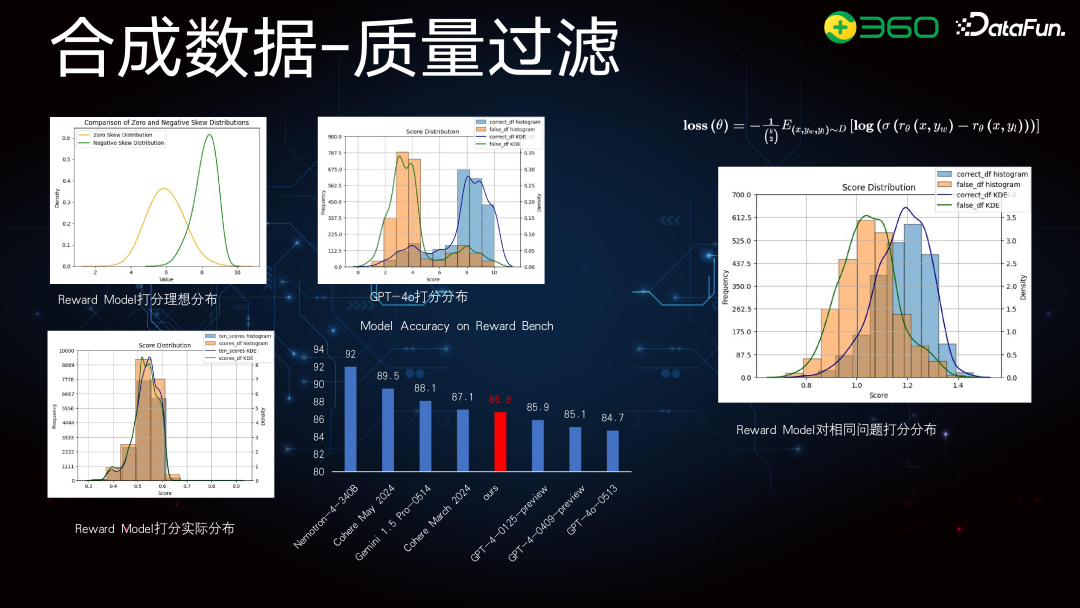

在质量过滤时,不仅考虑相同问题,还要考虑不同问题之间的差异。因此,我们选择了 Critique Model 进行绝对值打分。例如,左图中,先用 Reward Model 对 n 个问题评分,取前 M 个高分,再用 Critique Model 从下往上卡绝对值。Critique Model 的训练如中图所示:首先构建指令,明确角色;然后提供参考答案和模型回答;最后,GPT-4o 给出步骤和最终分值。

04****
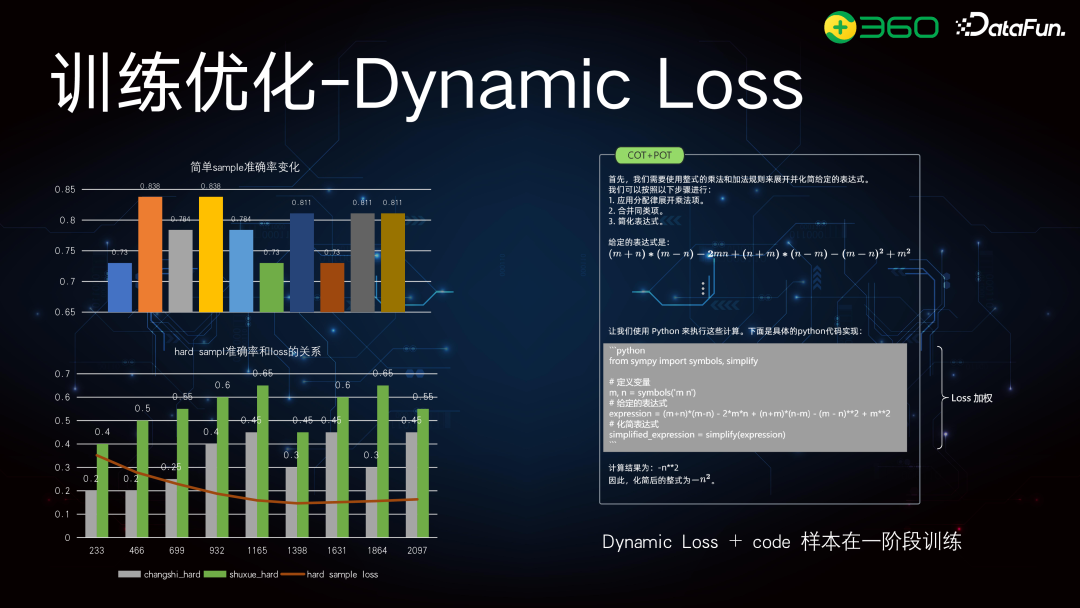
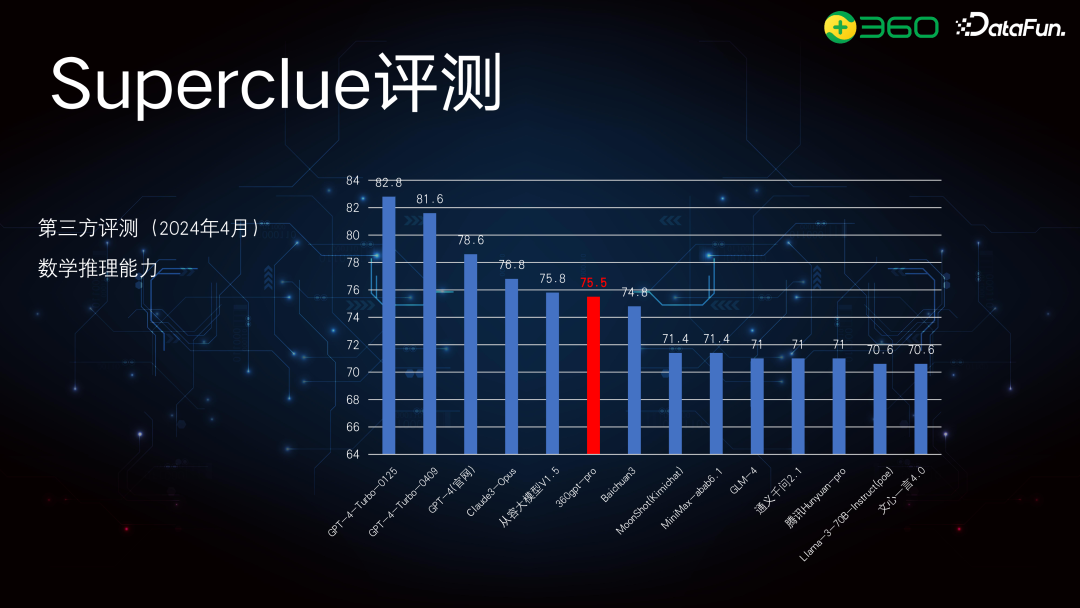
训练优化****

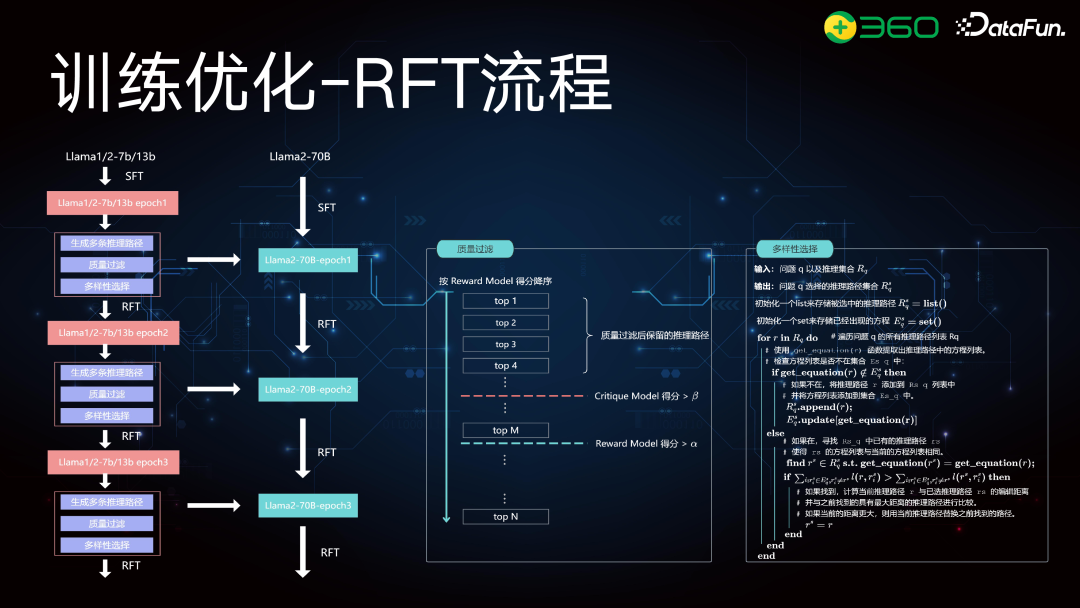
上图中可以反映出小模型的优势,比如右上角的 LLaMA 模型,我们可以看到 33B、7B 和 13B 的模型,其中推理路径贡献最大的一部分并不是 33B,而是 7B。下面的图也显示,7B 和 14B 的模型分别贡献了 41% 和 39% 的推理路径,而中间两个模型相交的推理路径只有 19%。这说明更小的模型在数据生成和采样方面,能得到更加多样化的推理路径。

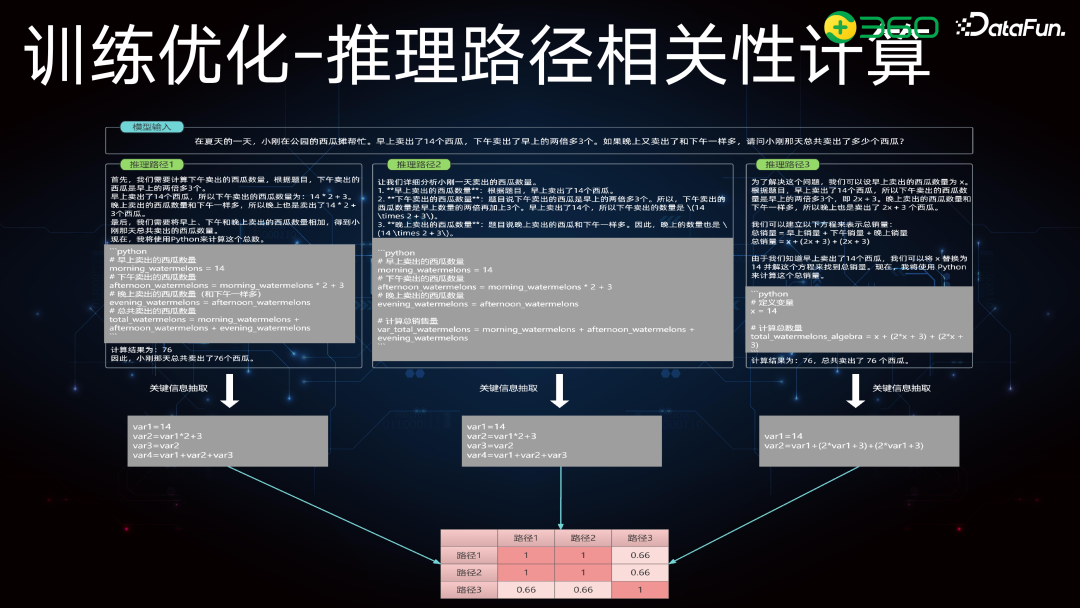
上图中展示了详细流程,比如左边图中的推理路径由 r1 到 r3,再加入一个新路径 r4。我们会计算 r1 到 r4 的相关性或距离,如果 r4 超过前两个路径的距离,就会替换其中一个,以保证选出路径间距离最大化。在我们的流程中,重点在 PoT 部分的多样性选择。PoT 部分相对结构化,不同推理路径会反映在 PoT 部分的不同实现方式上。

05****
问答环节**
Q1:之前提到的 DPO 和 PPO 是基于两个测试集的结果,还是在两个不同的问题领域中的表现?另外,这两个方法之间存在什么主要差异?****A1:那个评测是在一个评测集上的,都是数学推理类的问题。我们做了两部分工作,一部分是 PPO,另一部分是 DPO。当时在构建 pair 对时,是根据 RFT 的最高得分和最低得分来构建的。这部分数据是重新构建的。Q2:关于您们的合成数据工作,包括最近其他的合成数据研究,比如腾讯的 10 亿人设研究。您觉得为什么这种合成数据能在复杂推理任务中发挥作用?另外,您认为合成数据在复杂推理任务中的上限是什么?因为看腾讯的研究,Scaling 曲线表现很好。
****A2:这个问题很好,也是我们目前在做的,我们数据组尤其关注合成数据。为什么要做合成数据?因为现有指令少,尤其是数学类的。我们需要更多的指令,同时要提高指令的难度。比如,现有的 GSM8K 和 MAS 类指令只能扩展到小学数学应用和竞赛题目,这在多样性和难度上都有问题。我们的做法是将问题细分为数学应用类、矩阵运算类、积分类等子类。每个子类下由标注人员构建种子指令,然后再进行数据合成。第一步必须做到位,第二步才能有效。合成数据在复杂推理任务的天花板在于筛选逻辑。如果筛选机制好,生成模型足够优秀,就能生成更好的指令。要对指令进行关键词抽取,再根据 token 级别扩展,生成的指令才会更好。筛选机制也很重要,不仅要筛选好的指令,还要筛选指令的回答,这两者决定了天花板的高度。英伟达的研究也展示了合成数据的重要性。只有 2 万条数据是人工标注的,98% 是合成数据。他们的筛选方法尤其对 MAS 类问题进行了分类,但主要针对简单问题,像 GSM8K 的简单替换。而在数学推理外,如 close QA 或 open QA 类问题,英伟达的方法可能会生成与原数据分布相似的数据,这不是我们想要的。我们需要分布之外的数据,有扩展性的合成数据。英伟达还注重 reward model 的训练,特别是 340B 的 reward model,这部分工作在于区分难分的指令。因此,合成数据需要细分领域或技能,最终的质量和多样性决定了效果。Q3:老师您好,我们看到 Critique Model 和 GPT-4o 的打分分布已经接近,Critique Model 的大小是否考虑了不同参数量的影响?您提到生成样本数据时会用一个特别小的模型,所以判别模型也会很小,但英伟达的 reward model 很大。******A3:Critique Model 比 reference model 小很多。Critique Model 和 reward model 不同,reward model 很大,但Critique Model 不能太大。reward model 推理速度快很多,但它是二分类模型;而 Critique Model 是语言模型,两者属于不同类型的模型。以上就是本次分享的内容,谢谢大家。

分享嘉宾
INTRODUCTION
文亮

奇虎360
资深算法专家
2016 年硕士毕业于电子科技大学信息与软件工程,《推荐系统技术原理与实践》作者,拥有超过 8 年的模型优化经验,硕士期间发表 5 篇论文,其中 3 篇被EI收录。在大模型方向拥有丰富的技术背景,参与过千亿大模型训练和优化。目前主要负责大模型后训练,COT 优化以及通用技能优化。****
