

人类是天生的社会性动物,彼此不断互动。一个没有这些互动的世界将缺乏意义。在我们日常生活中的各种互动中,有一些情况需要多人合作才能实现共同目标。例如,观察建筑工人合作建造一栋大楼,或者在街上漫步时司机为了安全导航而相互让路,就是这种合作的例证。这些场景都可以被视为合作的实例。在机器和人工智能领域,可以将这些场景建模为多智能体系统。多智能体强化学习(MARL)是解决多智能体系统内复杂问题的一种流行的机器学习范式。
虽然现实世界中的多智能体问题往往可以被框定为 MARL 问题,但由于 MARL 带来的影响,最近提出的方法的全部潜力主要是通过计算机模拟来实现的。例如,在真实场景中,智能体通常只能获得其对环境的局部观察结果,而无法看到任何其他全局信息。另一方面,在模拟中,在智能体的训练阶段,可以利用一个掌握系统所有信息的中央数据库。这种运行模式被称为 “分散执行的集中训练”(CTDE)。在这种模式下,价值函数因式分解方法构成了 MARL 算法系列,可将联合行动价值函数分解为智能体策略进行学习。尽管最近提出了几种这样的方法,但其中一些方法仍然无法解决某些难以权衡的复杂任务,而且还需要使用额外的状态信息,而这些信息并不总是可用的。在本论文中,我们介绍了一种称为残差 Q 网络的值函数因式分解方法,它在因式分解过程中不需要额外的状态信息。从理论上讲,这种方法能够对任何环境系列进行因式分解,特别是在对非合作行为有严重惩罚的场景中,具有优势。
懒惰智能体的出现是 MARL 中另一个常见问题。这是指在一个由多个智能体组成的团队中,一些智能体没有为实现团队的总体目标而合作,而是选择等待队友完成所有工作。这个问题是由于在团队成员之间分配共享奖励的功劳时存在误差造成的。为了解决这个问题,我们在本论文中提出了一种基于因果关系的方法,旨在找到智能体的个体观察结果与团队奖励之间的因果关系。直觉是,当团队获得奖励时,每个智能体只有在对实现团队奖励有任何影响的情况下才应该接受奖励。此外,我们还从单纯的 CTDE 学习过渡到探索智能体如何在不共享网络参数的情况下,通过使用我们基于因果关系的方法来增强其合作行为,从而实现独立学习。独立学习被认为是一种更现实的方法,因为智能体被视为自成一体的实体,每个智能体都有自己的策略,并且不依赖于集中式甲骨文进行学习。
在多种情况下,具备通信能力有利于改善合作行为。在许多 MARL 应用场景中,都可能存在可以进行通信的情况,这在多个实际应用中都很常见。为此,本论文提出了一种名为 “注意正则化通信(ARCOMM)”的通信方法。让智能体进行交谈可能是学习某些复杂任务的关键,而要想取得成功,就必须学习高效的信息。此外,还探索了完全独立的学习者(不共享网络参数、仅依靠本地化观测的智能体)之间的通信。这种探索包括不同层次的网络容量、参数共享和通信,并研究它们之间的相互作用。
总之,本论文提出的方法为 MARL 目前存在的一些问题带来了重要的解决方案,为该领域提供了改进合作的新方法,并允许创建能力更强的智能体。同时,还提出了一些观点,并启发了一些讨论,以尽量缩小模拟与现实之间的差距。最后,概述了未来研究的潜在途径,阐明了可从本文介绍的研究成果中获益的其他应用,以此结束本论文。
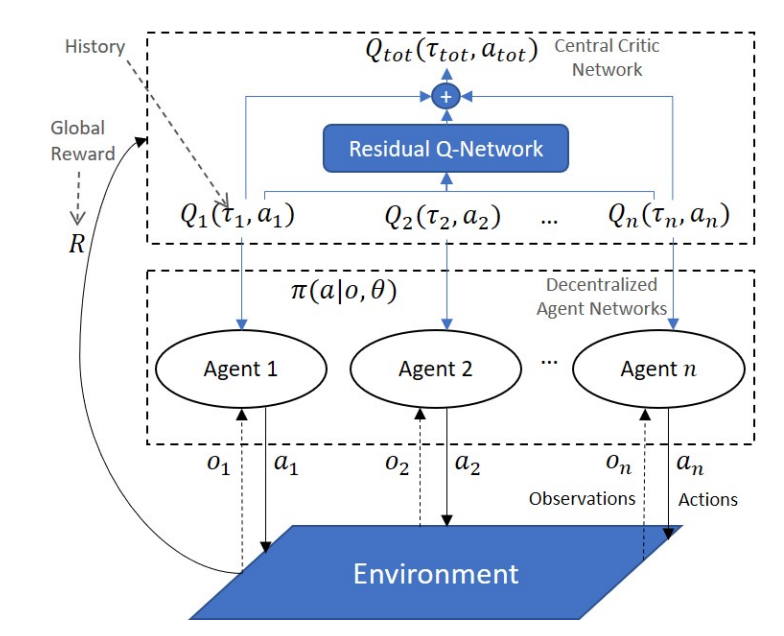
图 3.1:拟议 RQN 方法中的集中训练分散执行范例说明。


