
报告深入剖析了DeepSeek-R1系列及其相关强推理模型从研发历程、核心技术创新至未来展望的全方位信息。聚焦于强化学习(RL)在大语言模型推理领域的运用,报告详细探讨了DeepSeek-R1 Zero与DeepSeek-R1如何在不依赖监督微调(SFT)的前提下,采用纯粹的强化学习策略,实现推理能力的突破性提升。 **
**

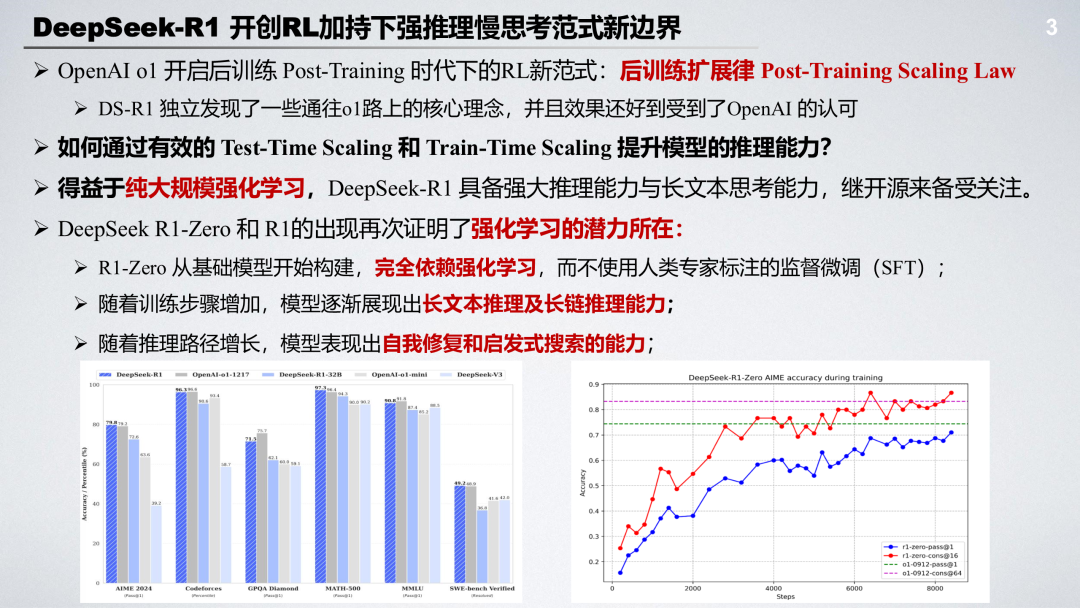

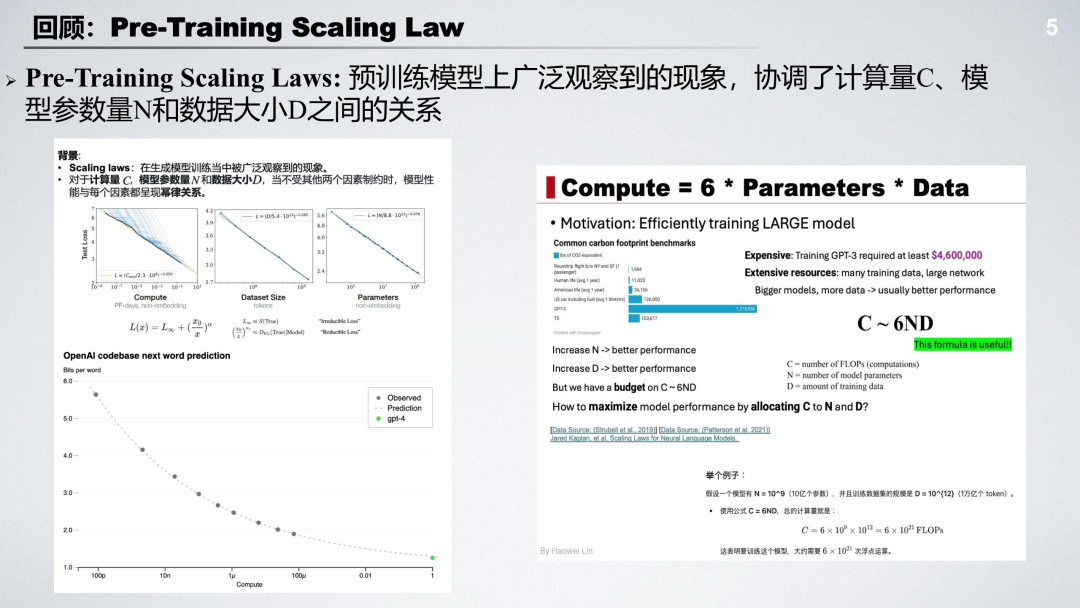


成为VIP会员查看完整内容
相关内容
Arxiv
199+阅读 · 2023年4月7日
Arxiv
78+阅读 · 2023年4月4日
Arxiv
137+阅读 · 2023年3月29日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
199+阅读 · 2023年4月7日
Arxiv
78+阅读 · 2023年4月4日
Arxiv
137+阅读 · 2023年3月29日