本文提出了一个用于模拟军事行动的高级实时战略(RTS)游戏“指挥:现代作战”(CMO)的强化学习(RL)框架。这是一款模拟军事行动的高级实时战略(RTS)游戏。CMO 挑战玩家在战术、战役和战略决策方面的驾驭能力,涉及多个单元的管理、有效的资源分配和并发行动分配。本研究的主要目标是利用 RL 的功能,实现军事决策的自动化和增强。为实现这一目标,我们开发了一种具有独特架构的参数化近端策略优化(PPO)智能体,专门用于应对 CMO 带来的独特挑战。通过改编和扩展 AlphaStar 和 OpenAI Five 等该领域成果中的方法,该智能体展示了 RL 在军事模拟中的潜力。我们的模型可以处理 CMO 中呈现的各种场景,标志着在将人工智能(AI)与军事研究和实践相结合方面迈出了重要一步。这项研究为今后探索将人工智能应用于国防和战略分析奠定了基础。
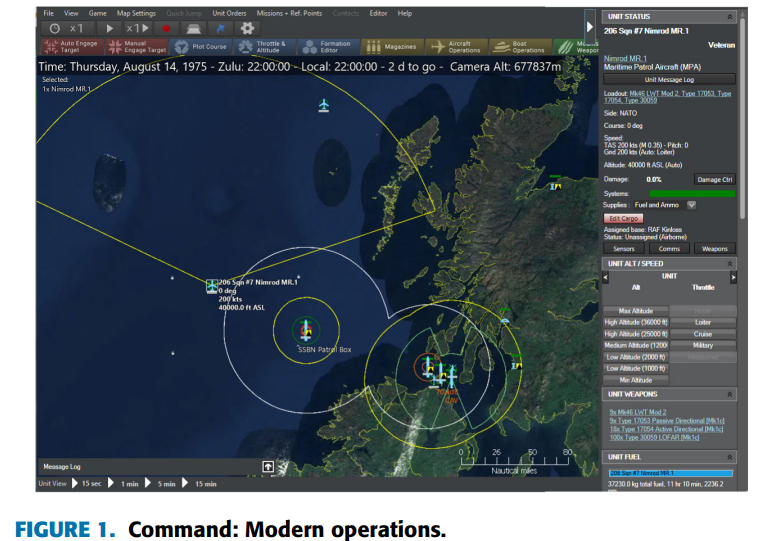
“指挥:现代作战”(CMO)
CMO 全面细致地模拟了二战后至当代的空中、海上和地面军事行动。游戏为应用真实世界的军事战略和战术提供了一个复杂的平台,并以大量历史和现代军事硬件和系统数据库为基础。模拟引擎能够处理各种军事交战,从局部遭遇战到大规模全球冲突。
如图 1 所示,游戏的图形用户界面采用高分辨率卫星图像和详细地形图渲染的全球综合视图,为游戏中的所有操作提供了基础环境。玩家可以操作控制各种军事单元,包括飞机、舰船、潜艇、地面部队甚至战略武器,在复杂的任务和场景中进行导航。
游戏中的每个单元都按照真实世界的规格进行了高保真建模,涵盖了武器能力、燃料消耗、物理限制、传感器功能和真实通信系统等方面,确保了高度精确的模拟。
CMO 配备了场景编辑器,允许玩家创建从历史战役到虚拟冲突的不同场景,为研究复杂的军事行动提供了手段。这使得 CMO 不仅是一个娱乐平台,也是军事训练和战略分析的工具。
CMO 与 RL 智能体的整合建立在已有初步工作基础之上。尽管有了这个起点,但在推进项目的过程中还是遇到了相当大的挑战。有效设置应用程序接口(确保快速执行和有效训练的关键步骤)的任务需要大量的工作。游戏的多面性为高级智能体提供了理想的试验平台,使我们的工作受益匪浅。
框架
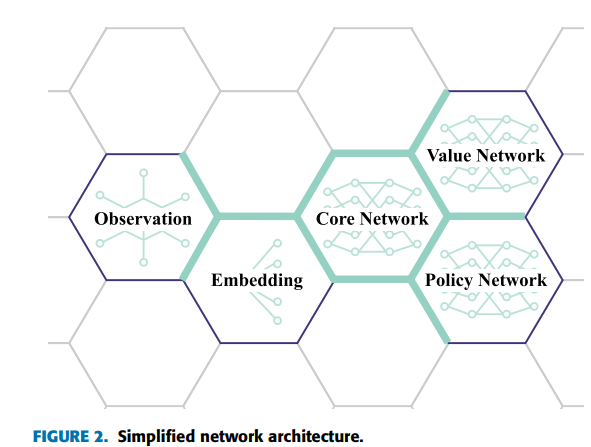
本节将介绍 PPO 智能体的神经网络架构,该架构旨在扮演 CMO 中的任何场景。RL 智能体的简化表示如图 2 所示,展示了一个通过嵌入处理观察结果的共享网络。这一设计深受 OpenAI Five 和 AlphaStar 架构的影响。值得注意的是,鉴于其原始架构的复杂性和深度,复制或改编它们的模型远非易事。
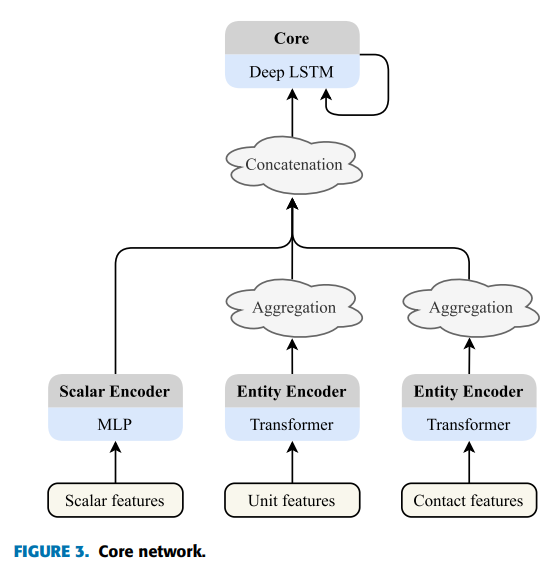
输入结构分为三类。第一类由标量输入组成,其中包括特定场景的信息,如当前时间、损失的单元数和失败的联系人数。与 AlphaStar 和 OpenAI Five 不同,我们的模型不包含基于像素的观察结果。相反,我们将场景中的实体分为两类:“单元”(己方单位)和 “接触点”(敌方单位),如图 3 所示,它们在游戏中通常被称为 “单元 ”和 “接触点”。
此外,还借鉴了 AlphaStar 的做法,采用变换器模型对实体类型的观测结果进行编码。然后,通过最大池化操作对这些实体编码进行聚合,再与标量编码器的输出进行连接。如图 3 所示,这些合并数据被输入一个 LSTM 网络。网络的值函数由处理 LSTM 输出的简单 MLP 决定。
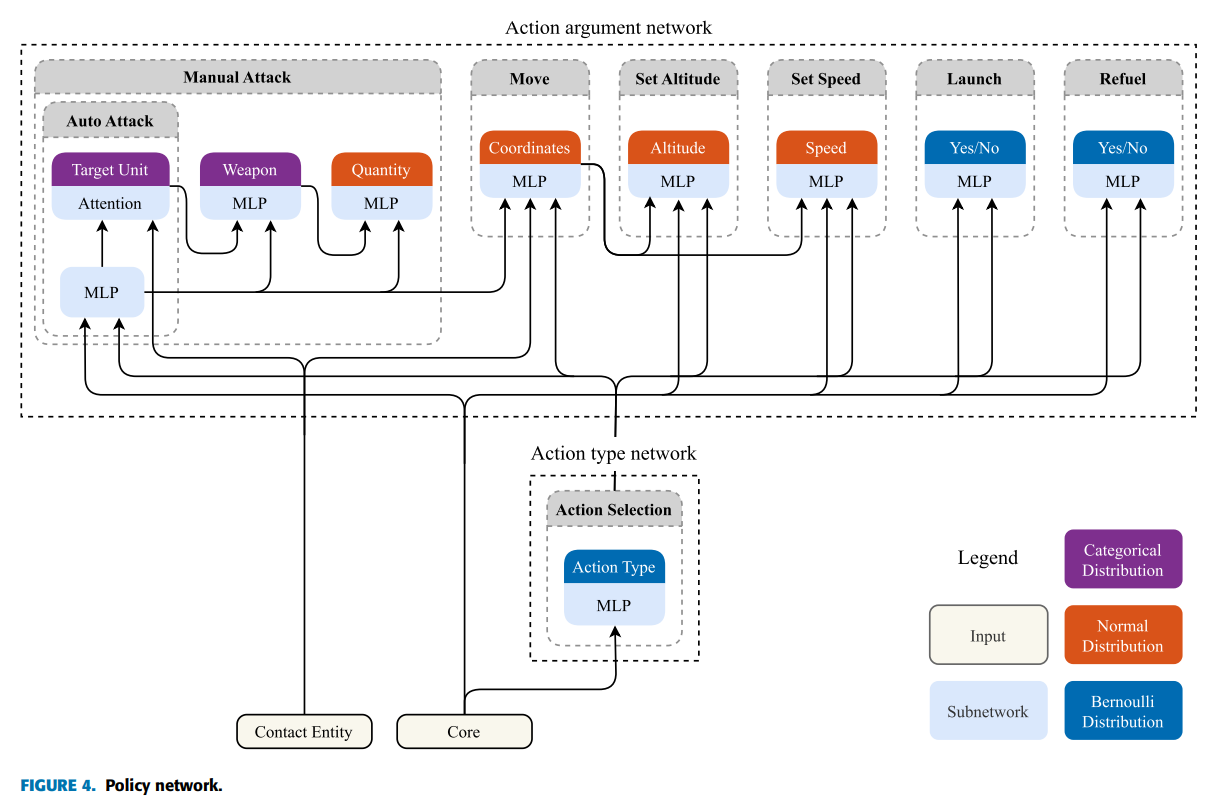
动作头的结构更为复杂,由两个主要部分组成:动作类型头和动作参数头。如图 4 所示,行动选择模块的这一设计试图在复杂性和功能性之间取得平衡,详见第五节 B 部分。架构的关键修改之一是其管理CMO多单元控制动态的能力。传统 RTS 游戏的重点可能是单个单元或较小的群组控制,而CMO则不同,它需要同时协调一方的多个单元,从而将问题提升为 MARL 挑战。网络的设计方式是通过变压器来处理单元数量的变化。变压器允许网络根据环境中每个单元的情况需求动态调整其重点和资源分配。
PPO 智能体涉及的另一个方面是CMO固有的多行动选择功能。在CMO中,当游戏暂停时,玩家可以为每个单元分配一组动作;例如,导航到指定位置、调整单元速度、向特定目标发射武器、激活雷达、关闭声纳。一旦恢复模拟,这些操作将同时执行。这种多行动选择机制与传统的 RTS 环境不同,传统的 RTS 环境中的行动通常是顺序执行或有并行执行限制。我们设计的智能体可以让单元同时执行多个动作。为此,我们设计了智能体,使每个单元都能同时输出多个动作。
这种架构不仅能满足当前 CMO 游戏的要求,还提供了一个可扩展的框架,能够适应更复杂的场景和未来的扩展。