现在,深度神经网络(DNN)几乎无处不在。在AlexNet [1] 的标志性研究之后,DNN不仅超越了之前的人造算法,甚至还超越了人类水平。它在计算机视觉、自然语言处理和音频信号处理方面都取得了最先进的表现。然而,DNN的卓越性能是以高计算成本为代价的。DNN的主要操作包括全连接层(FCL)和卷积层(CL)。在FCL的情况下,权重参数与输入特征图之间进行矩阵乘法以生成输出特征图。在CL的情况下,权重参数与输入特征图之间进行卷积以生成输出特征图。因此,我们需要加载输入特征图和权重的操作、乘法和累加(MAC)操作进行计算,以及存储输出特征图的DNN计算操作。由于DNN利用了大量的层,这些层具有大的维度,所以很容易找到需要100s∼1000s MB数据和∼1 Giga MAC操作进行1次推断的DNN。这些巨大的计算成本是DNN加速器设计的主要要求。
https://link.springer.com/book/10.1007/978-3-031-36793-9
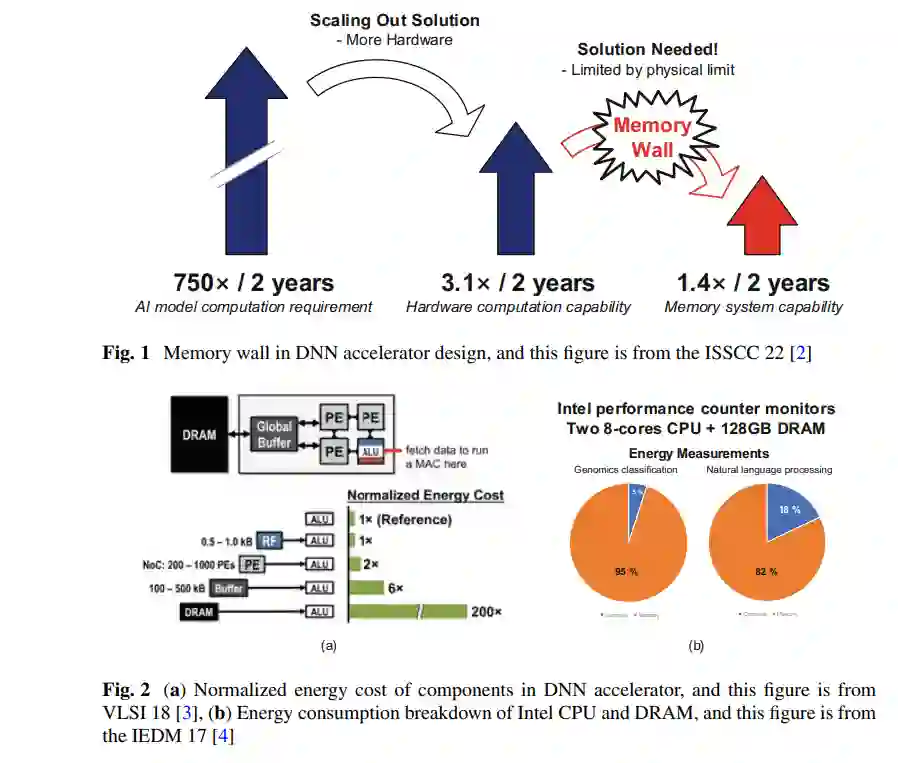
最近,在DNN加速器设计中,内存成本的部分变得占主导地位。这是因为存在一个“内存墙”问题,即处理器和内存之间的性能差距。尽管处理器的逻辑受益于技术的快速进步,但内存的改进却无法跟上这种进步。图1显示了DNN加速器设计中的内存墙[2]。DNN模型的快速发展每两年需要计算需求增加750倍。硬件的计算能力每两年增加3.1倍。然而,内存系统的能力只是每两年增长1.4倍。此外,我们可以通过集成更多的硬件来扩展计算能力,但由于物理限制,很难扩展内存能力。图2a显示了DNN加速器中各组件的标准化能源成本[3]。DNN加速器集成了用于计算的处理引擎(PEs)、作为L1缓存的基于触发器的寄存器文件、作为L2缓存的基于刮擦板存储器的全局缓冲器,以及作为主内存的DRAM。与PE中的计算能源成本相比,缓冲器访问和DRAM访问的能源成本要高得多。因此,需要频繁访问内存的DNN会受到大量内存能源消耗的影响。图2b显示了使用2颗英特尔8核CPU和128GB DRAM测得的计算和内存的能源分解[4]。对于基因组分类,内存消耗了整体能源的95%。对于自然语言处理,内存消耗了整体能源的82%。
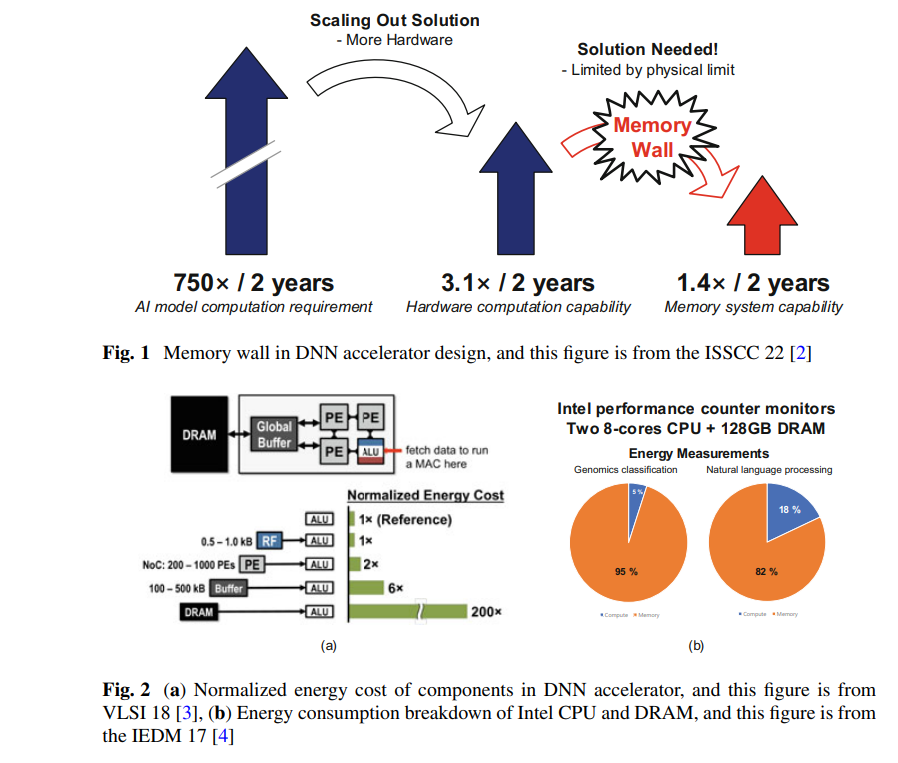
这段内容描述了DNN加速器设计中内存成本的增加以及内存和计算性能之间的差距问题。很明显,内存访问和能源消耗是DNN加速器设计的主要挑战之一。
在这一章节中,我们提出了从软件层面到硬件层面的各种优化技术,旨在减少移动设备中能效高的深度强化学习(DRL)加速器的内存占用和内存功耗。从本质上讲,由于DRL的特性是同时使用多个由全连接层组成的DNN,因此它一直受到内存瓶颈的困扰。我们提出了2种芯片设计,分别处理内存带宽优化和内存功耗优化。本章的其余部分组织如下:
-
在第2节中,我们介绍了强化学习(RL)和深度强化学习(DRL)的背景信息,这些信息是设计DRL加速器所必需的。在这一节中,我们解释了RL问题的定义、RL的组成部分、RL的经典方法(如动态规划、时间差学习和蒙特卡洛方法),以及深度RL的方法(如深度Q学习、演员-评论家和策略梯度)。这一节中解释的信息对于理解DRL的操作特性是至关重要的。
-
在第3节中,我们提出了一种新的权重压缩方法,用于DRL训练加速,名为组稀疏训练(GST)。深度强化学习(DRL)在顺序决策问题中表现出了卓越的成功,但需要很长的训练时间才能获得如此好的性能。已经提出了许多并行和分布式DRL训练方法来解决这个问题,但在资源有限的设备上难以使用它们。为了在实际的边缘设备上加速DRL,必须解决由于大量权重交易导致的内存带宽瓶颈问题。然而,之前的迭代修剪不仅在训练开始时显示出低压缩率,而且使DRL训练变得不稳定。GST选择性地使用块循环压缩来在DRL训练的所有迭代中保持高权重压缩比,并通过奖励感知修剪动态适应目标稀疏度,以实现稳定训练。由于这些特点,与迭代修剪方法相比,GST在Mujoco Halfcheetah-v2和Mujoco Humanoid-v2环境的TD3训练中获得了比迭代修剪方法高25%p∼41.5%p的平均压缩比,且不降低奖励。
-
在第4节中,我们提出了一种用于边缘设备上的DRL训练的能效高的深度强化学习(DRL)处理器,名为OmniDRL。由于可以适应每个用户的独特特性,边缘设备上的DRL训练的需求日益增长,但大量的外部和内部存储器访问限制了在资源受限平台上实施DRL训练。OmniDRL提出了4个关键特性,旨在通过尽可能多地压缩数据来减少外部存储器访问,并通过直接处理压缩数据来减少内部存储器访问。组稀疏训练通过选择性地利用权重分组和权重修剪,使每次DRL迭代都能获得高权重压缩比。提出了一个组稀疏训练核心,充分利用了来自GST的压缩权重,跳过冗余操作和重用重复数据。指数-均值-增量编码对数据应用了额外的位级压缩,比之前的指数压缩方法实现了更高的压缩比和低内存消耗功率。全球首创的片上稀疏权重转置器使压缩权重的DRL训练过程无需基于软件的片外转置器。因此,OmniDRL采用28nm CMOS技术制造,占地3.6×3.6 mm2。它展现了4.18 TFLOPS的最先进峰值性能和29.3 TFLOPS/W的峰值能效。它在训练机器人代理(Mujoco Halfcheetah, TD3)时实现了7.16 TFLOPS/W的能效,这比之前的最先进技术高出2.4倍。
在第5节中,我们提出了一个低功耗、高性能的DRL系统,配备了能效高的DRL芯片。所提出的DRL芯片可以无缝压缩权重和特征图,从而减少内存访问次数。在Mujoco Humanoid-v2中,我们提议的带DRL芯片的系统展示了对突然环境变化的人形机器人的适应。所提出的系统显示出的训练能效为10.3 iteration/J,这比NVIDIA TX2高出3.9倍。
在第6节中,我们提出了一个异构浮点(FP)计算架构,通过分别优化指数处理和尾数处理来最大化能效。我们提出的在内存中进行指数计算(ECIM)的架构和无尾数的指数计算(MFEC)算法,降低了内存和FP MAC的功耗,同时解决了之前在内存中进行浮点计算处理器的局限性。此外,我们实施并在28nm CMOS技术中制造了一个具有所提出特性和稀疏性利用支持的bfloat16 DNN训练处理器。在支持CIM架构的FP操作时,它实现了13.7 TFLOPS/W的能效。
除了第2章以外,所有章节都基于此作者之前的研究[5-8]。更具体地说,第3章基于“GST:集团稀疏训练用于加速深度强化学习”[5]。第4章基于“OmniDRL:带有双模式权重压缩和片上稀疏权重转置器的29.3 TFLOPS/W深度强化学习处理器”[6]。第5章基于“低功耗自主适应系统与深度强化学习”[7]。第6章基于“ECIM:为能效高的异构浮点DNN训练处理器在内存中进行指数计算”[8]。第2章基于此作者之前的出版物[9],以及一些DRL综述论文、书籍和课程,如[10, 11],David Silver的RL课程,以及Sergey Levine的深度RL课程。