对比学习是现在无监督学习中一种常用的学习机制,受到持续关注。MIT博士Yonglong Tian的博士论文《基于多视图对比学习的通用视觉研究》全面对对比学习的原理与方法,非常值得关注!

Yonglong Tian,是麻省理工学院CSAIL的五年级博士生,与Phillip Isola教授和Josh Tenenbaum教授一起工作。我的主要研究兴趣在于机器感知、学习和推理的交叉领域,主要从视觉的角度进行研究。在MIT之前,他在香港中文大学完成了硕士学位,导师是唐晓鸥教授和王晓刚教授。他从清华大学本科毕业。 http://people.csail.mit.edu/yonglong/
基于多视图对比学习的通用视觉研究

表示学习在构建强大且通用视觉学习器中发挥着关键作用,而这一问题历史悠久。随着我们时代数据爆炸式增长,表示学习变得越来越有趣。然而,大多数以往的方法都基于特定的策略设计,这些策略无法泛化。本论文提出并研究多视图对比学习,它基于一个简单的数学原理——区分联合分布中的样本与边际分布乘积中的样本。我们首先介绍多视图对比学习(MCL)的一般框架。我们证明了这个简单的框架能够处理各种表示学习问题,并经常将现有技术水平提升到更高层次。接着,我们试图从信息理论的角度理解多视图对比学习中视图选择的作用,并提出了一个“InfoMin”原则,该原则与最小充分统计量和信息瓶颈有关。这一原则进一步通过监督对比学习得到证实,该方法在标准图像分类基准上与监督交叉熵学习相媲美,甚至超过它。在最后部分,我们将多视图对比学习扩展到标准问题或设置之外。我们讨论了多视图对比学习的一种新颖应用,即知识蒸馏,并提出了第一个在开放式未经策划的场景中提高对比学习效率的工作。
1. 引言
近年来人工智能系统(如深度神经网络)的巨大进步和普及,得益于大规模数据集的精心人工标注。尽管这种监督学习范式在训练专用模型方面无疑表现出了卓越的性能,使它们在训练任务上表现得非常出色,但这种范式存在根本性的局限性。首先,我们正在并将继续目睹我们时代数据的爆炸式增长,最终标注所有数据是不可能的。此外,在某些情况下,我们无法标注原始数据,原因很简单,我们无法解释它,例如,无法解释射频信号的反射。但是,浪费那些未标记的数据是很可惜的。其次,对于许多任务,我们无法收集到足够的标记数据来训练专业模型,例如从MRI或X射线图像诊断强直性脊柱炎,这要么是因为由于隐私问题无法获取数据,要么是因为缺乏专家对数据进行标注。第三,这种监督训练的专业模型很容易受到攻击。大量关于对抗攻击的研究表明,监督模型(如图像分类模型)在面对输入图像中难以察觉的变化时,容易受到严重影响。
1.1 表示学习应该学习什么?
编码理论中的一个基本思想是学习压缩表示,但仍然可以用于重建原始数据。这个想法出现在现代表示学习中,以自动编码器Salakhutdinov和Hinton(2009)和生成模型Kingma和Welling(2013); Goodfellow等人(2014)的形式,试图尽可能无损地表示数据点或分布。然而,无损表示可能并不是我们真正想要的,实际上它很容易实现——原始数据本身就是一种无损表示。相反,我们可能更希望保留“好”的信息(信号)并丢弃其余部分(噪声)。那么我们如何识别哪些信息是信号,哪些是噪声呢?对于自动编码器或最大似然生成模型来说,一个比特就是一个比特。没有一个比特比其他比特更好。我们的猜想是,事实上某些比特比其他比特更好。有些比特编码了重要的属性,如语义、物理和几何,而另一些比特编码了我们可能认为不太重要的属性,如偶然的光照条件或相机传感器中的热噪声。我们重新审视了一个经典假设,即好的比特是那些在多个视图之间共享的比特,例如在多个感官模态之间,如视觉、声音和触觉Smith和Gasser(2005),如图1-1所示。从这个角度来看,“存在狗”的信息是好的,因为狗可以被看到、听到和摸到,但“相机姿态”是糟糕的信息,因为相机的姿态对成像场景的声学和触觉特性几乎没有影响。这个假设对应于这样一种归纳偏见,即观察场景的方式不应该影响其语义。在认知科学和神经科学文献中有大量证据表明,这种与视角无关的表示是由大脑编码的(例如,Smith和Gasser(2005);Den Ouden等人(2012);Hohwy(2013))。在本论文中,我们特别研究了不同视图是不同模态、图像裁剪或图像通道(如亮度和色度)的情境。我们利用的基本监督信号是自然数据中多个视图同时出现的现象。例如,我们认为Lab色彩空间中的图像是场景的两个视图——𝐿视图和𝑎𝑏视图——共同出现的一个配对示例;我们也可以将视频视为第一个视图,相应的音频视为第二个视图;同样,我们可以利用视觉和语言数据的共存,如图像-文本配对。
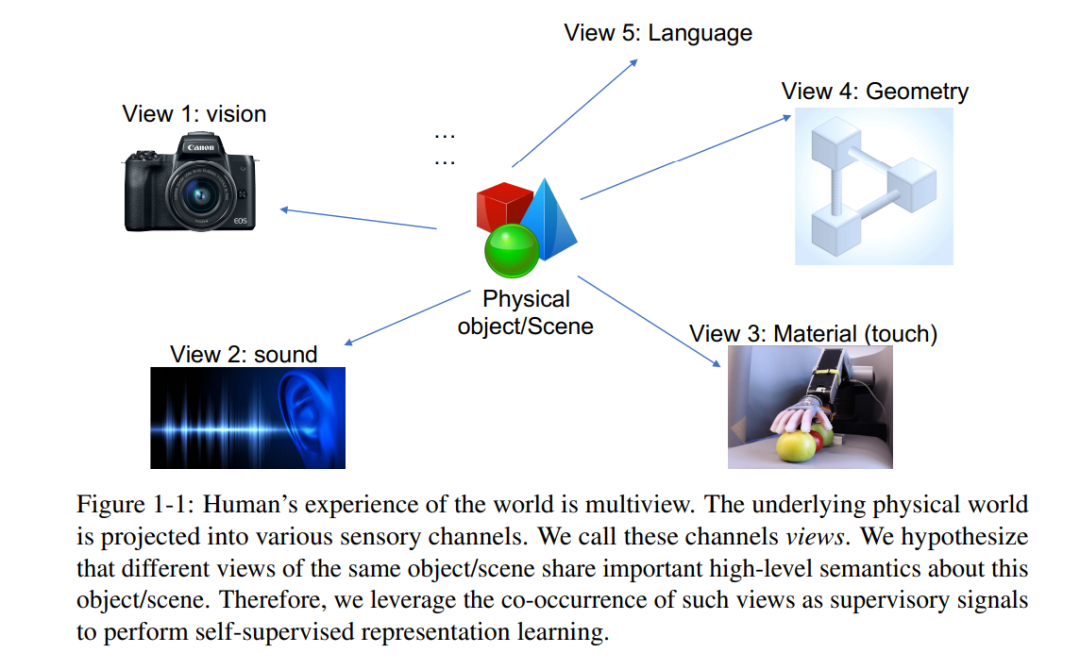
因此,我们的目标是学习能捕捉多个感觉通道之间共享信息的表示,但同时又要保持紧凑(即丢弃特定于通道的干扰因素)。为此,我们采用对比学习,通过学习特征嵌入使得同一场景的视图映射到相近的点(在表示空间中用欧几里得距离测量),而不同场景的视图映射到相距较远的点。对于任意两个视图𝑥和𝑦,对比学习的目标是区分联合分布𝑝(𝑥, 𝑦)的样本和边缘分布乘积𝑝(𝑥)𝑝(𝑦)的样本。在我们的公式中,对比目标可以理解为试图最大化数据多个视图的表示之间的互信息。论文结构****本博士论文首先描述了多视图对比学习的一般框架,借助该框架可以处理各种表示学习问题。接下来,我们试图从信息论的角度理解对比学习中视图选择的作用,并提出了一个“InfoMin”原则。然后通过监督对比学习证明了这一原则,其中应用了最优视图选择。最后一部分讨论了对比学习的其他应用(如知识蒸馏)和扩展(例如,如何将对比学习应用于未经策划的数据)。具体来说,本博士论文包括以下三个部分。第一部分假设人类的感知是深度多视角的,并提出了一个简单但通用的框架,从多个感官通道学习表示,每个通道都是我们潜在物理世界的投影"视图"。
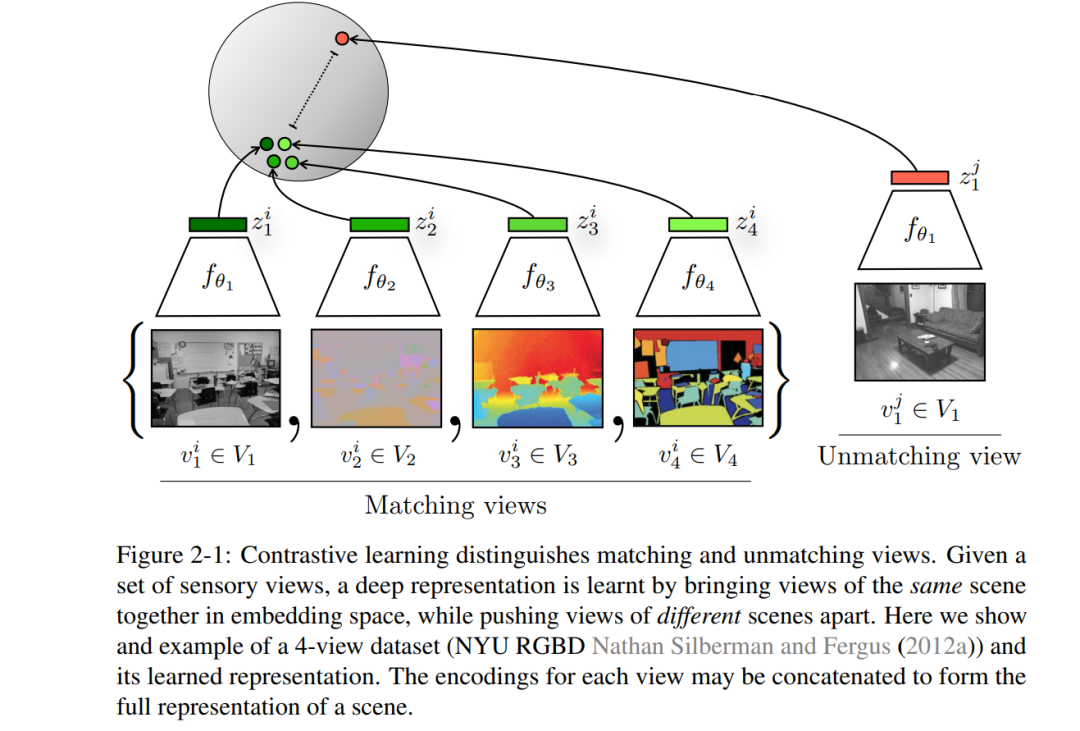
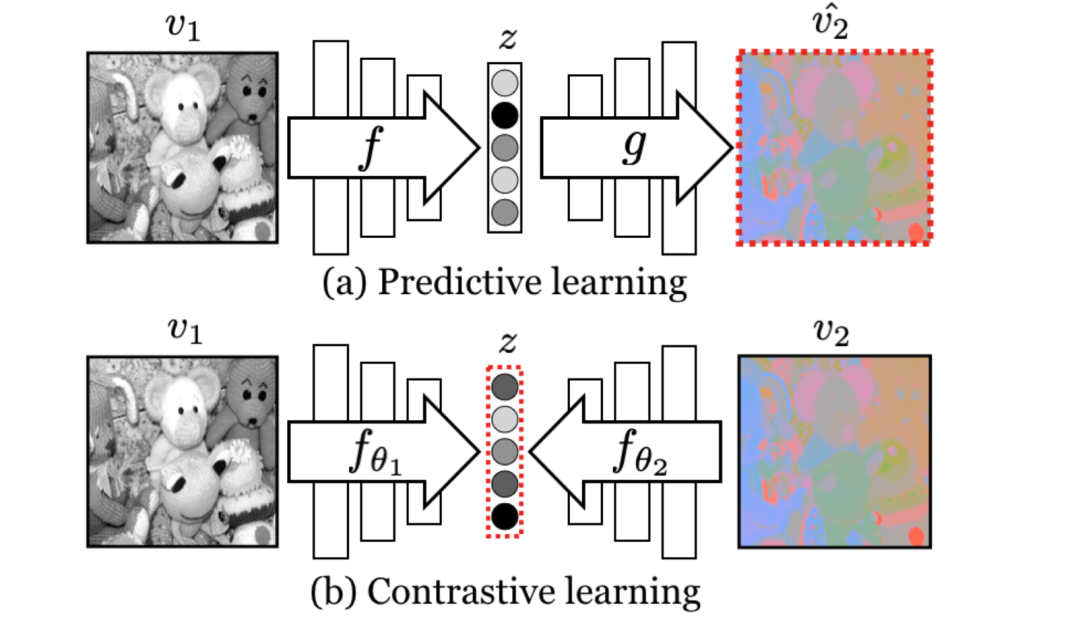
第2章介绍对比多视点编码。这个框架是基于这样一种观察:人类通过许多感官通道来观察世界,例如,由左眼看到的长波光通道,或由右耳听到的高频振动通道。每个视图都是嘈杂的和不完整的,但重要的因素,如物理、几何和语义,往往在所有视图之间共享(例如,可以看到、听到和感觉“狗”)。本文研究了一个经典假设,即一个强大的表示是对视图不变因素进行建模的表示。本文在多视图对比学习的框架下研究这一假设,学习了一种表示,旨在最大化同一场景的不同视图之间的互信息,但在其他方面很紧凑。该方法可扩展到任意数量的视图,并且与视图无关。分析了使其工作的方法的关键属性,发现对比损失优于基于跨视图预测的流行替代方案,从中学习的视图越多,得到的表示就越能捕捉到底层场景语义。
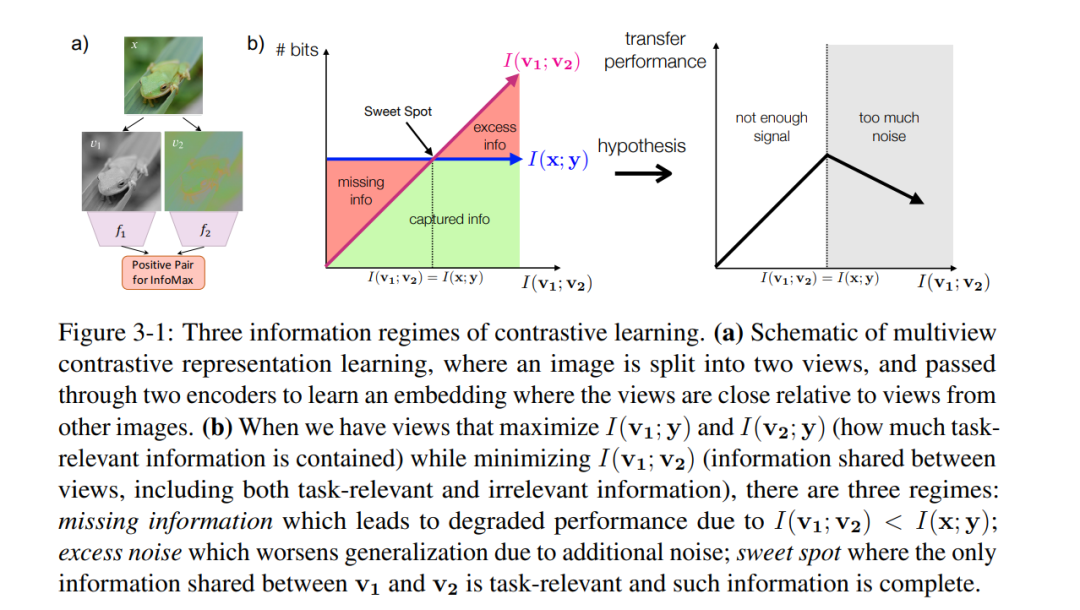
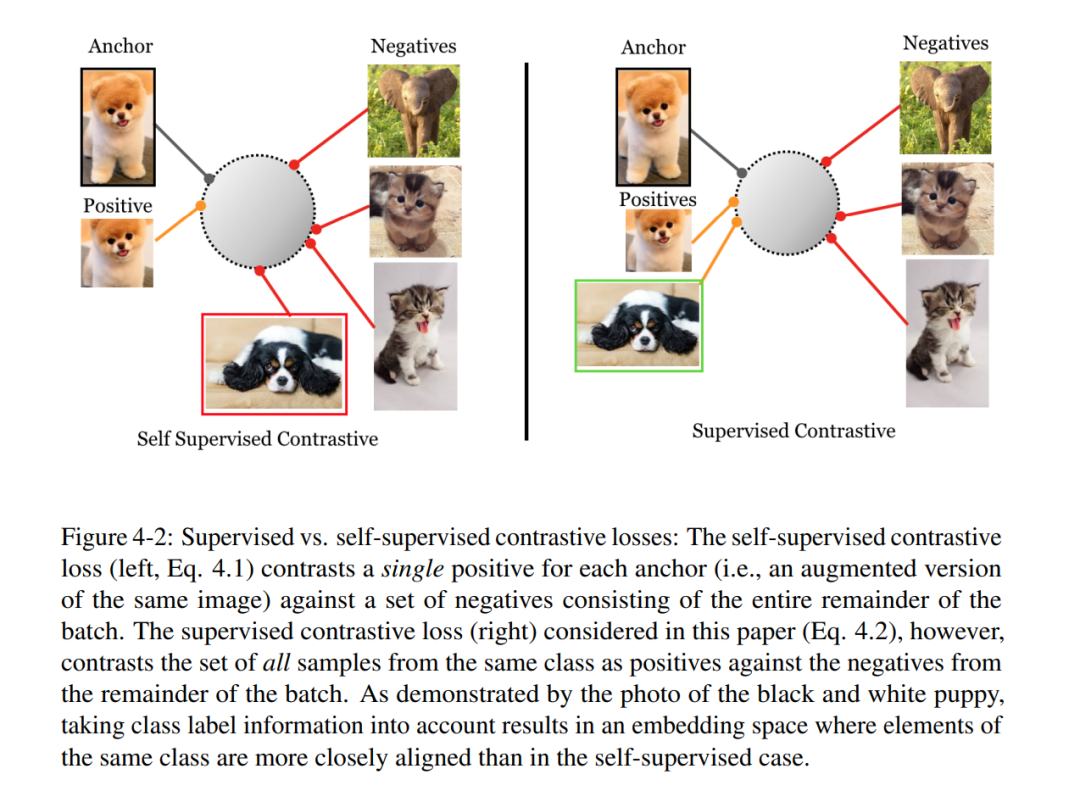
第二部分提出了多视角对比学习的好视角是什么。第3章从信息论的角度理解了视角选择的作用,并提出了“InfoMin”原则。第4章展示了一个示例——有监督对比学习——其中应用了“InfoMin”指导的最优视图选择。第三章研究了不同视角选择的影响。用理论和实证分析来更好地理解视图选择的重要性,认为应该在保持任务相关信息完整的情况下减少视图之间的互信息(MI)。为了刻画最优视图选择,从信息论的角度推导了一个" InfoMin "原则。为从经验上验证这一假设,设计了无监督和半监督框架,通过减少MI来学习有效的视图。第4章以分类问题为例,论证了InfoMin引导的最优视图的有效性。当下游标签可用时,可以将自监督对比方法扩展到监督设置,使我们能够有效地利用标签信息。同一类的点簇在嵌入空间中被拉到一起,同时来自不同类的样本簇被推开,实现了" InfoMin "的最小充分统计解释。分析了有监督对比(SupCon)损失的两个不同版本,确定了性能最好的损失表述。在分类精度和鲁棒性方面,表现出了比交叉熵一致的性能。
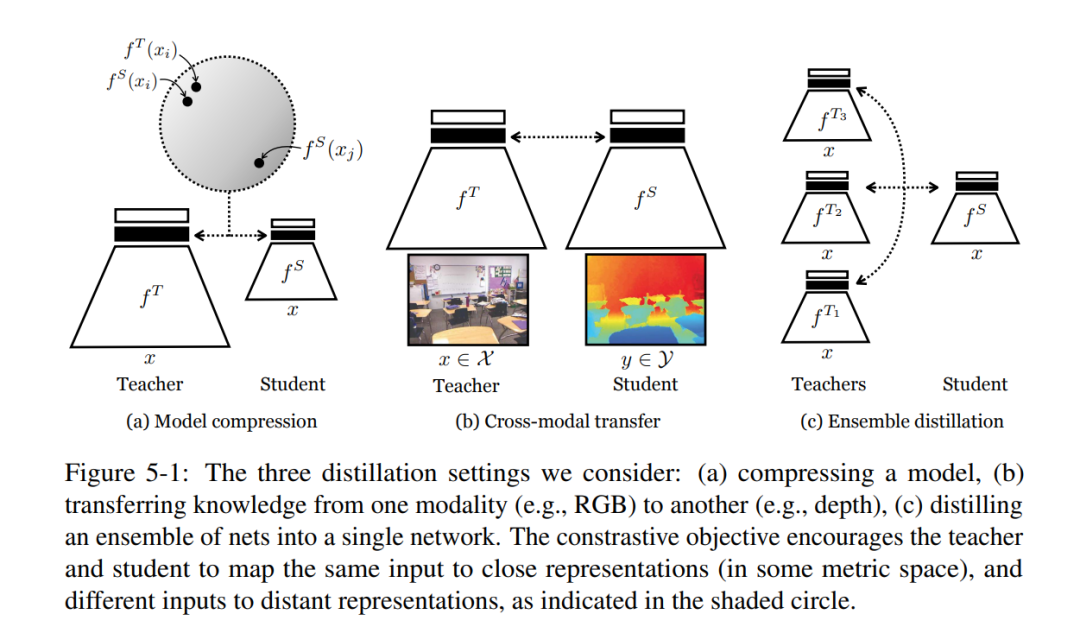
第三部分通过超越第一部分和第二部分中提出的标准问题和设置,使多视图对比学习变得通用。第5章将多视图对比学习应用于一个看似不相关的问题——知识蒸馏。第6章介绍了第一个在大规模非策划情况下提高对比学习效率的工作。第5章将对比学习应用于另一个问题——知识蒸馏。我们经常希望将表征性知识从一个神经网络迁移到另一个神经网络。例如,将一个大型网络蒸馏成一个较小的网络,将知识从一种感觉模式转移到另一种感觉模式,或将一组模型集成到单个估计器。这些问题的标准方法最小化了教师和学生网络的概率输出之间的KL散度。然而,这一目标忽略了教师网络的重要结构知识。这激发了另一个目标,通过该目标,我们训练学生在教师的数据表示中捕捉更多的信息。本文将这一目标表述为对比学习。实验表明,所提出的新目标在各种知识迁移任务上,包括单模型压缩、集成蒸馏和跨模态迁移,表现优于知识蒸馏和其他前沿蒸馏器。所提出方法在许多迁移任务中设置了新的最先进水平,在与知识蒸馏相结合时,有时甚至优于教师网络。

第6章将多视图对比学习扩展到真实世界的非策划数据。自监督学习在利用大量未标记数据方面有希望,但迄今为止,其大部分进展仅限于高度策划的预训练数据,如ImageNet。本文探索了从较大的、不太整理的图像数据集(如YFCC)中进行对比学习的效果,发现所得到的表示质量确实有很大差异。本文假设,这种管理差距是由于图像类别分布的变化——更多样化和重尾——导致可学习的负样本相关性更低。本文用一种新的方法来检验这一假设,即划分和对比(DnC),在对比学习和基于聚类的硬负挖掘之间交替进行。当在较少策划的数据集上进行预训练时,DnC大大提高了自监督学习在下游任务上的性能,同时在策划数据集上与当前最先进的技术保持竞争。