

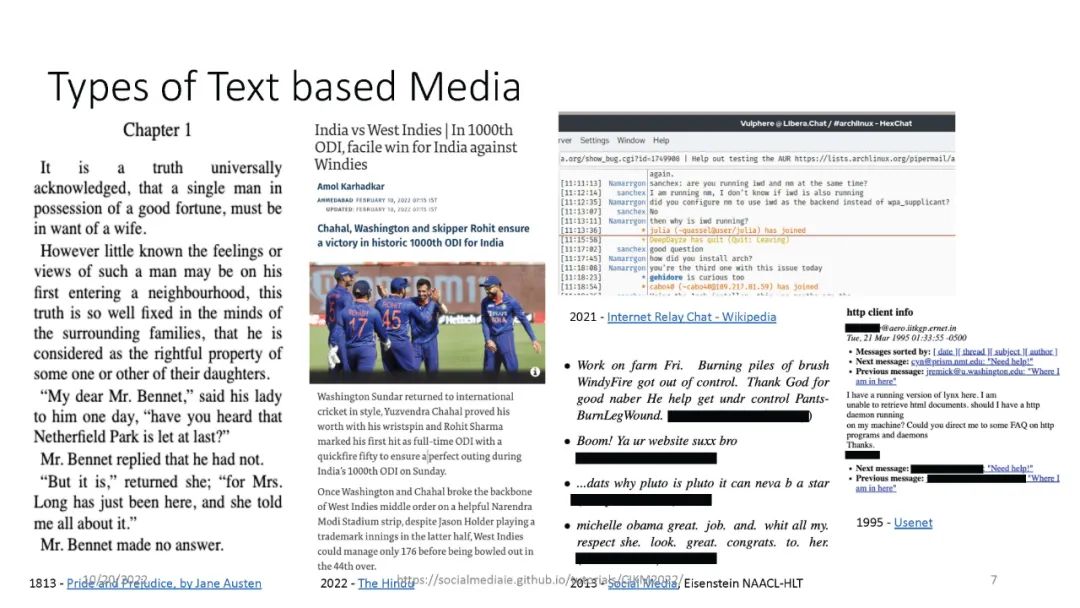
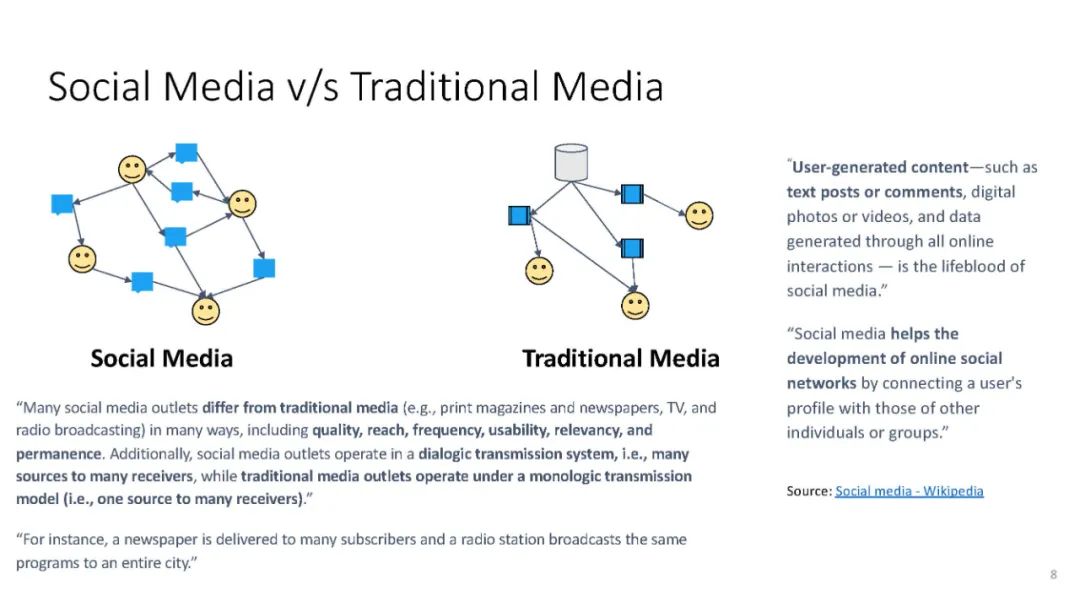
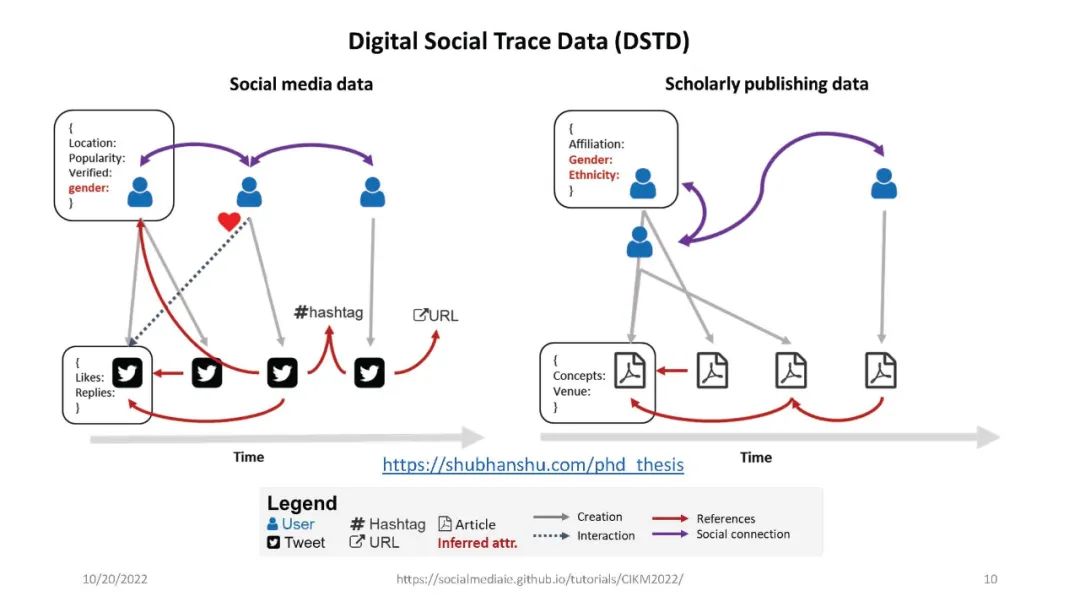
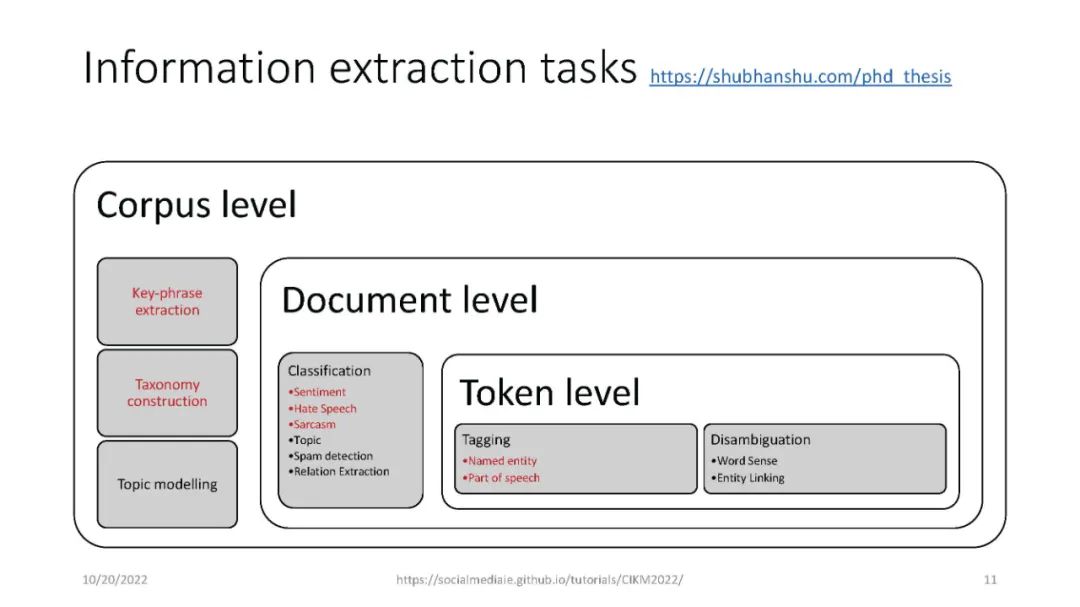
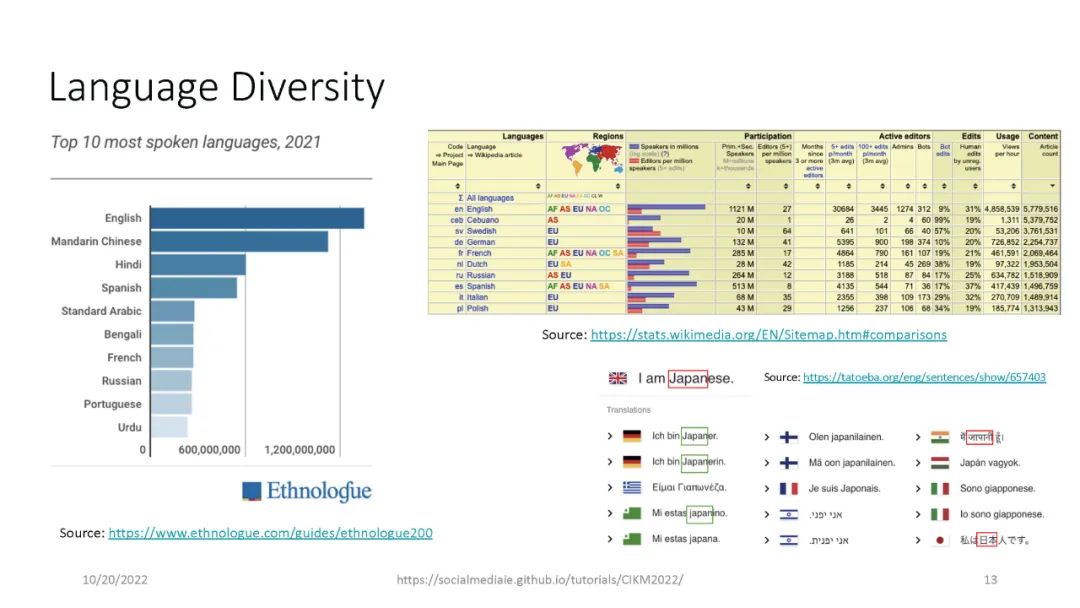
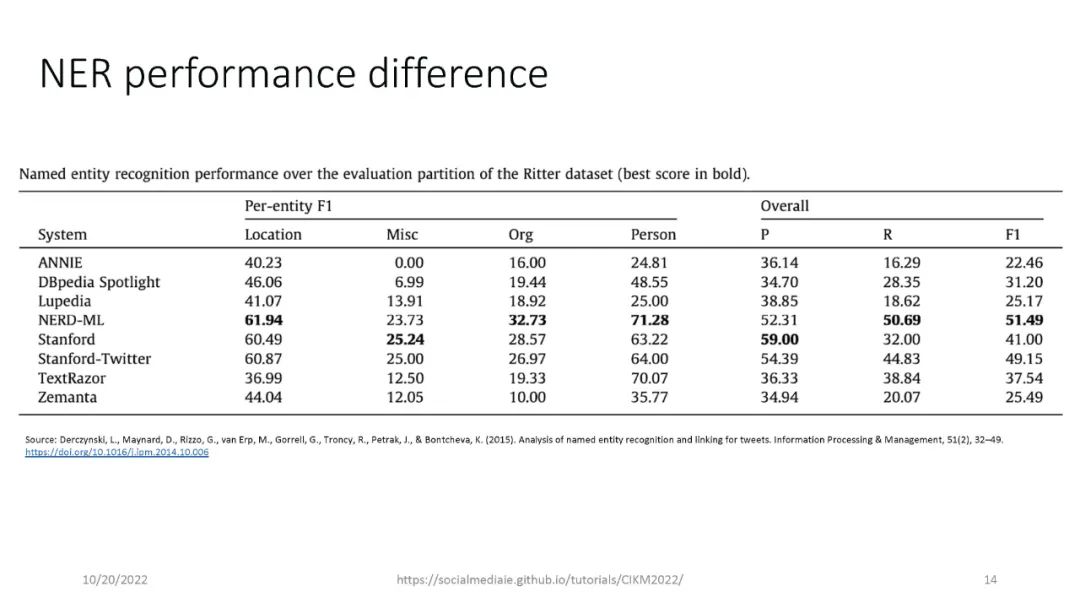
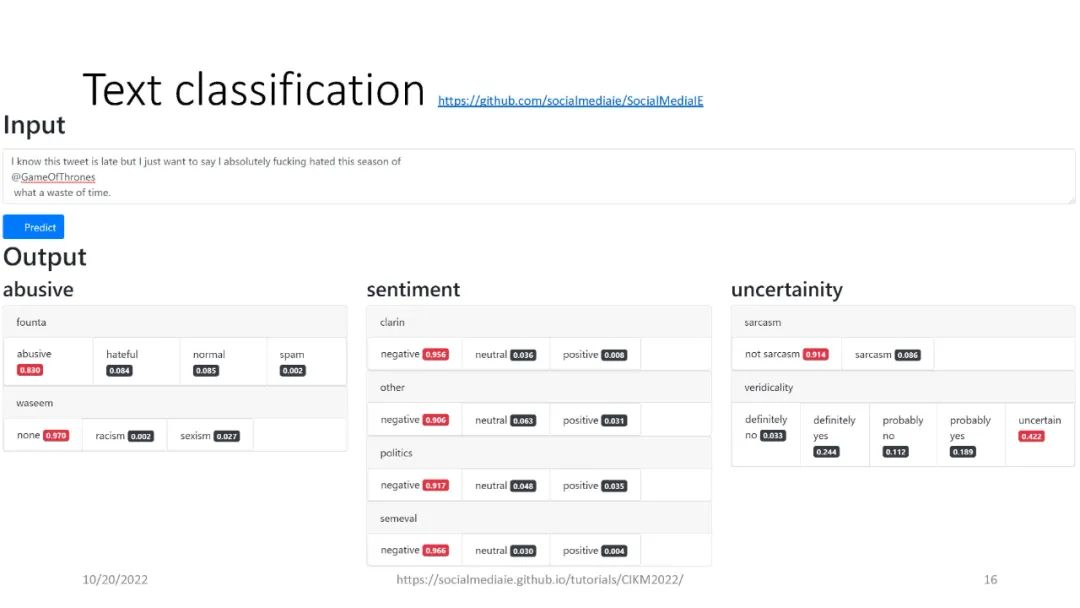
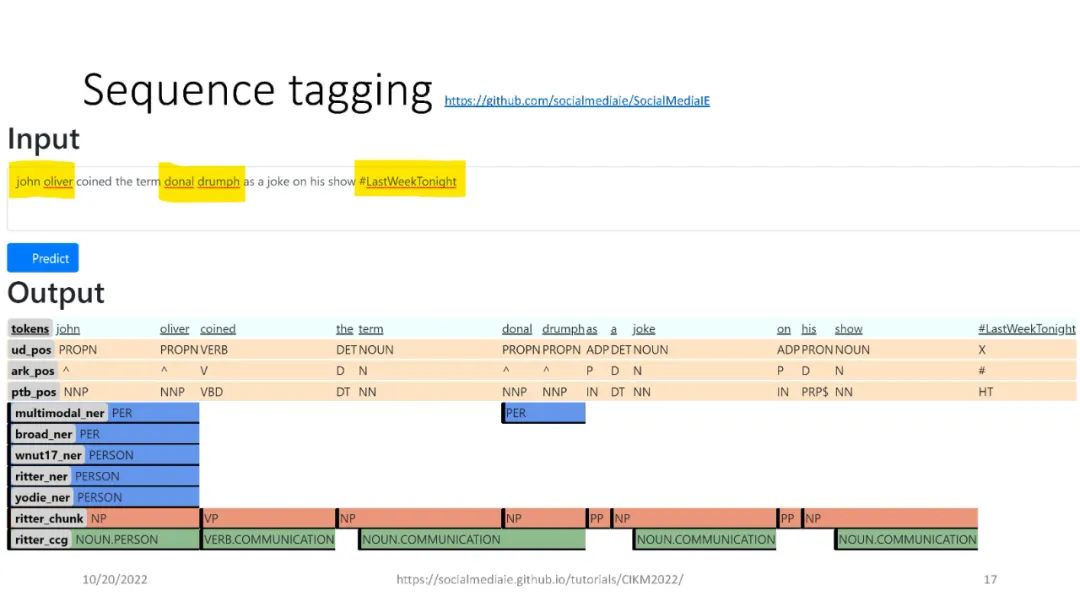
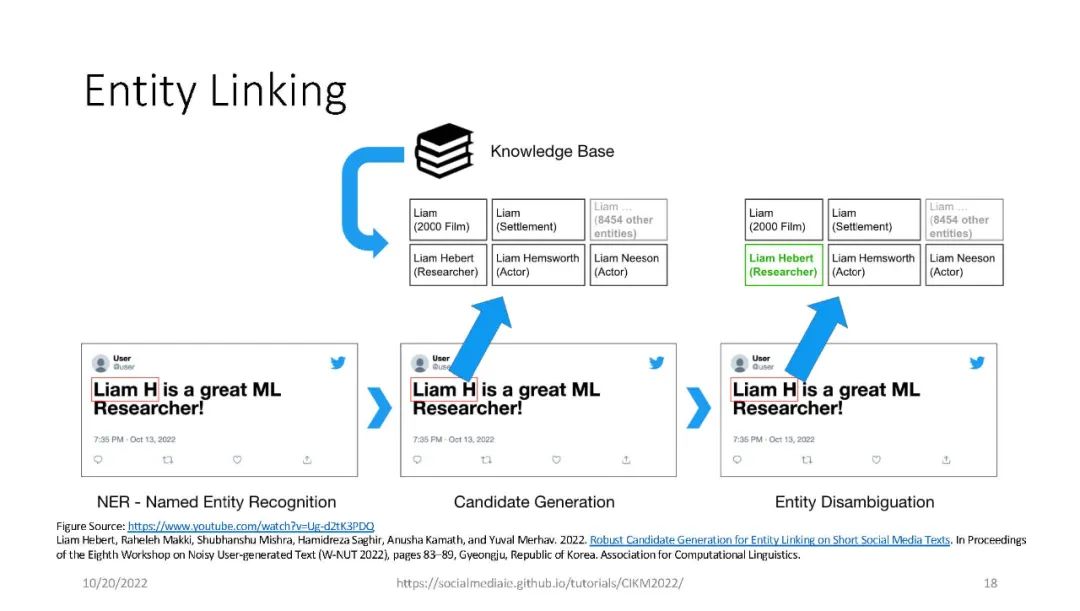
信息提取(IE)是自然语言处理中一个常见的子领域,主要关注从非结构化数据中识别结构化数据。信息检索(IR)社区依赖于精确和高性能的IE,能够从海量数据集中检索高质量的结果。IE的一个例子是识别文本中的命名实体,例如,“‘Katy Perry住在美国’”。这里,Katy Perry和USA分别是PERSON和LOCATION类型的命名实体。另一个例子是识别文本中表达的情感,例如,“这部电影太棒了”。在这里,表达的情绪是积极的。最后,识别文本的不同语言方面,例如词性标签、名词短语、依赖分析等,这些可以作为附加IE任务的特征。本教程向参与者介绍a)基于Python的开源工具的使用,这些工具支持来自社交媒体数据(主要是Twitter)的IE,以及b)确保研究可重复性的最佳实践。参与者将学习和实践各种语义和语法IE技术,这些技术通常用于分析推文。此外,学员将熟悉公开的社交媒体数据(包括流行的NLP和IE基准)以及收集和准备这些数据进行分析的方法。最后,参与者将被训练使用一套开源工具(帆为主动学习,TwitterNER命名实体识别,TweetNLP基于变压器NLP,和SocialMediaIE多任务学习),它利用先进的机器学习技术(如深度学习,主动学习与human-in-the-loop、多语种、多任务学习)来执行自己IE或现有的数据集。参与者还将学习如何将社会背景整合到信息提取系统中以使其更好,以及时间在社交媒体IE质量中的作用。本教程中介绍的工具将重点介绍IE的三个主要阶段,即数据收集(包括注释)、数据处理和分析以及提取信息的可视化。更多详情请访问:https://socialmediaie.github.io/tutorials/。







成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2023年1月25日
Arxiv
0+阅读 · 2023年1月13日
Arxiv
24+阅读 · 2021年8月12日
Arxiv
23+阅读 · 2019年12月12日
Arxiv
15+阅读 · 2018年1月5日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年1月25日
Arxiv
0+阅读 · 2023年1月13日
Arxiv
24+阅读 · 2021年8月12日
Arxiv
23+阅读 · 2019年12月12日
Arxiv
15+阅读 · 2018年1月5日