安利一个开源的好工具Label Studio, 闭环数据标注和模型训练

原创 · 作者 | Johnson
职业 | 菱歌科技Datatouch项目算法工程师
研究方向 | 自然语言处理
本示例是NLP示例,实际也可以用于图像工作。
官方仓库代码:
label-studio: heartexlabs/label-studio
textbrewer: airaria/TextBrewer
我的测试代码:
johnson7788/label-studio
johnson7788/TextBrewer
一、简介
1.1 在NLP日常工作中,我们需要按几个步骤进行数据处理和模型训练。
1. 先收集数据:通过爬虫或者其它工具,将数据结构化保存到数据库中。
2. 数据预处理:其中大部分都是无标签数据,对于无标签数据的可以用无监督做预训练模型,也可以用经过整理后进行标注变成有标签数据。
3. 数据标注:对于NLP的标注,我们常用的标注包括文本分类,命名实体识别,文本摘要等。
4. 模型训练:对打好标签的数据进行训练,参数调优等
5. 模型评估:对测试数据或开发数据进行评估,判断模型好坏
6. 不断重复1-5步,优化模型和数据,提高模型性能。
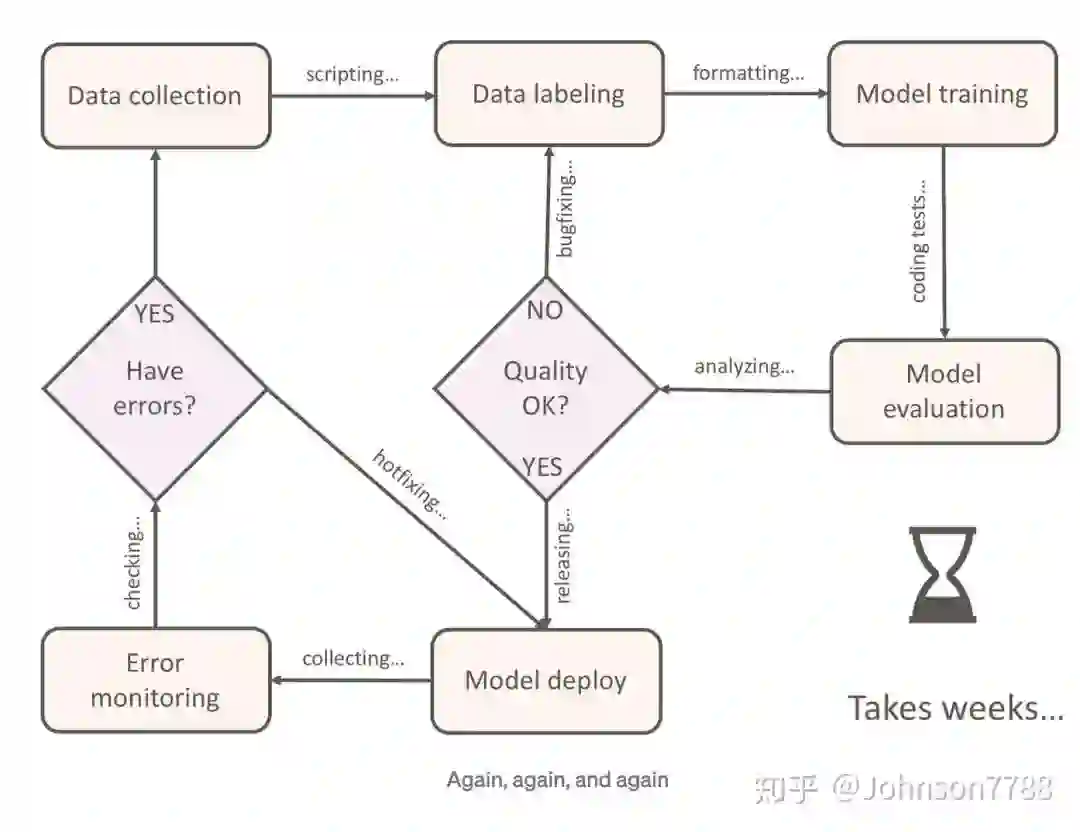
1.2 通常完成这些步骤耗时数周的时间,所以我们需要整合相关功能到自动化的平台。
本文使用的是工具有:
label-studio: 数据标注工具
transformers: 高度集成的模型训练套件
TextBrewer: 哈工大模型蒸馏工具
flask: 自定义一些api,把标注和模型训练串联起来
二、label-studio
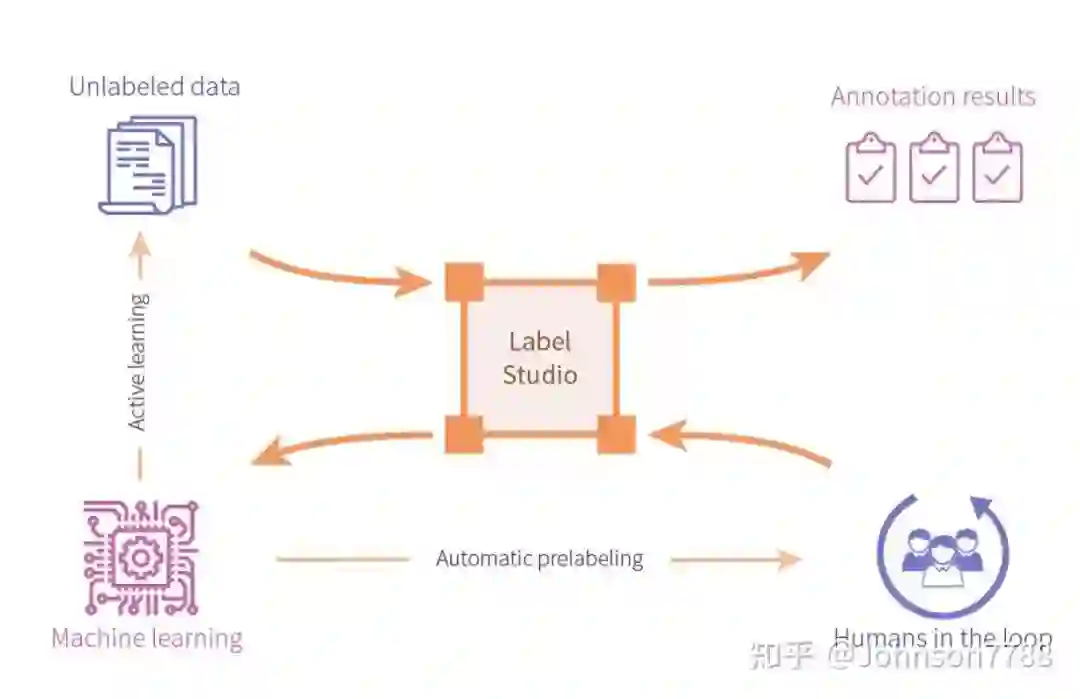
2.1 label-studio扮演的角色
如下图,label-studio用于连接各个数据导入,数据标注,调用模型训练标注好的数据的作用。
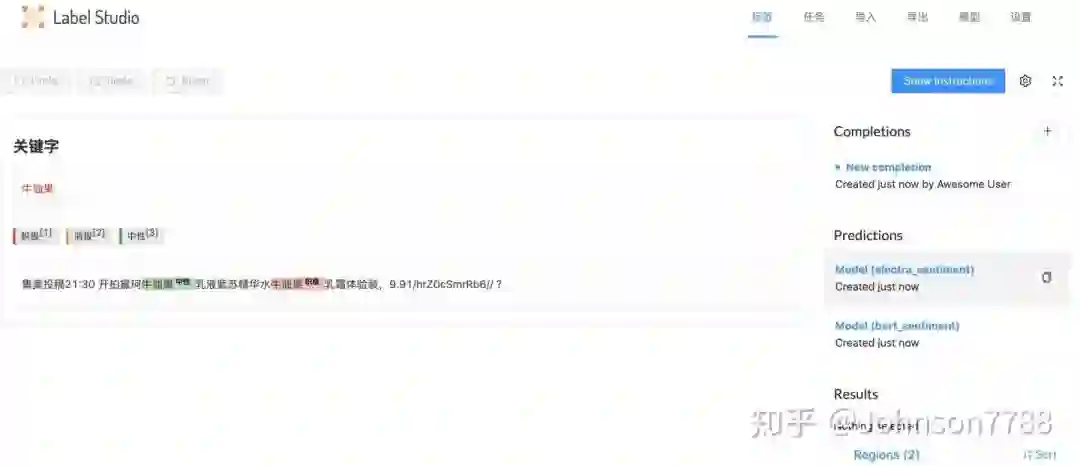
预览图: 关键字情感分类的标注示例,可以关联多个模型的预测结果,例如使用bert和electra2个模型作为ML后端
2.2 Features
可配置: 使用jsx tags配置,自定义配置标注页面,所以可标注格式很多,样式也可以自定义
协作标注: 由两个或更多人label同一任务,然后比较结果,还支持用户名密码简单的认证。支持按预测的模型预测的probability的大小顺序标注,默认按导入数据的索引顺序标注。
多种数据类型: 您定义自己的具有不同的label类型, Images, Audios, Texts, HTMLs,已有大量模板,直接使用接口
支持导入格式: JSON, CSV, TSV, RAR and ZIP archives,支持API导入数据。
NPM嵌入: 前端是NPM包, NPM package. 您可以将其包含在您的项目中 .
机器学习: 机器学习的集成支持。可视化并比较来自不同模型的预测。pre-labeling功能很好,可以实现用训练的模型预标注数据,那么结果人工标注前就比较方便,而且还知道模型预测的怎么样
支持docker容器部署
方便的API接口
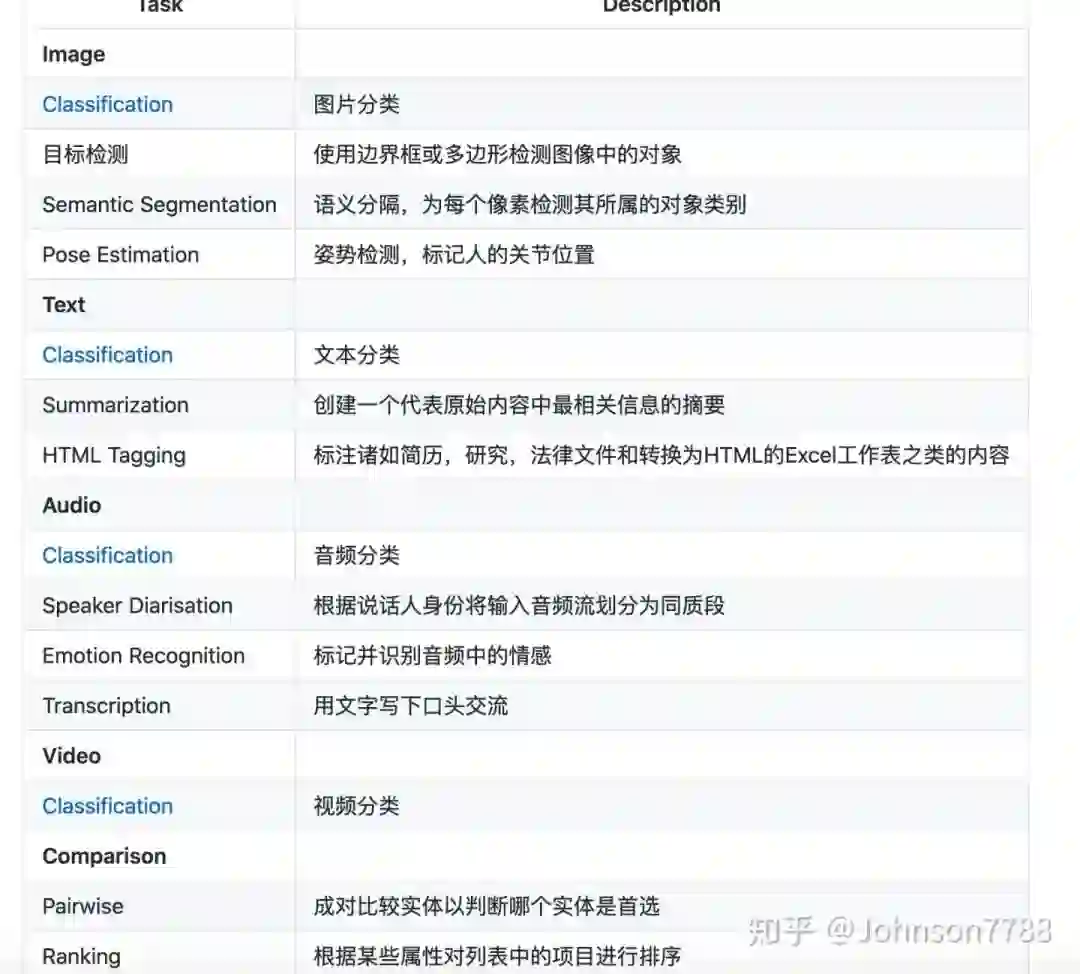
具体支持的标注内容如下:
三、使用方法
3.1 调用API
我们要利用label-studio的API实现以下功能:
导入数据-->人工打开label-studio标注数据-->训练模型-->训练好的模型预测未标注数据,辅助人员标注
/api/project GET 返回项目的设置和状态,状态包括任务和完成的数量 POST 创建一个任务,带desc参数作为项目的标题 PATCH 更新任务设置
/api/project/config POST修改配置文件
/api/project/import POST 导入数据
/api/project/export GET 导出数据
/api/tasks GET 获取所有数据; DELETE方法 删除所有task数据,删除所有task, 数据, 同时会删除已标注的数据
/api/tasks/<task_id> GET 获取第几条数据; DELETE delete specific task
/api/tasks/<task_id>/completions POST create a new completion; DELETE delete all task completions
/api/tasks/<task_id>/completions/<completion_id> PATCH update completion; DELETE delete completion
/api/completions GET returns all completion ids; DELETE 删除所有已完成的标注样本
/api/models blueprint.py 文件 GET 列出所有模型; DELETE 删除模型,json格式的参数name 是模型的名称
/api/models/train POST 训练模型
/api/models/predictions?mode={data|all_tasks} GET | POST
mode=data: 如果/api/models/predictions?mode=data, 需要post data内容,用json的格式,预测data的数据
mode=all_tasks: 对所有的本地的数据进行预测
3.2 操作顺序
省略克隆项目,安装requirements.txt依赖包等配置工作
初始化label-studio项目,配置项目设置config.json, 配置页面标签样式config.xml
如果启动机器学习或者深度学习的模型辅助预测和训练,那么初始化ML后端
使用/api/project/import导入数据,或者在初始化label-studio项目时,使用命令导入数据
修改ML后端的训练和预测的代码的函数,保证训练和预测的函数是可以正常运行的
开始标注数据,例如标注了100条后,训练模型
继续标注数据时,就会加载预测模型的结果,辅助标注
3.2.1 启动label-studio
我们先判断是否需要启动机器学习后端,如果不需要启动机器学习后端(不会pre-labeling辅助标记和训练模型),那么只用打标功能:
#表示启动一个项目,名字是text_classification_project,模板是text_named_entity
label_studio/server.py start text_classification_project --init --template text_named_entity --ml-backends http://localhost:9090
#或者启动一个已有的project,如果已经初始化
label_studio/server.py start text_classification_project --debug -b
文件说明
```buildoutcfg
text_classification_project/ #项目目录
├── completions 标注完成的数据保存的文件夹
│ ├── 0.json 一条标注完成的数据
│ ├── 1.json
├── config.json 项目配置文件
├── config.xml 标注页面样式显示的配置,可以自己按照自己需求设置,只需要懂一点前端的代码格式即可
├── export
│ └── 2020-12-28-11-44-52.zip #标注完成导出的数据
├── source.json 存储数据的元信息
└── tasks.json 一条未标注的数据,数据会导入到这里
```3.2.2 启动ML后端
这里我们可以添加多个ML后端,方便标注人员进行实时对比哪个模型的pre-labeling更好一些
# 初始化一个ml的后端
label-studio-ml init my_ml_backend --script label_studio/ml/examples/simple_text_classifier.py
# 启动一个已存在ml后端
方法1:
```buildoutcfg
label-studio-ml start my_ml_backend
```
或方法2:
```buildoutcfg
python my_ml_backend/_wsgi.py --log-level DEBUG --debug
```3.2.3 导入数据
调用label-studio的/api/project/import 接口导入数据,需要实现自己的代码, 例如从自己的各种数据库或者hive中获取数据获取数据,如果是txt文本或者csv,json等,都可以直接初始化的时候直接通过命令行导入。
headers = {'content-type': 'application/json;charset=UTF-8'}
host = "http://localhost:8080/api/"
def import_data():
"""
导入数据
:return:
"""
data = [{"text": "很好,实惠方便,会推荐朋友"}, {"text": "一直买的他家这款洗发膏,用的挺好的,洗的干净也没有头皮屑"}, {"text": "不太顺滑"}, {"text": "特别香,持久"}]
r = requests.post(host + "project/import", data=json.dumps(data), headers=headers)
pp.pprint(r.json())3.2.4 修改ML后端的训练和预测函数
训练和预测的函数也可以是api调用,也可以是参考heartexlabs/label-studio-transformers与transformers集成,这里我调用的是自己写的bert模型和electra模型,2个ML模型作为后端。
# ML后端的文件说明
这里只需要修改_wsgi.py 和simple_text_classifier.py(这是自定义的)中的代码即可
```buildoutcfg
my_ml_backend/
├── Dockerfile 可以制作docker镜像
├── README.md
├── _wsgi.py 函数入口
├── simple_text_classifier.py 被_wsgi.py入口函数调用,这个文件主要实现训练和预测2个函数
├── docker-compose.yml docker compose启动docker
├── requirements.txt 自定义requirements
├── supervisord.conf supervisor 函数docker中使用
└── uwsgi.ini docker中使用
```3.2.5 标注数据
默认打开的网页是, 127.0.0.1:8080
如图3所示,开始标记,如果你已添加的模型的预测功能已经可以正常预测,那么页面右侧会显示哪个模型可用,可用模型的预标记pre-labeling结果。
3.2.6 训练模型
点击127.0.0.1:8080/model开始训练模型,或者调用/api/models/train训练模型
循环导入数据,标注数据,训练模型,完成整个流程。
四、页面展示
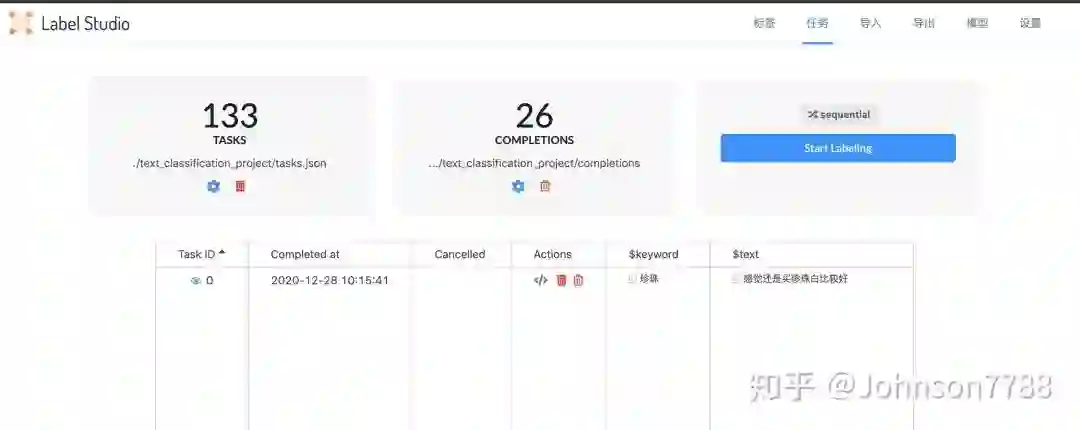
任务页面: 显示共有多少条数据,标记完成多少条数据,默认按索引(sequential)顺序进行标注,也可以按照其它方式标注,例如prediction-score-min表示预测的分数最小的先标注,使用的是task["predictions"]的"score"字段, prediction-score-max 使用预测的分数最大的顺序。
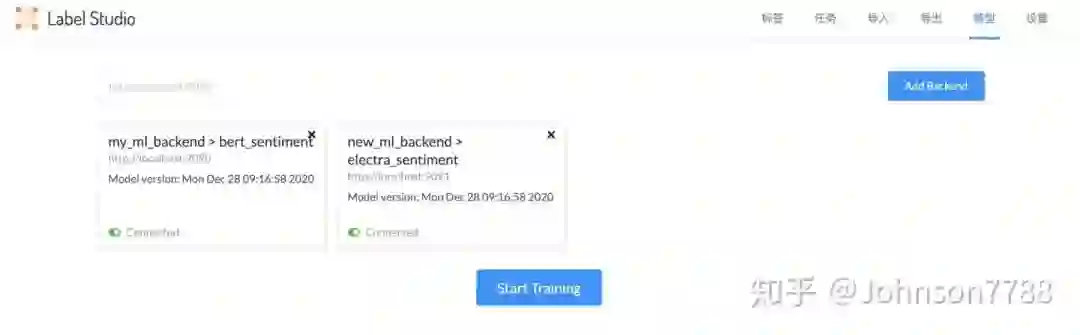
模型页面:
显示自定义的ML模型,可以添加多个,分别预测结果辅助标注人员标注数据
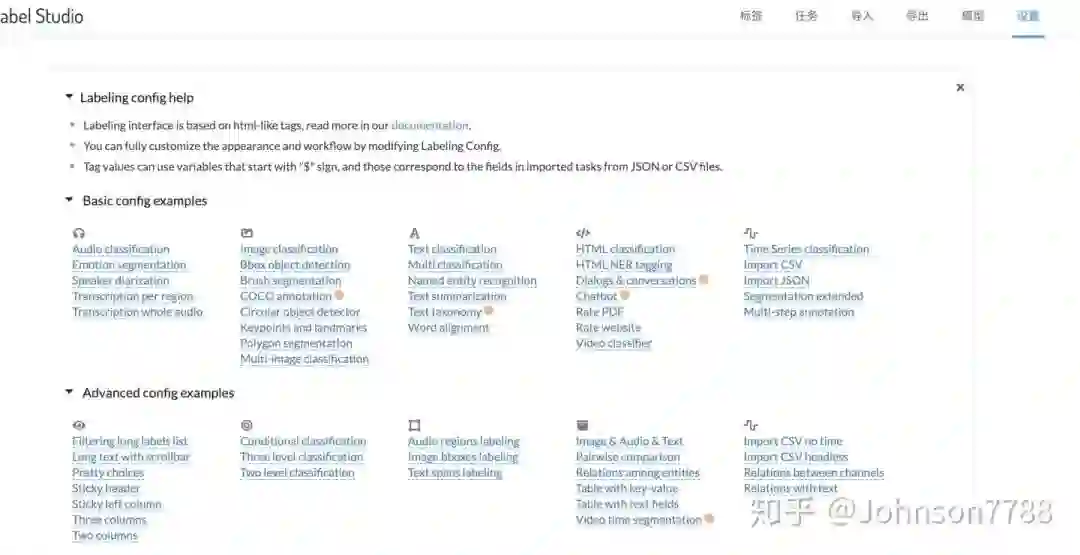
标注页面样式设置
预设多种Basic config, 支持不同的数据格式的标注,点击后可以进行预览。
五、结论
label-studio支持文本,图片,视频,时间序列等各种标注,格式丰富,前后端分离,丰富的API,可以二次开发,只需要开发数据导入,自定义ML后端模型的预测和训练函数即可。
本文由作者授权AINLP原创发布于公众号平台,欢迎投稿,AI、NLP均可。原文链接,点击"阅读原文"直达:
https://zhuanlan.zhihu.com/p/339567115

推荐阅读
专注于金融领域任务,首个金融领域的开源中文预训练语言模型 FinBERT 了解下
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


