1 引言
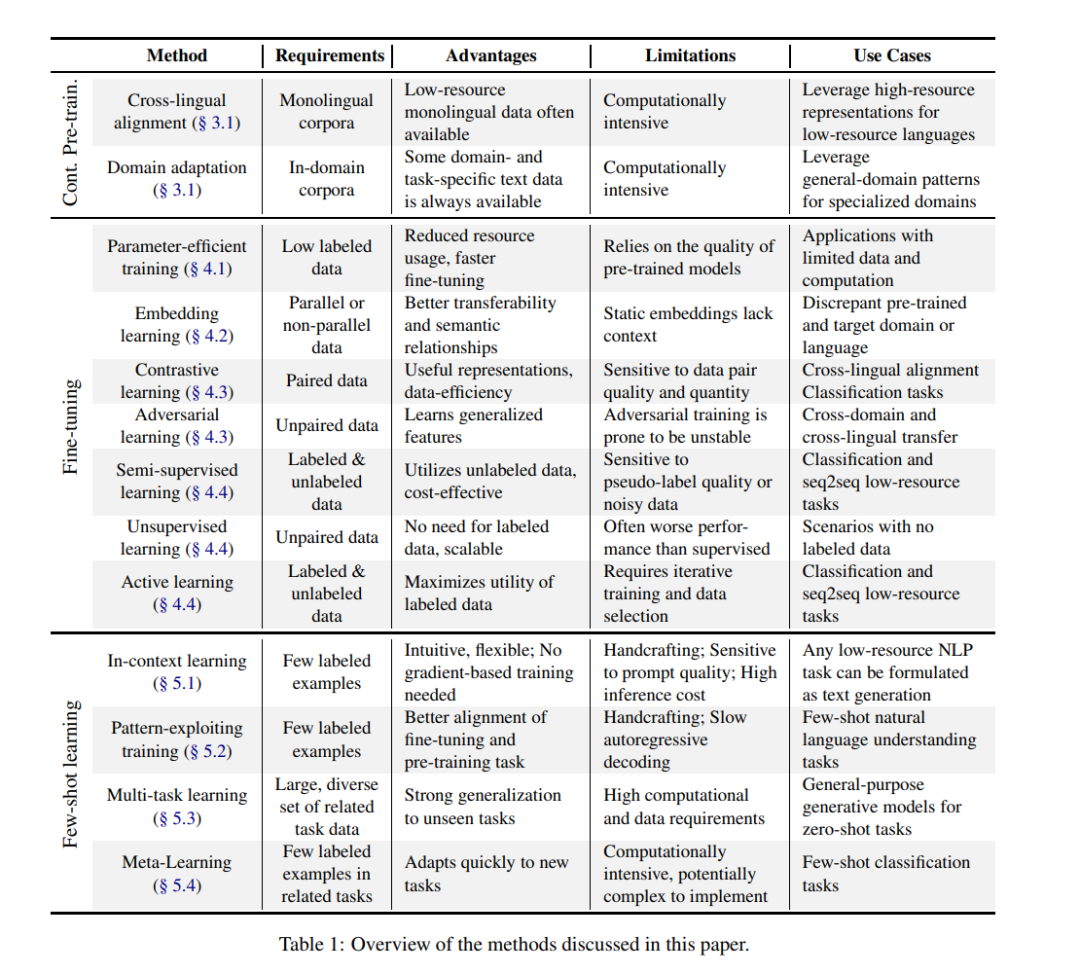
预训练语言模型(PLMs)正在改变自然语言处理(NLP)领域,展现出从复杂且多样化的领域中学习和建模自然语言数据底层分布的卓越能力(Han 等, 2021)。然而,这些模型的训练通常需要大量数据和计算资源,这在许多现实场景中可能是难以承受的(Bai 等, 2024),尤其是在非英语语言和特定领域中,例如医学(Crema 等, 2023;Van Veen 等, 2023)、化学(Jablonka 等, 2024)、法律(Noguti 等, 2023)、金融(Zhao 等, 2021)、工程(Beltagy 等, 2019)等。应对这一常见问题的主要方法依赖于迁移学习范式,该范式包括在大量通用或混合领域数据上的自监督预训练阶段,随后是针对领域和任务的领域适应和微调或少样本学习阶段。然而,这一过程的第二阶段同样对数据需求很高。数据稀缺可能导致过拟合、泛化能力差以及性能欠佳的问题。在有限数据条件下微调PLMs需要慎重选择预训练策略、领域适应方法和高效的参数优化,以通过有效利用模型的已有知识实现最佳性能,同时避免灾难性遗忘(Kirkpatrick 等, 2017;Ramasesh 等, 2021)。 本文旨在解决在有限数据情况下训练大型语言模型(LLMs)的挑战,特别是在低资源语言和特定领域中。我们通过探索迁移学习的最新进展(见表1),对这一问题进行了深入研究。本文进行了一项系统性的综述,起始于从Scopus、Web of Science、Google Scholar和ACL Anthology中收集的超过2500篇论文。这篇综述面向NLP领域的研究人员和实践者,概述了当前最先进的方法,并为数据稀缺场景下优化模型性能提供了实用指南。 我们集中探讨了以下几个方面:
在低资源场景下有效利用先验知识的(持续)预训练方法的选择 (§ 3);
在微调 (§ 4) 和少样本学习 (§ 5) 过程中最大化有限数据的效用;
讨论各种迁移学习策略的假设、优点和局限性,并强调对研究人员来说尚未解决的挑战;
从任务特定的视角出发,提供针对不同数据稀缺程度的实用指导 (§ 6)。
希望本文能为研究人员和实践者提供克服数据受限挑战的全面视角,同时指出未来研究的潜在方向。