可解释机器学习
·


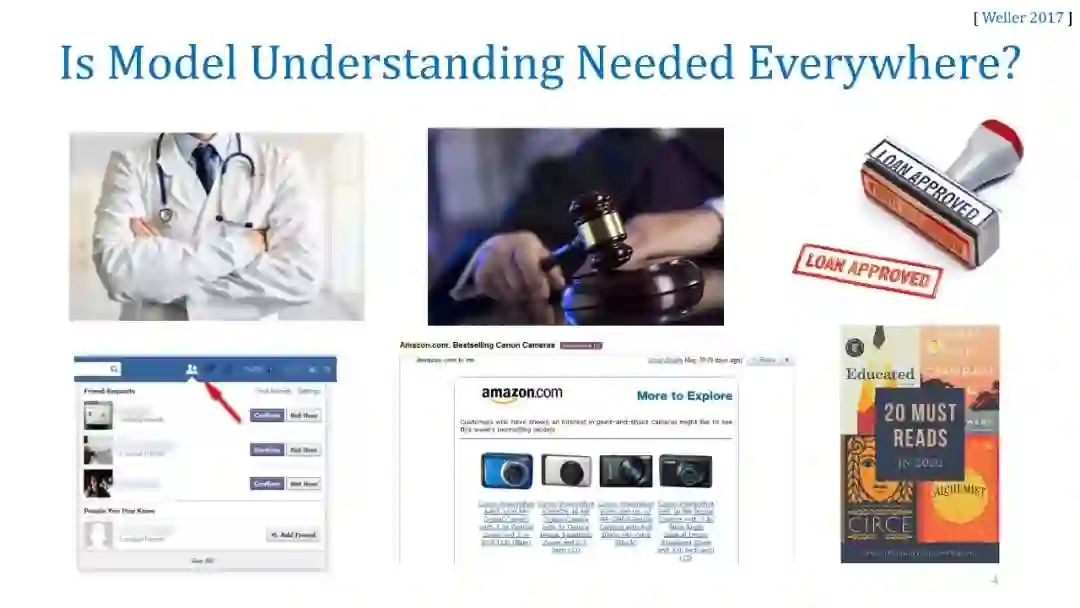
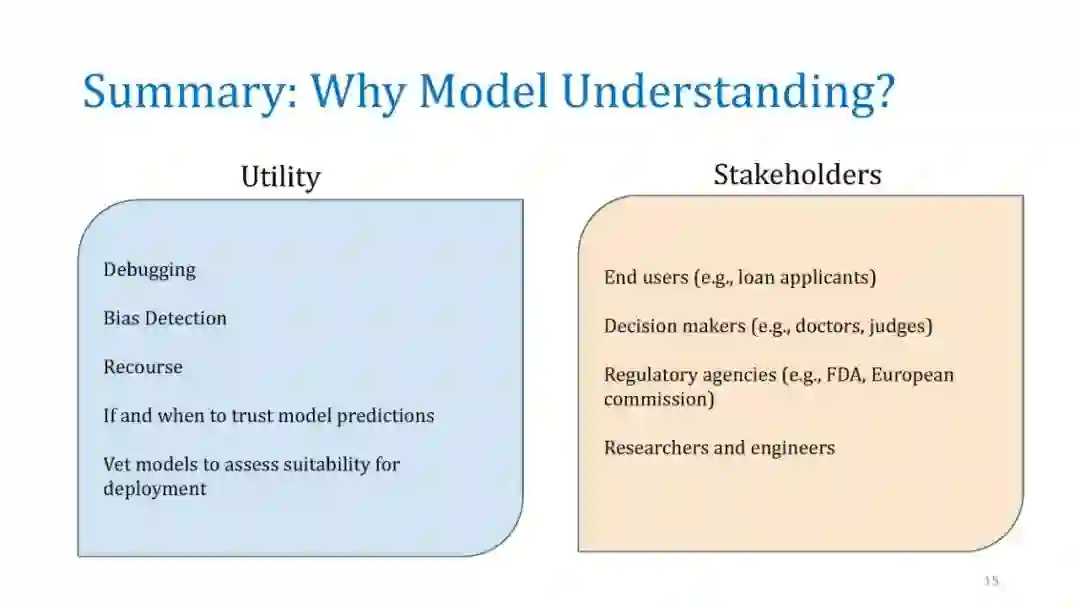
随着机器学习应用于社会的各个方面,确保利益相关者理解和信任这些模型变得越来越重要。决策者必须对模型行为有一个清晰的理解,这样他们才能诊断这些模型中的错误和潜在的偏见,并决定何时以及如何使用它们。然而,在实践中部署的大多数精确模型是不可解释的,这使得用户很难理解预测来自哪里,因此很难信任。最近关于机器学习中解释技术的研究提供了一个有吸引力的解决方案:它们通过用更简单的模型近似复杂的机器学习模型,为“任何”机器学习模型提供直观的解释。
在本教程中,我们将讨论几种事后解释方法,并重点讨论它们的优缺点。我们将涵盖三大类技术:(a)单实例基于梯度的归因方法(显著图),(b)通过扰动的模型不可知论解释,如LIME和SHAP,以及(c)全局可解释性的代理建模,如MUSE。对于每一种方法,我们将提供它们的问题设置、突出的方法、示例应用程序,最后讨论它们的漏洞和缺点。我们希望为机器学习中的可解释性提供一个实用而深刻的介绍。








成为VIP会员查看完整内容
相关内容
相关主题

相关VIP内容
相关资讯
相关论文