

高级持续性威胁(APT)是一种复杂的网络攻击,可以长时间不被发现,因此缓解这种威胁特别具有挑战性。鉴于其持久性,需要投入大量精力才能检测到它们并有效应对。现有的基于来源的攻击检测方法往往缺乏可解释性,误报率较高,而调查方法要么是有监督的,要么仅限于已知的攻击。为了应对这些挑战,我们引入了 SHIELD,这是一种将统计异常检测和基于图的分析与大型语言模型(LLMs)的上下文分析能力相结合的新型方法。SHIELD 利用 LLMs 的隐含知识来发现来源数据中隐藏的攻击模式,同时减少误报,并提供清晰、可解释的攻击描述。这降低了分析人员的警报疲劳,使他们更容易理解威胁状况。我们的广泛评估证明了神盾局在真实世界场景中的有效性和计算效率。结果表明,SHIELD 优于最先进的方法,实现了更高的精确度和召回率。神盾将异常检测、LLM 驱动的上下文分析和先进的基于图的相关性整合在一起,为 APT 检测确立了新的基准。
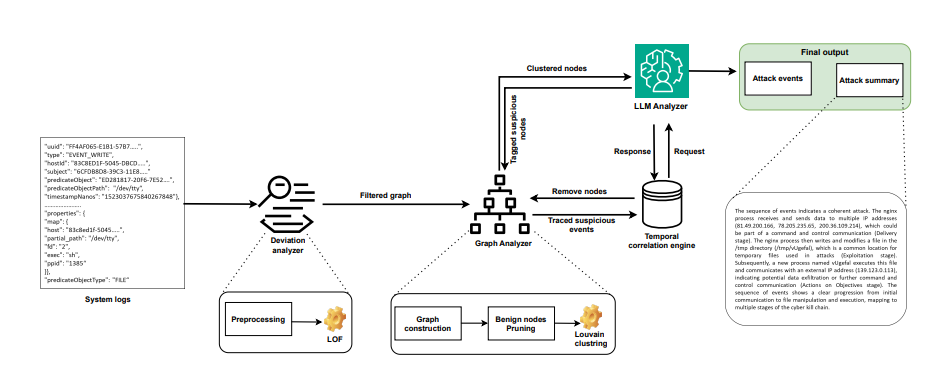
图 1. SHIELD概览,以实例展示四个模块之间的互动。
高级持续性威胁(APT)因其复杂性和隐蔽性,正日益成为当今组织关注的问题。2020 年 SolarWinds 供应链攻击事件[20]中,攻击者在超过九个月的时间里未被发现,同时入侵了 18,000 家组织和美国主要政府机构,这表明了 APT 可能造成的危害。另一个 APT APT-C-36(Blind Eagle)自 2018 年以来一直积极针对南美洲的金融和政府部门,采用先进的社交工程和无文件恶意软件技术来逃避检测,同时在被入侵的网络中保持长期存在。这些事件显示了 APT 是如何长期存在而不被发现的,凸显了对复杂检测方法的迫切需求,这种方法既能识别威胁,又不会让安全分析人员因误报而不知所措。
对系统出处数据的分析捕捉了进程、文件和网络连接之间随着时间推移而产生的详细关系和互动,已成为一种很有前途的 APT 检测方法 [33,16]。通过全面记录系统活动及其依赖关系,出处数据可以揭示复杂攻击所特有的微妙模式和横向移动。现有的检测方法依赖专家定义的规则来识别来源数据中的已知攻击模式 [14,24,12,19]。这些基于规则的方法虽然能有效对付已知威胁,但需要不断更新,而且难以对付零日攻击。为了解决这些局限性,研究人员转向了基于机器学习的异常检测方法,这种方法可对正常系统行为建模,以识别偏差。这些方法包括统计分析[14,13,26,19,5,22],以及使用路径[6,31,8,1]和基于图的架构[11,27,30,17,28]进行模式识别的深度学习模型。
然而,当前的机器学习(ML)方法面临两个重大局限。这些方法需要大量的训练数据,难以适应系统行为和攻击模式演变的动态性质,导致误报率较高。此外,解释警报的现有方法依赖于标注的训练数据,而这些数据的生成非常繁琐,而且很快就会过时[1,24,14,12],或者只关注 ML 的可解释性,而不是攻击的具体特征。
大型语言模型(LLMs)的最新进展为理解和推理复杂的系统行为带来了新的能力。这些模型具有适应不同环境和为其发现提供逻辑解释的卓越能力,可以作为新的 APT 检测方法的基础,克服现有方法的不足。不过,LLMs 也有两个关键的局限性。首先,直接向 LLMs 提供原始系统日志是不切实际的,而且效率低下,需要使用异常检测等传统安全分析方法向其提供经过预处理的日志。其次,LLMs 容易产生幻觉,这可以通过提示工程、思维链推理和验证检查等多种互补技术来解决。
为了应对这些挑战,我们提出了 SHIELD,这是一种将无监督异常检测与语言模型推理相结合,用于 APT 检测和调查的新型框架。我们的框架以滑动窗口机制累积系统日志进行分析,同时利用时间相关性引擎跟踪可疑事件的历史演变,从而实现对跨度长的攻击的检测。拟议的短窗口机制对于快速识别威胁至关重要,因为它能以最小的延迟检测和响应攻击。SHIELD (1) 采用统计分析来标记异常事件;(2) 构建出处图以确定关系;(3) 修剪良性活动;(4) 使用社区检测算法对可疑事件进行聚类。这些步骤可将大量系统事件缩减为简明的可疑活动群组,保留重要的攻击模式。然后,LLM 对确定的群组进行多阶段推理,提供可解释的见解,并将其映射到 APT 杀戮链。
时间关联引擎可持续比较新警报和历史事件。它利用衰减和强化机制进行动态置信度评分。如果被标记的进程持续表现出良性行为,衰减机制就会降低置信度分数,而当跨时间窗口检测到更多攻击阶段时,强化机制就会提高分数。这种双机制方法在保持实时检测能力和确保低误报率的同时,还能保持对缓慢演变攻击的全面了解。与只关注异常或基于规则的检测的现有方法不同,SHIELD 将这些技术与基于 LLM 的推理相结合,弥补了检测与可操作的安全见解之间的差距。
我们在四个不同的数据集上对 SHIELD 进行了评估:DARPA Eng. CADETS和THEIA数据集、公共竞技场数据集以及包含Blind Eagle APT-C-36活动的内部数据集。神盾局仅使用每个数据集的 30% 进行训练,就在 CADETS 数据集上实现了完美的精确度,并在所有数据集上保持了较高的召回率(0.93-1.00)。SHIELD 成功追踪了多天的攻击,详细的攻击叙述精确映射了 APT 从初始入侵到横向移动和数据外渗的各个阶段。最值得注意的是,在分析关键的 CADETS 攻击序列时,神盾局识别出了 25 个真正的阳性事件,而误报率为零,而基线方法则产生了 4000 多个需要分析师调查的误报事件。
这项工作的主要贡献可归纳如下: (1) 据我们所知,我们是第一个将 LLMs 用于 APT 检测和调查的人。通过将 LLM 推理与传统安全分析相结合,我们的框架实现了高检测精度,同时将误报率降至最低。(2) 我们开发了一种新型引擎,它可以利用具有强化和衰减机制的动态置信度评分来跟踪跨度较长的攻击,从而有效识别缓慢演变的隐形攻击。(3) 我们设计了一个新颖的框架,能够生成人类可理解的综合攻击摘要,将攻击事件映射到杀伤链阶段。这些包含相关 IoC 的摘要使安全团队能够快速分析和应对潜在威胁。(4) 我们利用现成 LLM 的功能,无需进行传统的模型训练。基于深度学习的方法会受到概念漂移的影响,而我们的系统则不同,它通过对组织变化进行基于提示的情境化处理来保持适应性。

