

社交媒体和平台利用审核来删除不受欢迎的内容,如网络欺凌,这是一种通过任何类型的数字技术(如社交平台)对个人或群体实施的攻击行为。然而,人工审核平台几乎是不可能的,因此对自动审核的需求正在上升。有关社交平台上网络欺凌检测技术解决方案的研究很少,而且大多集中在机器学习模型上,用于检测与平台审核无关的网络欺凌。本研究旨在通过使用 GPT-3 大语言模型加强对网络欺凌检测模型的研究,缩小与平台审核的差距。该模型经过调整和测试,可使用流行的网络欺凌数据集检测网络欺凌,并使用常见的性能指标与之前的机器学习模型和大语言模型进行比较。此外,还对模型的延迟进行了测量,以测试它是否可用作自动调节工具来检测社交平台上的网络欺凌。结果表明,该模型与之前的模型相当,在网络欺凌检测中,微调大语言模型是调整模型的首选方法。此外,结果表明,大语言模型的延迟比机器学习模型高,但可以通过使用多线程来改进,并可用作检测网络欺凌的平台调节工具。
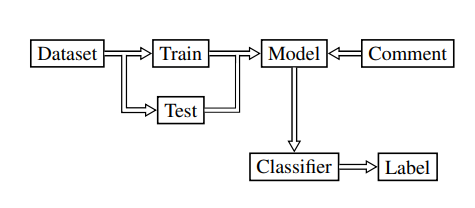
图 1:分类过程。数据集分为训练集和测试集。首先对模型进行训练,然后进行评估,从而建立分类器。然后,分类器会收到来自平台的评论以进行分类,并返回分类标签。
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2024年3月5日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
89+阅读 · 2021年10月21日
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2024年3月5日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
89+阅读 · 2021年10月21日