生成式人工智能的能力显著增强,极大地扩展了其在医学领域的应用场景。我们提供了一个全面的概述,涵盖了生成式人工智能在临床医生、患者、临床试验组织者、研究人员和培训人员中的应用案例。接着,我们讨论了实现这一潜力所需克服的诸多挑战——包括保持隐私和安全、提高透明度和可解释性、维护公平性以及严格评估模型——以及这些挑战所带来的开放研究方向。
1. 引言
对生成式人工智能在医学中潜力的兴奋感激发了大量新应用的涌现。生成模型有潜力改变医疗服务的提供方式(1-5)、医疗服务提供者的角色和职责(6, 7),以及患者与提供者之间的沟通路径(8, 9)。更上游,生成模型在改善医学科学发现方面显示出前景(通过临床试验(10, 11)和观察性研究(12, 13)),并促进医学教育(8, 14)。这些进展直接源于生成式人工智能的技术突破,极大地提高了生成逼真的语言和图像的能力,并引发了如何将生成模型融入医学中的重要问题。
生成式人工智能是继往技术进展中的最新一项,推动了医学中的重大变化。过去的重要进展包括电子健康记录(EHR)的采用;机器人技术在远程手术中的整合(15);以及预测模型和持续监测作为新诊断工具基础设施的构建(16, 17)。然而,将新技术引入健康领域不可避免地会带来新的挑战。例如,EHR的引入导致了数据隐私问题和数据安全泄露(18, 19)。虽然EHR的引入在减少医疗错误和改善医疗指南遵循方面产生了显著的积极影响(20),但也引入了其他类型的错误(21)。类似地,医疗保健环境中的持续监测设备导致了普遍的警报疲劳(22)。总体而言,技术在医学中的整合需要一个迭代设计过程,既要解决陷阱,又要放大其益处(23)。
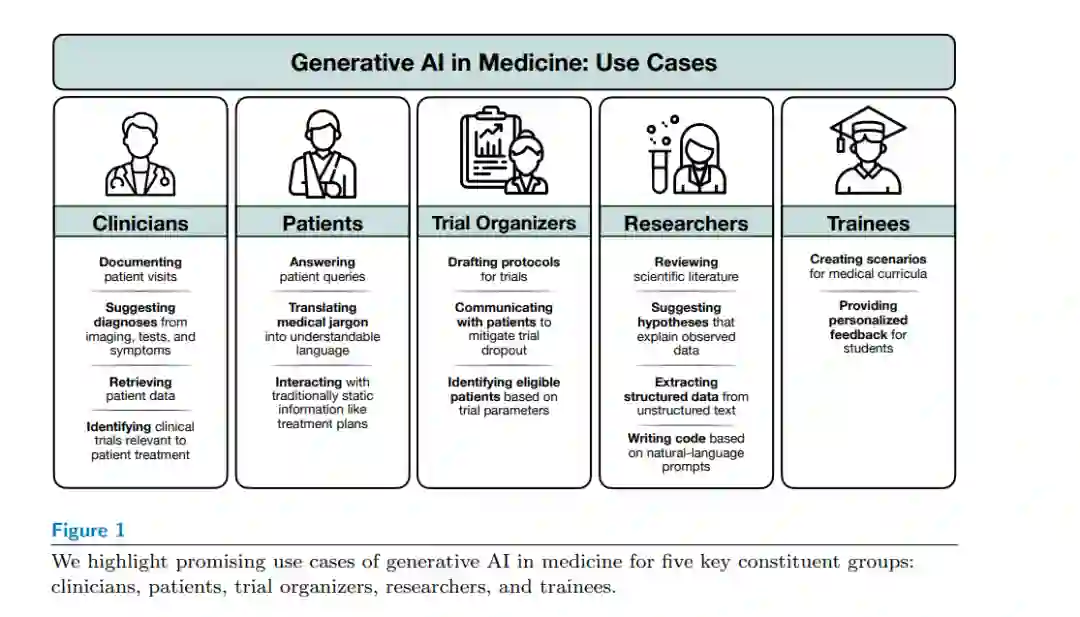
生成式人工智能同样如此。随着生成模型成为医学领域研究和应用的领先方向,我们将全面回顾它们所启用的新应用以及所带来的新挑战,特别关注用户如何与生成模型互动。我们首先简要概述生成式人工智能,详细介绍其主要类型以及它们如何融入医学中的机器学习广阔领域。接下来,我们将讨论生成式人工智能在医学中的众多应用案例,按潜在用户分类:临床医生(§2.1)、患者(§2.2)、临床试验组织者(§2.3)、研究人员(§2.4)和培训人员(§2.5)。然后,我们强调必须解决的挑战(§3),以实现这一潜力并安全部署生成模型(包括确保知情同意、保护隐私、提高透明度等),并在整篇文章中讨论未来的研究方向。
1.1 生成式人工智能背景
生成建模是人工智能的一个基本范式,与预测建模(也称为判别建模)相对立:预测模型接受输入并尝试预测其标签,但不试图建模输入,而生成模型则试图建模输入。例如,预测模型可能会接受一份临床记录(输入),并尝试预测该记录是否表明存在癌症(标签),而生成模型则旨在建模临床记录文本本身的分布。由于生成模型的训练目标是建模整个数据分布,它们具备生成新数据的强大能力:例如,生成新的临床记录。 基本的生成建模范式远早于当前生成式人工智能的兴起。例如,经典的生成建模方法,如马尔可夫链,已被用来建模词序列几十年(24),理论上可以用来写临床记录。然而,在实践中,经典的生成建模方法并没有生成足够逼真的内容,尤其是在处理复杂的医学数据时。当前的兴趣激增,源于生成建模能力的极大提高,这得益于深度学习架构和更大数据集的扩展(25)。这些改进,如我们所述,扩展了生成式人工智能模型的应用范围,并激发了在机器学习核心领域之外的应用兴趣(26)。
我们总结了三类生成模型,按模型操作的数据类型划分:(1)文本,(2)图像,或(3)文本和图像。对于每一类,我们重点介绍了当前正在使用的最先进的模型。虽然我们讨论的主要是文本和图像数据,因为这些与我们接下来讨论的应用案例最为相关,但其他类型数据(例如生理信号和分子图)上的生成模型也是临床人工智能研究的新兴领域(27-29)。有关更全面的概述,我们建议读者参考(30)。
对于文本建模,大型语言模型(LLMs) 是主流方法,近年来其性能有了显著提升。LLMs通常使用变换器神经网络架构(31)进行下一个词预测:给定一段词序列,预测下一个最可能的词是什么?也就是说,对于一个上下文序列x1,⋯ ,xnx_1, \cdots, x_nx1,⋯,xn,LLM被训练来预测p(xn+1∣x1,⋯ ,xn)p(x_{n+1} | x_1, \cdots, x_n)p(xn+1∣x1,⋯,xn)(32)。使LLM“庞大”的因素是其深度学习架构的规模,以及训练它所使用的数据和计算量;目前使用的大多数语言模型都被视为LLMs。训练LLM通常包括三个阶段:首先,LLM在从互联网上抓取的大型文本语料库上进行预训练;其次,进行微调,使用指令跟随示例,例如“将此出院记录转换为通俗语言”并给出合理的回应;第三,进行人类反馈的微调,由人类选择两个可能回应中的一个,以捕捉细致的偏好(33)。每个阶段可以更具体地定制到医学领域:一些模型在医学语料库上进行预训练,通常是PubMed,作为整个互联网的补充或替代(34, 35);有些模型专门使用像MedQA(36, 37)这样的数据集来回答医学问题;还有一些新兴的数据集包含了医生编写的医学查询回应,帮助将LLMs与医学最佳实践对齐(38)。虽然我们讨论的应用案例主要涉及基于人类语言训练的模型,但具有类似变换器架构的模型也可以在其他类型的生物医学序列数据上进行训练。例如,电子健康记录模型已在ICD代码序列上训练(39, 40);蛋白质模型在氨基酸序列上训练(41);DNA模型则在核苷酸序列上训练(42, 43)。
对于图像建模,扩散模型(44)最近成为首选方法,远远超越了前一代的生成对抗网络(45)。给定一个未标记的训练图像分布,扩散模型学习生成与训练分布相似的新合成图像。训练扩散模型时,一张真实图像x0x_0x0 会逐步被破坏,产生xtx_txt,这是经过t次破坏步骤后看起来像随机噪声的图像。模型被训练来通过学习分布p(xi−1∣xi)p(x_{i-1} | x_i)p(xi−1∣xi) 从噪声xtx_txt 重构原始的干净图像x0x_0x0。训练好的扩散模型可以从随机采样的噪声开始,并生成一张新图像,这张图像虽然不在训练集内,但看起来像是从相同的分布中抽取的。医学中的扩散模型已经在几种不同的图像类型上进行了训练,例如胸部X光、皮肤镜图像和病理切片(46)。为了提高生成图像的生物学有效性,正在开发数据集和方法,通过医生反馈来微调模型(47)。合成图像生成可以作为一种有用的数据增强技术,特别是在数据受限的环境中,监督机器学习模型可以从合成数据点中受益;最近的证据表明,这种技术可以帮助提高病理学和放射学任务的模型鲁棒性(13)。
对于涉及文本和图像的任务,有两类关键的生成模型:文本到图像(T2I) 和 视觉-语言模型(VLMs)。T2I模型接受一段文本作为输入,利用文本条件扩散模型生成相应的图像输出。这些模型由两个组件组成:一个文本编码器模型(即变换器(48)),以及一个生成图像的扩散模型,使用文本编码来生成图像。T2I模型通常使用一般的图像描述数据集进行预训练;然后可以针对医学进行微调,例如使用胸部X光和相应的放射学报告(49)。T2I模型进一步扩展了合成图像的可能性,例如,允许研究人员为特定患者病理生成训练数据。相关地,VLMs接受一张图像作为输入,并生成与图像相关的文本作为输出(50)。VLMs包括一个图像编码器模型(例如卷积神经网络或视觉变换器(48, 50)),以及一个基于图像编码生成文本的大型语言模型。VLMs还需要大量的图像-文本数据集,这些数据集可以包括图像描述或报告,也可以包括回答视觉问题,例如“这张胸部X光片是否显示胸腔积液?”(51)。它们可以应用于病理或放射学的问答和报告生成任务(52, 53)。
这些模型类别在医学中有着天然的应用。许多临床过程和决策涉及无结构的文本(如临床记录、在线健康信息和治疗计划)和医学图像。此外,图像和文本常常一起出现,尤其是在放射学报告中。下一节将详细阐述将这些生成建模范式与医学中的现有数据和过程结合的潜力。