视觉–语言–动作(Vision-Language-Action, VLA)模型将视觉–语言模型扩展到具身控制领域,通过将自然语言指令和视觉观测映射为机器人动作,实现从语言理解到物理交互的端到端控制。尽管具备强大的跨模态感知与决策能力,VLA 系统仍面临着巨大的计算与内存开销,这与需要实时性能的边缘平台(如搭载于移动机械臂上的板载计算设备)所受的资源限制形成了显著矛盾。如何在性能与资源约束之间取得平衡,已成为近年来研究的核心焦点。 鉴于学术界与工业界在构建高效、可扩展 VLA 系统方面的持续探索,本文对提升 VLA 效率的研究工作进行了系统性综述,重点关注如何降低推理延迟、内存占用以及训练与推理成本。我们将现有方法划分为四个维度:模型架构、感知特征、动作生成与训练/推理策略,并在每一类中总结了代表性技术。最后,本文探讨了未来的发展趋势与开放挑战,指出推动高效具身智能(efficient embodied intelligence)发展的潜在研究方向。
关键词:视觉–语言–动作模型;效率优化;机器人学习;具身智能
- 引言
传统的机器人系统依赖于任务特定的算法和手工设计的规则,这些方法在结构化环境中表现良好,但在非结构化、复杂的真实场景中往往难以泛化。深度学习的兴起彻底改变了这一范式,使模型能够自动提取层次化与可迁移的特征。在此基础上,视觉–语言模型(Vision-Language Models, VLMs)作为大型预训练多模态系统出现,通过对齐视觉输入与自然语言,实现跨模态的统一语义表示。将这一理念扩展至具身控制领域,视觉–语言–动作(Vision-Language-Action, VLA)模型进一步建立了从语言与视觉到机器人动作的端到端映射,使机器人能够在多样化场景与任务中实现通用控制。与传统方法相比,VLA 模型具有更强的语义理解与泛化能力,为机器人学中的操控、导航等应用提供了新的技术路径。 尽管具备巨大潜力,VLA 模型仍面临显著的效率挑战,严重制约了其实用化部署。许多现有的 VLA 系统复用了大型语言模型和复杂的视觉主干网络,导致模型参数量庞大、内存占用高、推理速度慢;同时,这类多模态模型的训练过程计算代价高昂。这些特性与机器人系统的常见约束(如板载计算资源有限、能耗受限以及严格的实时性要求)存在根本冲突,从而阻碍了 VLA 在边缘平台(如移动机械臂)上的落地。虽然在视觉–语言模型(VLM)中,效率优化已是成熟研究方向 [1],但这些技术难以直接迁移至 VLA 系统,因为 VLA 还需面临更多特有挑战: 它们必须生成时间一致的动作序列,在实时约束下运行,并在执行过程中保证物理可靠性。因此,过度压缩或剪枝操作可能严重损害性能,其影响远比在 VLM 中更为关键。这些差异表明,VLA 模型的效率问题亟需独立研究,而不仅仅依赖于 VLM 领域的经验。 VLA 的快速发展已经催生了若干综述。例如,[2] 提供了对 VLA 概念、架构、训练方法与应用的全面概述;[3] 深入分析了不同动作表示的类型及其优劣;[4] 则聚焦于自动驾驶这一具体应用场景。然而,这些工作均未从效率视角进行系统性总结,而随着模型规模的持续增长与实时性需求的提升,效率问题已成为制约实际应用的核心瓶颈。本文旨在填补这一研究空白,首次系统性地综述面向高效 VLA 模型的研究进展。
我们的主要贡献包括: 1. 据我们所知,这是首个专门聚焦于高效 VLA 的系统综述。我们从四个维度对效率提升方法进行分类:模型架构、感知特征、动作生成以及训练/推理机制。 1. 基于该分类体系,我们总结了主流的 VLA 效率增强策略,并分析其各自的优缺点。 1. 我们探讨了 VLA 的未来发展趋势,并指出在这些趋势下应优先关注的效率优化方向。
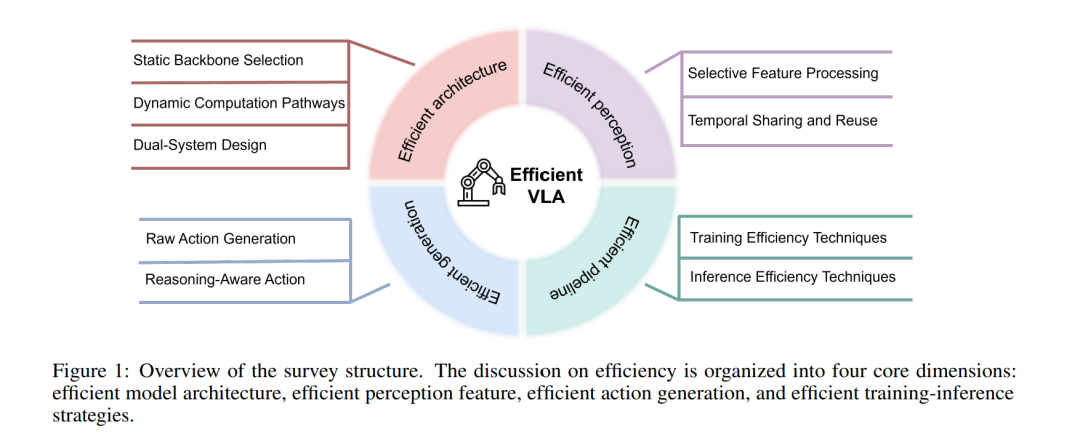
为实现上述目标,本文遵循典型 VLA 系统的处理流程(见图 1),涵盖模型架构、感知特征、动作生成与训练/推理四个环节,对其中提升效率的关键技术进行重点回顾,并在最后讨论开放挑战与潜在研究方向。本文结构安排如下: * 第 2 节:VLA 模型的演化 —— 回顾 VLA 模型的发展脉络,总结塑造其格局的代表性里程碑与技术进展; * 第 3 节:高效模型架构 —— 从静态主干选择与动态计算路径规划两方面探讨构建高效 VLA 架构的方法,并分析双系统设计带来的潜在效率收益; * 第 4 节:高效感知特征 —— 调研降低前端计算开销的方法,包括单帧内空间冗余消除与跨时间步特征复用; * 第 5 节:高效动作生成 —— 比较两类主流动作表示(原始动作与基于推理的动作),并回顾加速动作生成的相关方法; * 第 6 节:高效训练与推理 —— 综述模型全生命周期内的优化策略,包括低成本训练范式与部署时的推理优化; * 第 7 节:未来展望 —— 讨论 VLA 模型的未来发展方向,指出进一步提升其效率所需重点研究的关键问题。