

扩散模型在生成任务中取得了显著成功,但由于其迭代采样过程和二次注意力机制的计算成本,其推理开销仍然非常高。现有的无需再训练的加速策略虽然在一定程度上减少了每步采样的计算开销,但相较于原始模型,在生成结果保真度上仍存在明显差距。
我们认为,这一保真度缺口主要源于两个关键原因:(a) 不同的提示(prompt)对应着不同的去噪轨迹;(b) 现有方法普遍忽略了扩散过程背后的常微分方程(ODE)结构及其数值解的性质。
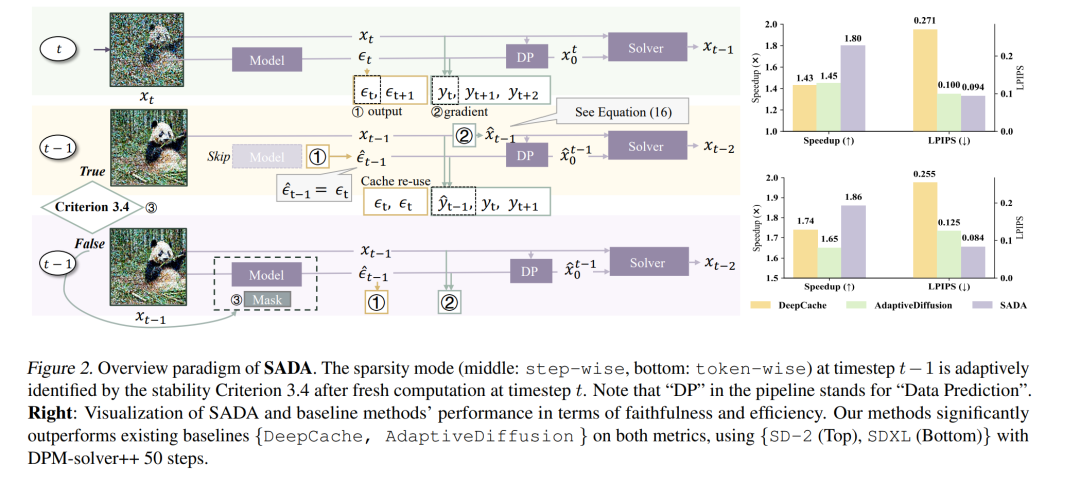
为了解决这些问题,本文提出了一种新颖的加速范式 SADA(Stability-guided Adaptive Diffusion Acceleration),该方法通过统一的稳定性准则,在每一步与每个token粒度上动态分配稀疏性,实现对基于ODE的生成模型(如扩散模型与流匹配模型)的高效采样加速。 具体而言,对于问题(a),SADA根据每条采样轨迹的稳定性自适应地调整稀疏策略;对于问题(b),SADA提出了基于数值ODE求解器的梯度信息的近似计算方案,以实现理论上更稳健的近似采样。
我们在SD-2、SDXL和Flux等主流模型上,结合EDM与DPM++两种ODE求解器进行了全面评估。实验结果表明,在基本无明显保真度下降的前提下(LPIPS ≤ 0.10,FID ≤ 4.5),SADA可实现至少1.8× 的采样加速,显著优于现有方法。
更重要的是,SADA具备良好的通用性,能够无缝适配不同的生成流程与模态:在无需任何修改的情况下可加速ControlNet,并在MusicLDM上实现1.8×加速,同时保持谱图LPIPS约为0.01的高保真输出。 项目代码已开源,链接如下:
https://github.com/Ting-Justin-Jiang/sadaicml
成为VIP会员查看完整内容
相关内容
Arxiv
40+阅读 · 2023年4月19日
Arxiv
214+阅读 · 2023年4月7日
Arxiv
81+阅读 · 2023年4月4日

相关VIP内容
相关资讯
相关论文
Arxiv
40+阅读 · 2023年4月19日
Arxiv
214+阅读 · 2023年4月7日
Arxiv
81+阅读 · 2023年4月4日