

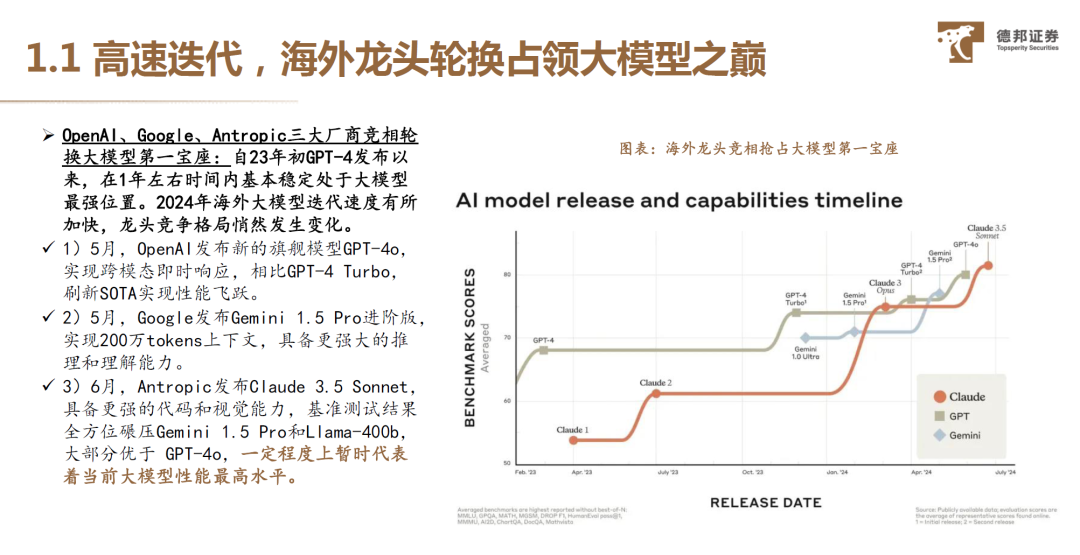
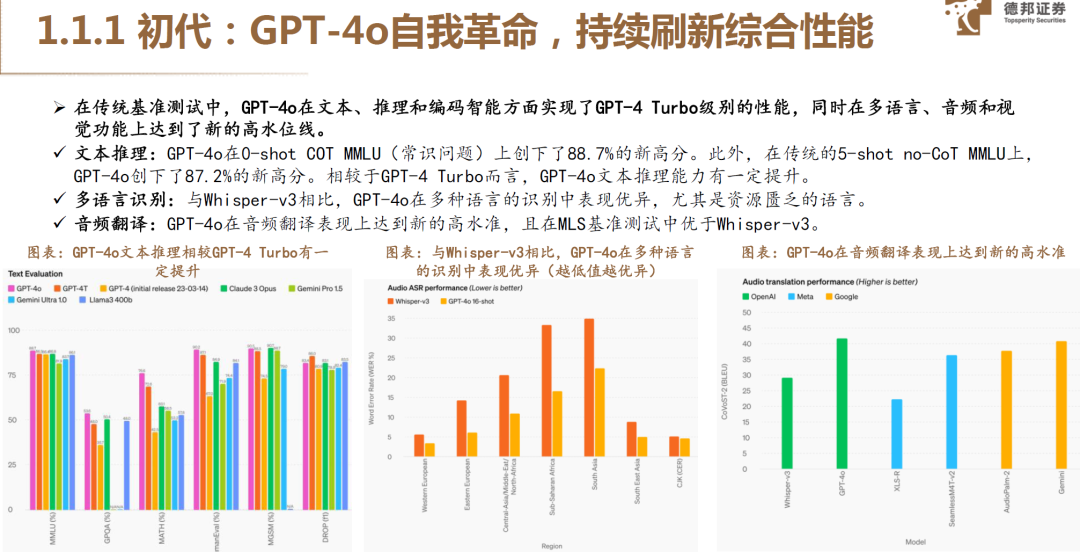
大模型的宝座三次更迭:初代GPT-4o自我革命,持续刷新综合性能;二代谷歌Gemini更极限的上下文理解、更低延时;翘楚Claude3.5聚焦视觉和交互体验。 大模型高地争夺:多模态的理解和响应,原生多模态技术比拼。大模型的效果取决于多模态理解与生成,毫秒级响应,更先进的视觉与音频理解能力,智能感知语气与语态。端到端原生多模态技术、统一神经网络,是竞争的主要角力点。 大模型的比较维度升级:从模型到叠加终端,跨设备的使用效果体验。如谷歌推出AI Agent项目Astra模型,可以手机、眼睛镜头对准身边的物品,并向Project Astra提出一些疑问,它几乎能做到零延时地准确回答。 国内大模型逆袭之路:聚焦长文本,降价迭代提升竞争力。 先文后理:理科目前差距较大,聚焦长文本,国产大模型已有赶超GPT之势,如通义千问、KIMI、山海等。 长文本的三大难度:注意力机制计算复杂度、上下文记忆、最长文本约束难题。 商业上降价,加速迭代卷出未来。头部智谱/字节跳动/阿里/腾讯/百度/讯飞低价迭代,百川智能/月之暗面/零一万物等初创公司并未加入降价行列。从技术来看,降价的背后是训练&推理成本的下降。


成为VIP会员查看完整内容
相关内容

Arxiv
219+阅读 · 2023年4月7日
Arxiv
151+阅读 · 2023年3月29日
Arxiv
84+阅读 · 2023年3月21日


相关VIP内容
相关资讯
相关论文
Arxiv
219+阅读 · 2023年4月7日
Arxiv
151+阅读 · 2023年3月29日
Arxiv
84+阅读 · 2023年3月21日