

现代机器学习(ML)应用经常部署在云环境中,以利用集群的计算能力。然而,传统的云计算方案无法满足新兴边缘智能场景的需求,包括提供个性化模型、保护用户隐私、适应实时任务和节省资源成本。为了克服传统云计算的局限,一种新趋势是利用设备上的学习范式,使端到端的ML过程更靠近边缘设备。因此,设备上学习的有望优势促进了微型机器学习(TinyML)系统的兴起,一个专注于在资源受限的边缘设备上,如微控制器、物联网(IoT)传感器和嵌入式设备,开发ML算法和模型的领域。“微型”这一术语强调了这些设备上有限的处理能力、内存容量和能源资源。正如§1.1中讨论的研究背景,TinyML已成为一个重要的研究主题,由于边缘智能应用的增长,包括智能家居、可穿戴设备、机器人和医疗服务。通过在无处不在的边缘设备上应用TinyML系统,开发者和研究者可以有效地减少推理延迟、节省资源成本、提高使用体验和保护用户隐私。
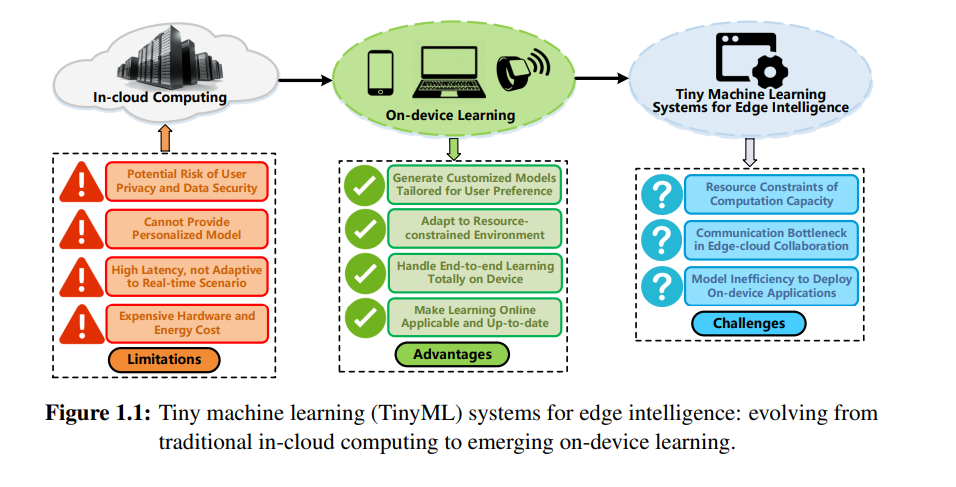
然而,在实践中实现一个高性能的TinyML系统并不容易。我们需要深入探讨基础架构设计和框架实现,从全栈的系统实现角度出发,包括减少数据规模、模型复杂度、计算开销和通信流量。为了构建一个高效的TinyML系统,我们总结了系统设计和实现中的三个核心挑战,在§1.2中。这些挑战激发了我们方法论的设计原则,对应于本论文在§1.3中的主要贡献。更准确地说,通过在第2章中对TinyML系统进行全面的背景回顾,我们打算从三个方面优化系统设计:(1)利用INT8量化感知训练在第3章中突破边缘设备上的计算资源限制,(2)在第4章中利用层次化的通道-空间编码来缓解边缘-云协作期间的通信瓶颈,(3)在第5章中探索补丁自动跳过方案以提高设备上模型执行效率。
首先,如第3章将讨论的,我们专注于打破有限资源的约束,减轻计算开销,并讨论如何提高设备上学习的计算速度。我们展示了在深度模型的前向和后向传递中使用8位固定点(INT8)量化是一种在实践中启用微型设备上学习的有望方式。一个高效的量化感知训练方法的关键是在保留每层训练质量的同时利用硬件级别启用的加速。我们在Octo中实现了我们的方法,一个轻量级的跨平台系统,用于微型设备上的学习。实验表明,Octo在训练效率上超过了最先进的量化训练方法,同时在处理速度和内存减少方面实现了充分精度训练的适当加速。
其次,如第4章将讨论的,我们还涵盖了连续数据分析和视频流应用。在这种情况下,通过减少流量大小来提高通信效率是现实部署中最关键的问题之一。现有系统主要在像素级别压缩特征,忽略了可以进一步利用以实现更有效压缩的特征结构特性。在这项工作中,我们通过对特征进行分层压缩,采取了名为Stripewise Group Quantization(SGQ)的新洞察来实现可扩展的CL系统。与以前的非结构化量化方法不同,SGQ同时捕获通道和像素中的空间相似性,并在这两个层面上编码特征,以获得更高的压缩比。实验表明,SGQ可以在流量大大减少的同时,仍然保持学习精度与原始全精度版本一致。这验证了SGQ可以应用于广泛的边缘智能应用。
第三,如第5章将讨论的,在资源有限的边缘设备上,实时视频感知任务通常因精度下降和硬件开销问题而具有挑战性,其中节省计算是性能改进的关键。现有方法主要依赖于特定领域的神经芯片或先前搜索的模型,这需要根据不同任务属性进行专门优化。这些限制激发了我们设计一种通用和任务独立的方法论,称为Patch Automatic Skip Scheme(PASS),通过解耦加速和任务来支持多种视频感知设置。要点是捕获帧间相关性,并在补丁级别跳过冗余计算,其中补丁是视觉中的非重叠正方形块。实验表明,应用PASS可以提升设备上的视频感知性能,包括处理加速、内存减少、计算节省、模型质量、预测稳定性和环境适应性。PASS可以推广到商品边缘设备上的实时视频流,例如NVIDIA Jetson Nano,在现实部署中以高效的性能。 总之,TinyML是一种新兴技术,为启用边缘智能铺平了最后一里路,它消除了传统云计算的局限,其中需要大量的计算能力和内存。构建一个高效的TinyML系统需要打破有限资源的约束并减轻计算开销。因此,本论文提出了TinyML系统实现的软硬件协同。在商业边缘设备上的广泛评估显示了我们提出的系统相比现有解决方案的显著性能改进。




