

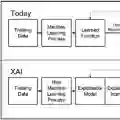
人工智能领域最近见证了显著的增长,导致开发了在各种领域表现出色的复杂深度学习模型。然而,这些发展带来了关键问题。深度学习模型容易继承并可能加剧其训练数据中存在的偏见。此外,这些模型的复杂性导致缺乏透明度,这可能导致偏见未被发现。这最终可能阻碍这些模型的采用,因为缺乏信任。因此,培养本质上透明、可信和公平的人工智能系统至关重要。本论文通过探索深度学习的可解释性和自解释模型,为这一研究领域做出了贡献。这些模型代表了向更透明系统的转变,提供了与模型架构密切相关的解释,揭示了它们的决策过程。因此,这种固有的透明性增强了我们的理解,从而提供了解决无意中学习偏见的机制。为了推进自解释模型的发展,本论文进行了对当前方法的全面分析。它引入了一个旨在提高某个最先进模型解释质量的新算法。此外,这项工作还提出了一种新的自解释模型,通过学习的解码器生成解释,促进端到端训练,并解决了解释性和性能之间普遍存在的权衡问题。此外,为了增强这些模型的可及性和可持续性,本论文还介绍了一种通用方法,无需重新训练即可将任何预训练的黑盒模型转化为自解释模型。通过所提出的方法,这项研究识别并抵制了从数据中学习的人为因素—虚假相关性,进一步强调了透明模型的需求。此外,本论文的范围还扩展到了大型语言模型的公平性维度,展示了这些模型加强社会偏见的倾向。这项研究的结果凸显了所提方法的有效性,从而为创建不仅准确而且透明、公平和可靠的人工智能系统铺平了道路,以促进人工智能技术的广泛采用和信任。

成为VIP会员查看完整内容
相关内容

Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日