基于编辑方法的文本生成(上)
声明:本文转载自 哈工大讯飞联合实验室 公众号
本期导读:近年来,序列到序列(seq2seq)方法成为许多文本生成任务的主流思路,在机器翻译、文本摘要等绝大多数生成任务上都得到了广泛的应用。与此同时,一些研究人员另辟蹊径,跳脱出传统的seq2seq方法,探索如何将 编辑方法(edit-based approach) 应用于一些文本生成任务,从而提升模型在生成任务上的表现。本期结合Google Research的三篇工作,对基于编辑方法的文本生成技术进行介绍。
•••
1. 引言
在文本生成任务中引入编辑方法的 motivation 主要有两方面:
首先,基于Transformer结构的seq2seq模型在当前各项文本生成任务上得到了广泛使用。而这类传统seq2seq模型的不足主要有以下几点:
(1)数据效率: 为使模型在文本生成任务上获得较好的表现,传统seq2seq模型通常需要在大量数据上进行训练,时间长,计算量庞大。
(2)推理时间: 传统seq2seq模型在解码时主要采用自回归的方式。这种方式按顺序从左至右一个词一个词地预测输出,虽然遵循了人类语言的单向顺序性,但大大增加了模型的推理时间。
(3)可控性与可解释性: 传统seq2seq模型在输出时会发生一些错误。例如,产生输入文本中并不支持的输出(hallucination)。此外,模型在输出时的可解释性也较差。
其次,以句子融合、语法纠错等为代表的一些文本生成任务均具有 “重合”(overlap) 的特点,即源文本和目标文本在语言上重复性较大,只需要对源文本做微小的改动就能生成目标文本(图1)。因此从头训练一个seq2seq模型然后自回归地预测输出就显得较为浪费。基于此,复制机制(copy mechanism)的引入使得模型能够对当前输出是复制原词还是生成新词进行选择。但即使模型使用了复制机制,仍需要较大规模的训练数据来满足解码时的词汇量需求,从而保证模型性能。
综上,在文本生成任务中引入文本编辑的方法,意在针对一些生成任务中的overlap特点,合理利用源文本与目标文本的相似部分,改善传统seq2seq模型的不足。这种方法直观上保留了从源文本到目标文本的编辑过程(如哪些词保留,哪些词需要删除等),与人类实际处理这类生成任务的思路不谋而合,从而也带来了较好的可解释性。

图 1 基于编辑的文本生成示例。由于文本间的overlap,从源文本生成目标文本只需做轻微改动。
2. LaserTagger
LaserTagger是Google Research在 “Encode, Tag, Realize: High-Precision Text Editing” 一文中提出的文本生成模型,该论文发表于EMNLP 2019。
这篇工作的主要贡献有:
(1)将序列标注作为源文本到目标文本的跳板,即首先对源文本标注编辑操作标签,再根据标注得到的标签序列将源文本并行转化为目标文本(图2)。
(2)基于(1)的思路,设计了基于编辑操作的文本生成模型LaserTagger(包括LaserTaggerFF和LaserTaggerAR两种模型变体),并且在四种文本生成任务上进行了对比实验,获得了较好的效果。

图 2 LaserTagger主要思路
2.1 主要方法
-
标注操作定义
本文定义文本编辑操作标签由两部分构成:基本标签B和附加标签P,表示为 。
基本标签分为两种:保留( )或删除( ),指对当前位置的token进行保留还是删除操作。
附加标签 指需要在当前位置插入新短语 (可以是单个词、多个词或标点等,也可以为空)。
在构造编辑标签序列时,由匹配算法(见图4)从训练语料构造出的phrase vocabulary 中选出合适的短语 插入。因此,若词典 的大小为 ,则编辑标签的总规模则约为 。
此外,可以根据不同的下游任务定义一些特殊标签。例如在句子融合任务中有时需要交换输入句子的语序,此时可以设置标签SWAP代表交换语序操作(图3)。

图 3 句子融合任务标注操作示例。除了保留和删除操作外,还需要交换两个句子的语序(SWAP)以及在某些位置插入标点逗号(commaDELETE)。
-
构造phrase vocabulary
在构造训练数据对应的编辑标签序列时,若词典 无法提供可插入的新短语 ,则该条训练数据会被筛掉。因此理想的词典 应满足以下两点:一方面,词典规模 应尽可能的小;另一方面,该词典应能够尽可能的覆盖更多的训练数据。
构造词典 的步骤为:
(1) 将源文本和目标文本对齐,计算出它们的最长公共子序列(longest common subsequence, LCS)。
(2) 将目标文本中不属于LCS的n-grams加入词典 中。
(3) 最终保留出现频率最高的 个phrases。
在实验中发现,词典 保留频率最高的500个phrases已能覆盖85%的训练样本,且再继续增大词典规模对LaserTagger的性能帮助很小。因此,在本文的各主要实验中,词典 的大小均被设置为500。 -
构造编辑标签序列
在定义好标签、构造完词典 之后,就可以根据训练语料中的源文本和目标文本构造出对应编辑标签序列,进行有监督学习。
构造编辑标签序列的算法如图4中伪代码所示。该算法主要采用贪心匹配的思想,通过设置两个指针(is与it)对源文本和目标文本进行遍历,进而构造出标签序列。值得注意的是伪代码中并未给出PDELETE标签如何生成。笔者猜测可能是由于PDELETE标签与PKEEP标签实际上可以相互替代(如图5所示),在实验中二者使用一个即可。


2.2 模型概述
本文设计的LaserTagger有两种变体:LaserTaggerFF与LaserTaggerAR。前者Decoder部分采用前馈网络(feed forward network),推理速度更快;后者Decoder部分采用的是1层Transformer Decoder,推理效果更好。两种变体Encoder部分均与BERT-base结构相同,为12层Transformer Encoder。
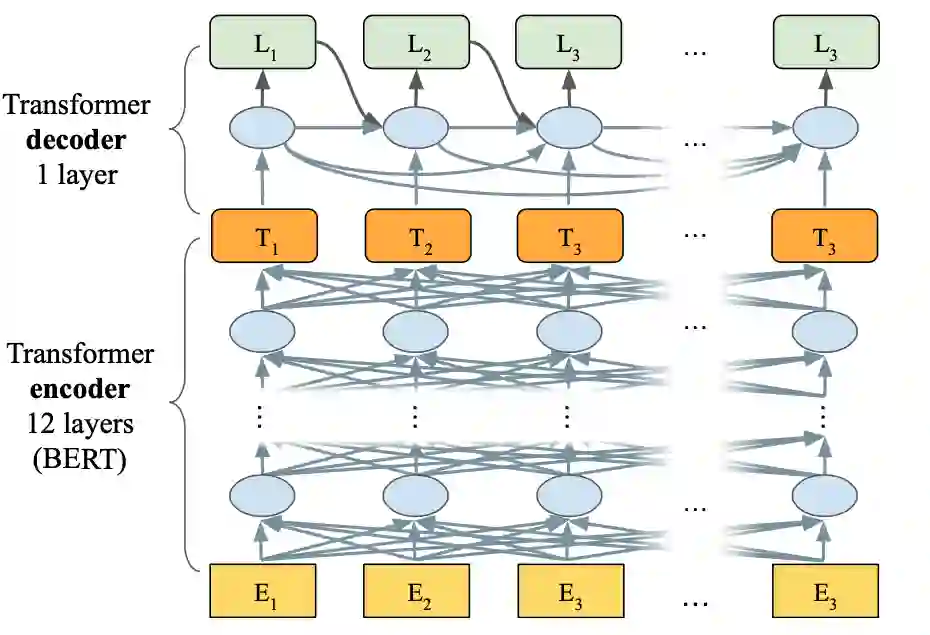
图 6 LaserTaggerAR主要结构
3. Seq2Edits
Seq2Edits是Google Research在 “Seq2Edits: Sequence Transduction Using Span-level Edit Operations” 一文中提出的文本生成模型,该论文发表于EMNLP 2020。
本篇工作的主要改进有:
(1)与LaserTagger不同,Seq2Edits是在span-level上进行标签标注。即,LaserTagger对每一个词(token)标注一个编辑标签,而Seq2Edits对一个或多个词(span)标注一个编辑标签。
论文作者认为在span-level上进行标注操作能够更好地对局部依赖(local dependencies)进行建模,而对于语法纠错等生成任务而言,人类实际解决这类问题时的主要根据也是span与span间的局部依赖,因此在span-level上进行标注操作也与人类实际解决问题时的思路相吻合。
(2)Seq2Edits将标注操作进一步细化,每一个span对应的编辑标签都由一个三元组组成,相比LaserTagger的标签定义方式粒度更细,因此可解释性也更好。
(3)推理时间不再取决于目标文本的长度,而是依赖于编辑操作的规模。推理速度相比传统seq2seq模型仍得到大幅提升。
3.1 主要方法
-
标注操作定义
Seq2Edits的标注操作与LaserTagger主要有两点不同:(1)Seq2Edits是在span-level上打标签;(2)Seq2Edits的编辑标签被定义为三元组的形式。图 7 Seq2Edits语法纠错任务生成示例
如图7所示,编辑标签被定义为一个三元组 ,其中 代表编辑操作类型(例如修改标点 ,修改动词形式 等), 代表编辑操作的结束位置(默认当前操作的开始位置为上一个标签的结束位置), 为替换短语(保留原文为 )。 生成任务表示
设源文本为序列 ,长度为 ;目标文本为序列 ,长度为 。
则传统seq2seq思路下文本生成任务可表示为:
使用本文方法,则任务可表示为:
以图7中句子为例,若源文本、目标文本分别为:
则编辑标签序列为:
从源文本到目标文本的过程则可表示为:
从本文对生成任务的概率表示中可以看出,在每一个 上,标签三元组中 相互并不是条件独立的,而是有着一定的依赖关系,即:
因此,模型在预测标签三元组时存在着先后顺序:在第 个 上,先预测 ,然后预测 ,最后预测 。

3.2 模型概述
在理解Seq2Edits生成文本的概率表示后就不难理解其模型结构。Seq2Edits沿用了标准的Transformer Encoder-Decoder结构,将Decoder分为A和B两部分来分别预测标签 、 和 。Decoder A和Decoder B之间使用残差连接(residual connections)。
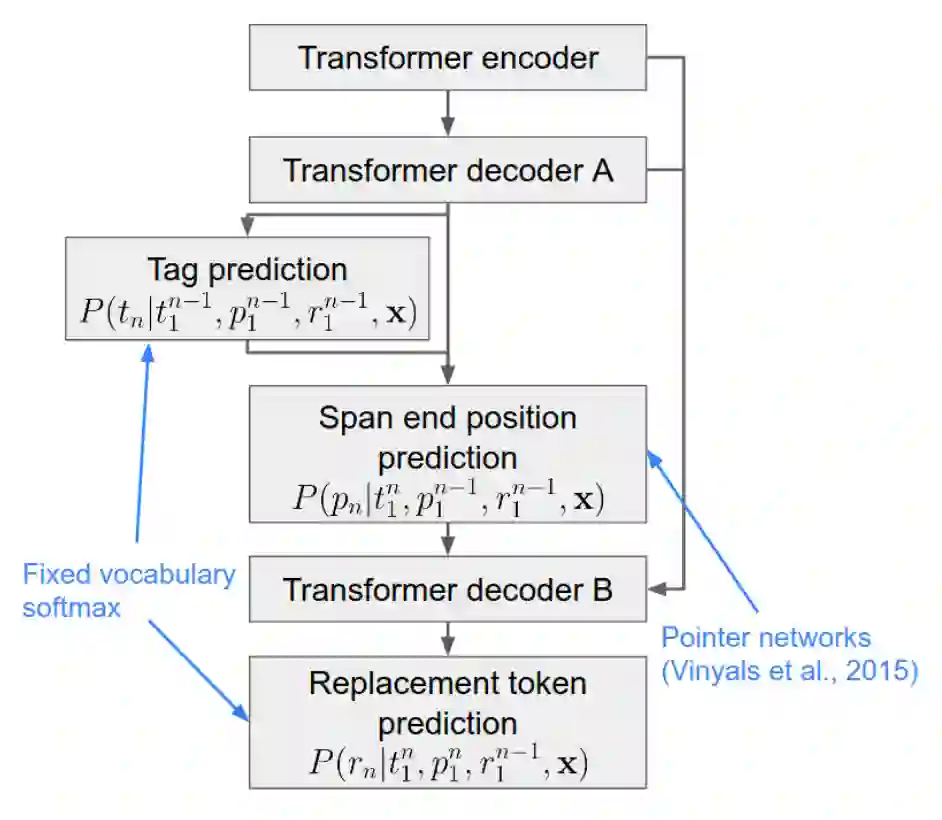
图 8 Seq2Edits主要结构
对于位置标签 的预测基于pointer-network,使用了类似Transformer中attention的机制,即:其中 (queries)来自历史 的decoder states, (keys)和 (values)来自当前 的encoder states。
本期介绍了Google Research的LaserTagger和Seq2Edits两篇工作,下一期将继续介绍Google的第三篇工作FELIX以及三篇工作的实验评价部分和总结,敬请关注。
原文:吴珂






