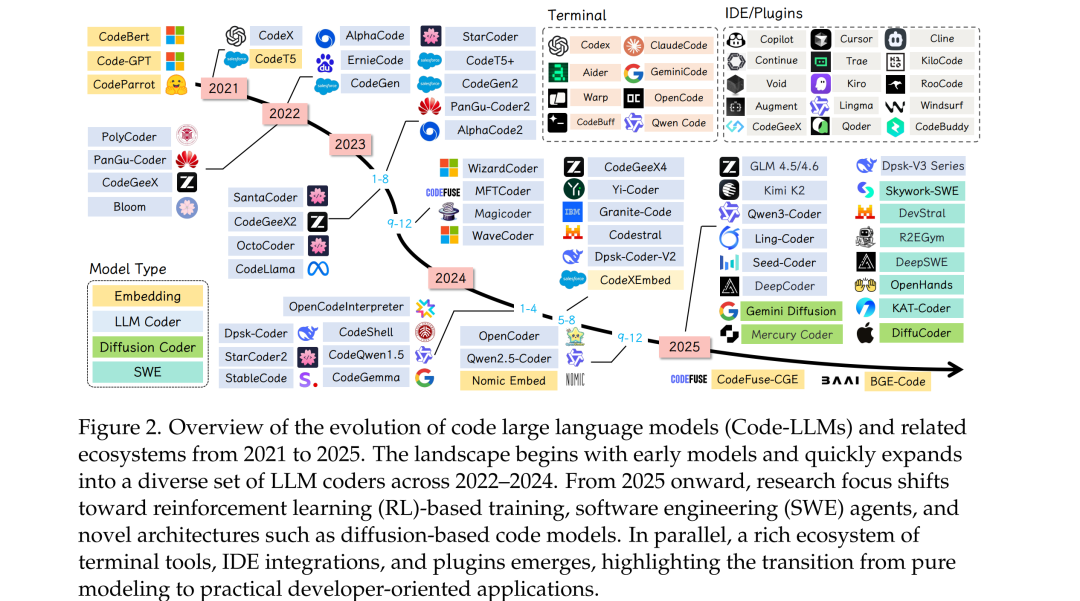
大型语言模型(Large Language Models,LLMs)通过实现从自然语言描述到可执行代码的直接转换,从根本上重塑了自动化软件开发范式,并推动了包括 GitHub Copilot(Microsoft)、Cursor(Anysphere)、Trae(字节跳动)以及 Claude Code(Anthropic)等工具的商业化落地。尽管该领域已从早期的基于规则的方法演进至以 Transformer 为核心的架构,但其性能提升依然十分显著:在 HumanEval 等基准测试上的成功率已从个位数提升至 95% 以上。 在本文中,我们围绕代码大模型(code LLMs)提供了一份全面的综合综述与实践指南,并通过一系列分析性与探测性实验,系统性地考察了模型从数据构建到后训练阶段的完整生命周期。具体而言,我们涵盖了数据整理、高级提示范式、代码预训练、监督微调、强化学习,以及自主编码智能体等关键环节。 我们系统分析了通用大语言模型(如 GPT-4、Claude、LLaMA)与代码专用大语言模型(如 StarCoder、Code LLaMA、DeepSeek-Coder 和 QwenCoder)的代码能力,并对其所采用的技术手段、设计决策及相应权衡进行了深入评估。 进一步地,本文明确指出了学术研究与实际部署之间的研究—实践鸿沟:一方面,学术研究通常聚焦于基准测试与标准化任务;另一方面,真实世界的软件开发场景则更加关注代码正确性、安全性、大规模代码库的上下文感知能力,以及与现有开发流程的深度集成。基于此,我们系统梳理了具有应用潜力的研究方向,并将其映射到实际工程需求之中。 最后,我们通过一系列实验,对代码预训练、监督微调与强化学习进行了全面分析,涵盖尺度定律(scaling law)、训练框架选择、超参数敏感性、模型结构设计以及数据集对比等多个关键维度。
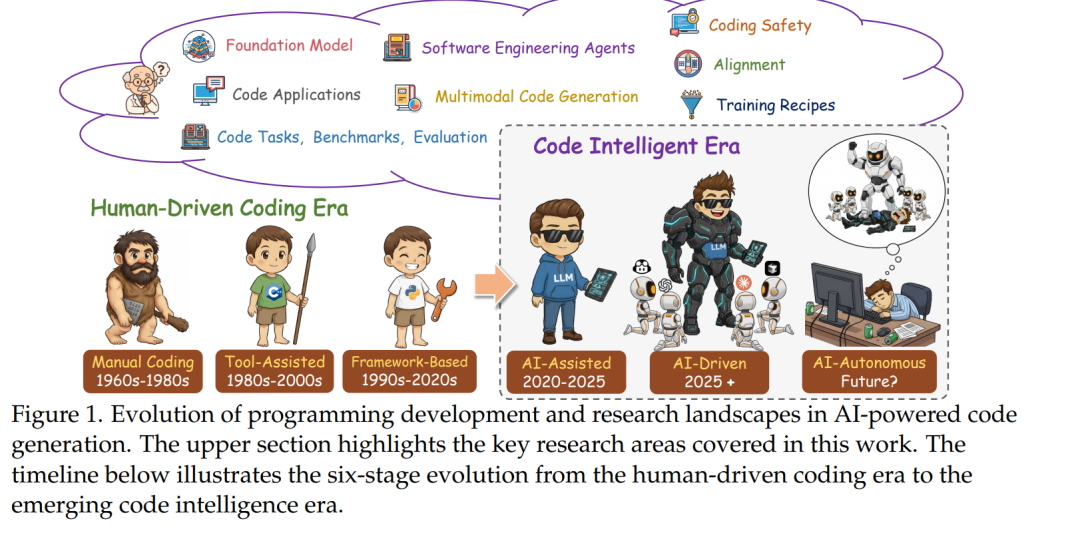
1 引言
大型语言模型(Large Language Models,LLMs)[66, 67, 192, 424, 435, 750, 753, 755, 756] 的出现引发了自动化软件开发领域的范式转变,从根本上重塑了人类意图与可执行代码之间的关系 [1306]。现代 LLM 在多种代码相关任务中展现出卓越能力,包括代码补全 [98]、代码翻译 [1158]、代码修复 [619, 970] 以及代码生成 [139, 161]。这些模型有效地将多年积累的编程经验提炼为可遵循指令的通用工具,使不同技能水平的开发者都能够基于 GitHub、Stack Overflow 及其他代码相关网站中的数据进行使用和部署。 在众多 LLM 相关任务中,代码生成无疑是最具变革性的方向之一。它使自然语言描述能够直接转化为可运行的源代码,从而消解了领域知识与技术实现之间的传统壁垒。这一能力已不再局限于学术研究,而是通过一系列商业化与开源工具成为现实,包括:(1) GitHub Copilot(Microsoft)[321],在集成开发环境中提供智能代码补全;(2) Cursor(Anysphere)[68],一款支持对话式编程的 AI 原生代码编辑器;(3) CodeGeeX(智谱 AI)[24],支持多语言代码生成;(4) CodeWhisperer(Amazon)[50],与 AWS 服务深度集成;以及 (5) Claude Code(Anthropic)[194] / Gemini CLI(Google)[335],二者均为命令行工具,允许开发者直接在终端中将编码任务委托给 Claude 或 Gemini [67, 955],以支持智能体化(agentic)的编码工作流。这些应用正在重塑软件开发流程,挑战关于编程生产力的传统认知,并重新界定人类创造力与机器辅助之间的边界。 如图 1 所示,代码生成技术的演进轨迹揭示了一条清晰的技术成熟与范式变迁路径。早期方法受限于启发式规则和基于概率文法的框架 [42, 203, 451],在本质上较为脆弱,仅适用于狭窄领域,且难以泛化到多样化的编程场景。Transformer 架构的出现 [291, 361] 并非简单的性能提升,而是对问题空间的根本性重构:通过注意力机制 [997] 与大规模训练,这类模型能够捕获自然语言意图与代码结构之间的复杂关联。更为引人注目的是,这些模型展现出了涌现式的指令遵循能力,这一能力并非显式编程或直接优化的目标,而更像是规模化学习丰富表征的自然结果。这种通过自然语言使非专业用户也能生成复杂程序的“编程民主化”趋势 [138, 864],对 21 世纪的劳动力结构、创新速度以及计算素养的本质产生了深远影响 [223, 904]。 当前代码 LLM 的研究与应用格局呈现出一种通用模型与专用模型并行发展的双轨结构,二者各具优势与权衡。通用大模型,如 GPT 系列 [747, 750, 753]、Claude 系列 [66, 67, 192] 以及 LLaMA 系列 [690, 691, 979, 980],依托包含自然语言与代码在内的超大规模语料,具备对上下文、意图及领域知识的深度理解能力。相较之下,代码专用大模型(如 StarCoder [563]、Code LLaMA [859]、DeepSeek-Coder [232]、CodeGemma [1295] 和 QwenCoder [435, 825])则通过在编程导向数据上的聚焦式预训练与任务特定的架构优化,在代码基准测试中取得了更优性能。诸如 HumanEval [161] 等标准化基准上从个位数到 95% 以上成功率的跃迁,既体现了算法层面的创新,也反映了对代码与自然语言在组合语义与上下文依赖方面共性的更深刻理解。 尽管相关研究与商业应用发展迅速,现有文献中仍然存在创新广度与系统性分析深度之间的显著鸿沟。现有综述多采取全景式视角,对代码相关任务进行宽泛分类,或聚焦于早期模型阶段,未能对最新进展形成系统整合。尤其值得注意的是,最先进系统所采用的数据构建与筛选策略仍缺乏深入探讨——这些策略在数据规模与数据质量之间进行权衡,并通过指令微调方法使模型行为与开发者意图对齐。相关对齐技术包括引入人类反馈以优化输出、高级提示范式(如思维链推理与小样本学习)、具备多步问题分解能力的自主编码智能体、基于检索增强生成(Retrieval-Augmented Generation, RAG)的事实约束方法,以及超越简单二值正确性、从代码质量、效率与可维护性角度进行评估的新型评价框架。 如图 2 所示,Kimi-K2 [957]、GLM-4.5/4.6 [25, 1248]、Qwen3Coder [825]、Kimi-Dev [1204]、Claude [67]、DeepSeek-V3.2-Exp [234] 以及 GPT-5 [753] 等最新模型集中体现了上述创新方向,但其研究成果分散于不同文献之中,尚缺乏统一、系统的整合。表 1 对多篇与代码智能或 LLM 相关的综述工作进行了比较,从八个维度进行评估:研究领域、是否聚焦代码、是否使用 LLM、是否涉及预训练、监督微调(SFT)、强化学习(RL)、代码 LLM 的训练配方,以及应用场景。这些综述覆盖了通用代码生成、生成式 AI 驱动的软件工程、代码摘要以及基于 LLM 的智能体等多个方向。尽管多数工作关注代码与应用层面,但在技术细节覆盖上差异显著,尤其是强化学习方法在现有综述中鲜有系统讨论。 为此,本文对面向代码智能的大语言模型研究进行了全面而前沿的系统综述,对模型的完整生命周期展开分析,涵盖从初始数据构建、指令调优到高级代码应用与自主编码智能体开发等关键阶段。 为了从代码基础模型出发,系统性地覆盖智能体与应用层面,本文进一步提供了一份贯通理论基础与工程实现的详细实践指南(见表 1)。本文的主要贡献包括: 1. 提出统一的代码 LLM 分类体系,系统梳理其从早期 Transformer 模型到具备涌现式推理能力的指令调优模型的发展脉络; 1. 系统分析从数据构建与预处理、预训练目标与架构创新,到监督指令微调与强化学习等高级微调方法的完整技术流水线; 1. 深入探讨定义当前最优性能的前沿范式,包括提示工程技术(如思维链推理 [1174])、检索增强生成方法,以及能够执行复杂多步问题求解的自主编码智能体; 1. 批判性评估现有基准与评测方法,讨论其优势与局限,并重点分析从功能正确性扩展到代码质量、可维护性与效率评估所面临的挑战; 1. 综合分析最新突破性模型(如 GPT-5、Claude 4.5 等),提炼新兴趋势与开放问题,为下一代代码生成系统的发展提供方向; 1. 通过大规模实验,从尺度定律、训练框架、超参数、模型架构与数据集等多个维度,对代码预训练、监督微调与强化学习进行系统性分析。