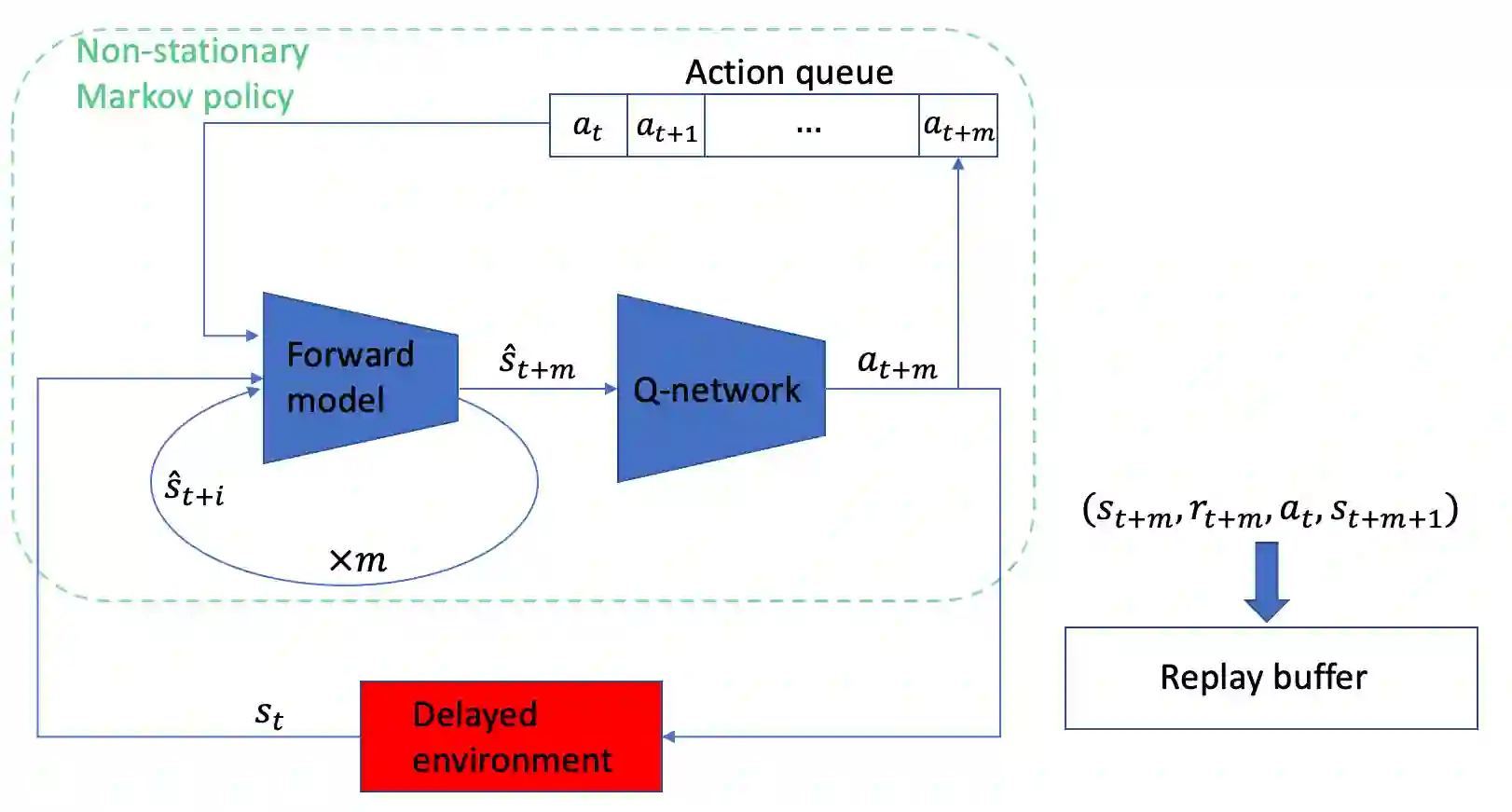
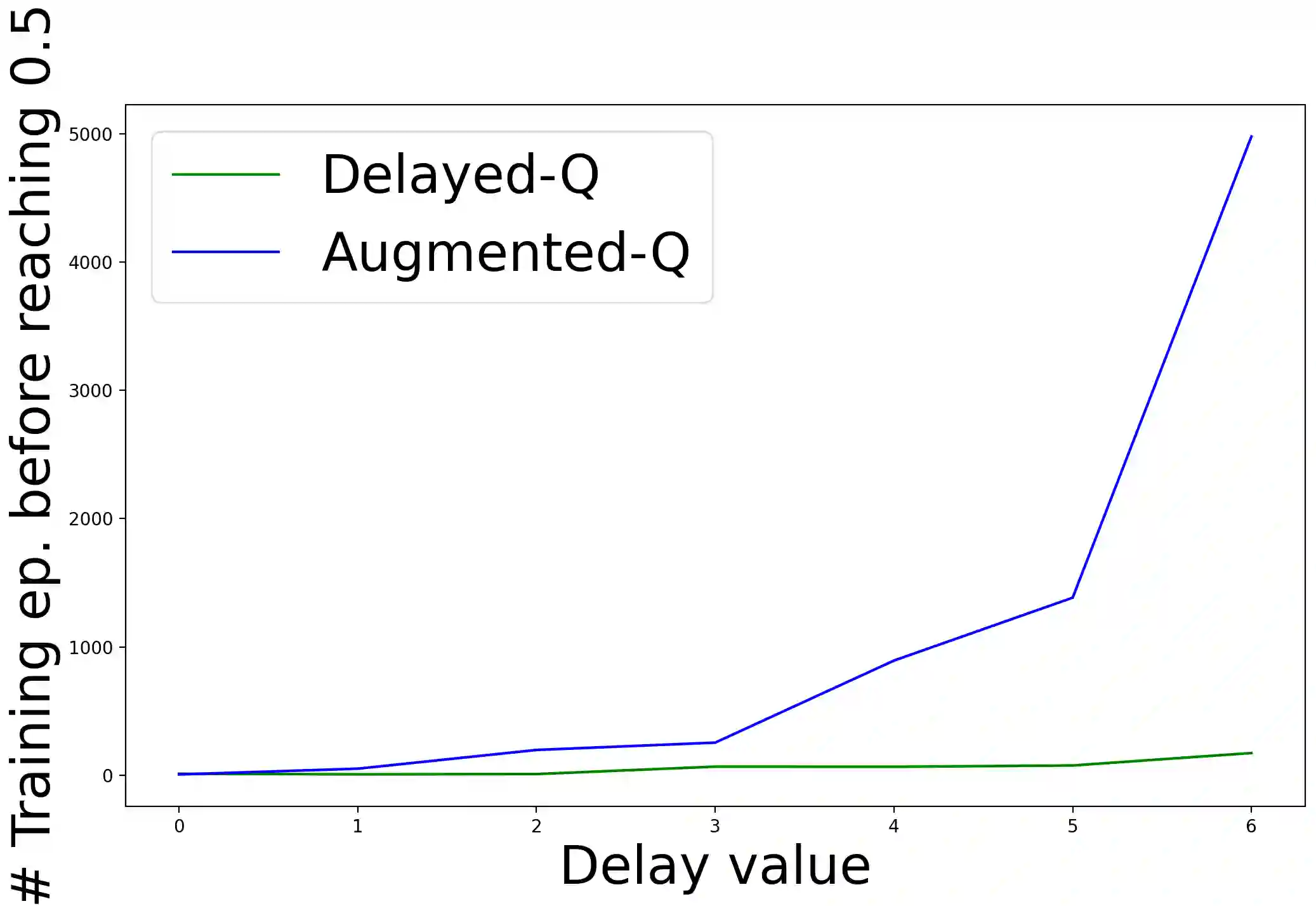
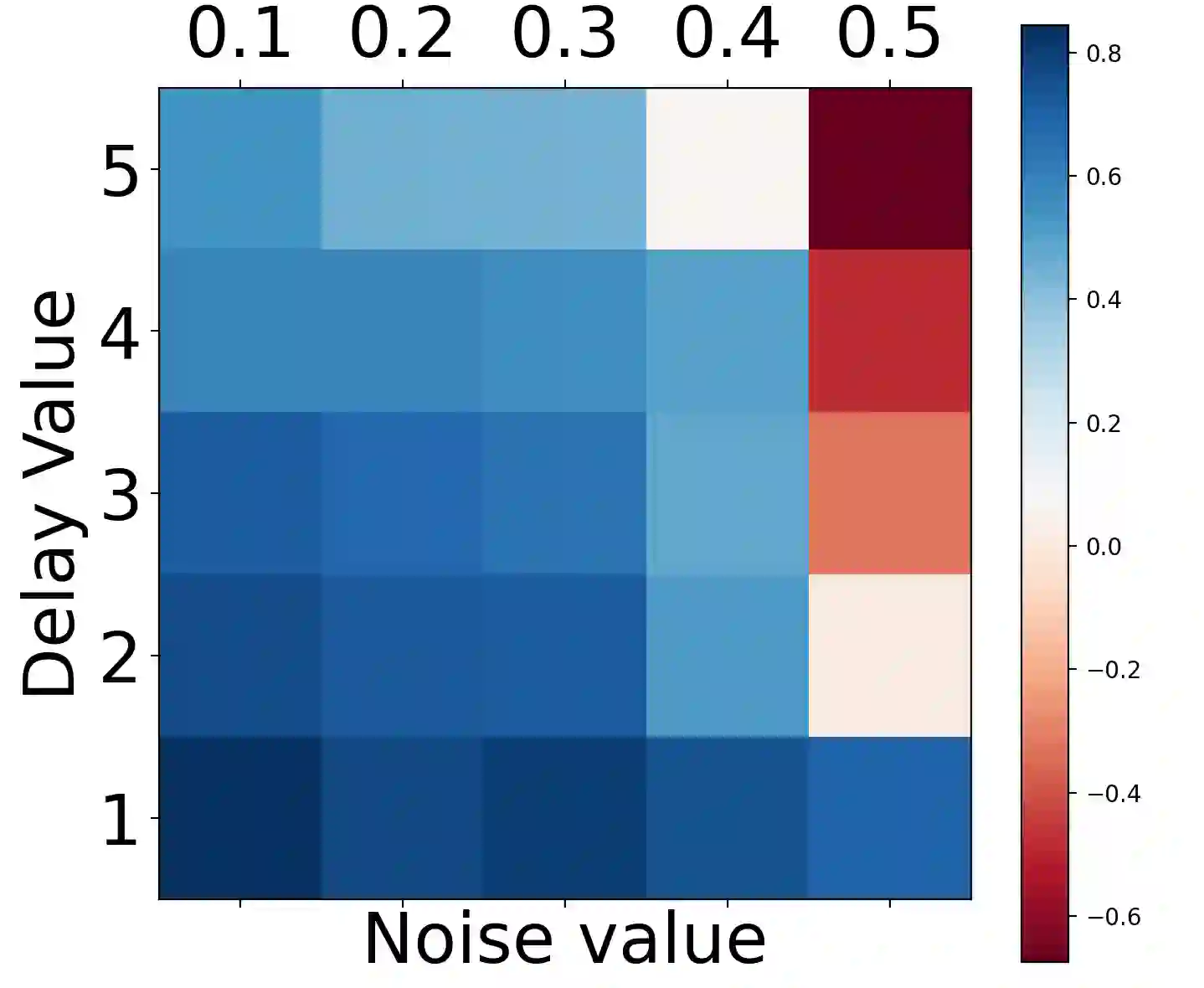
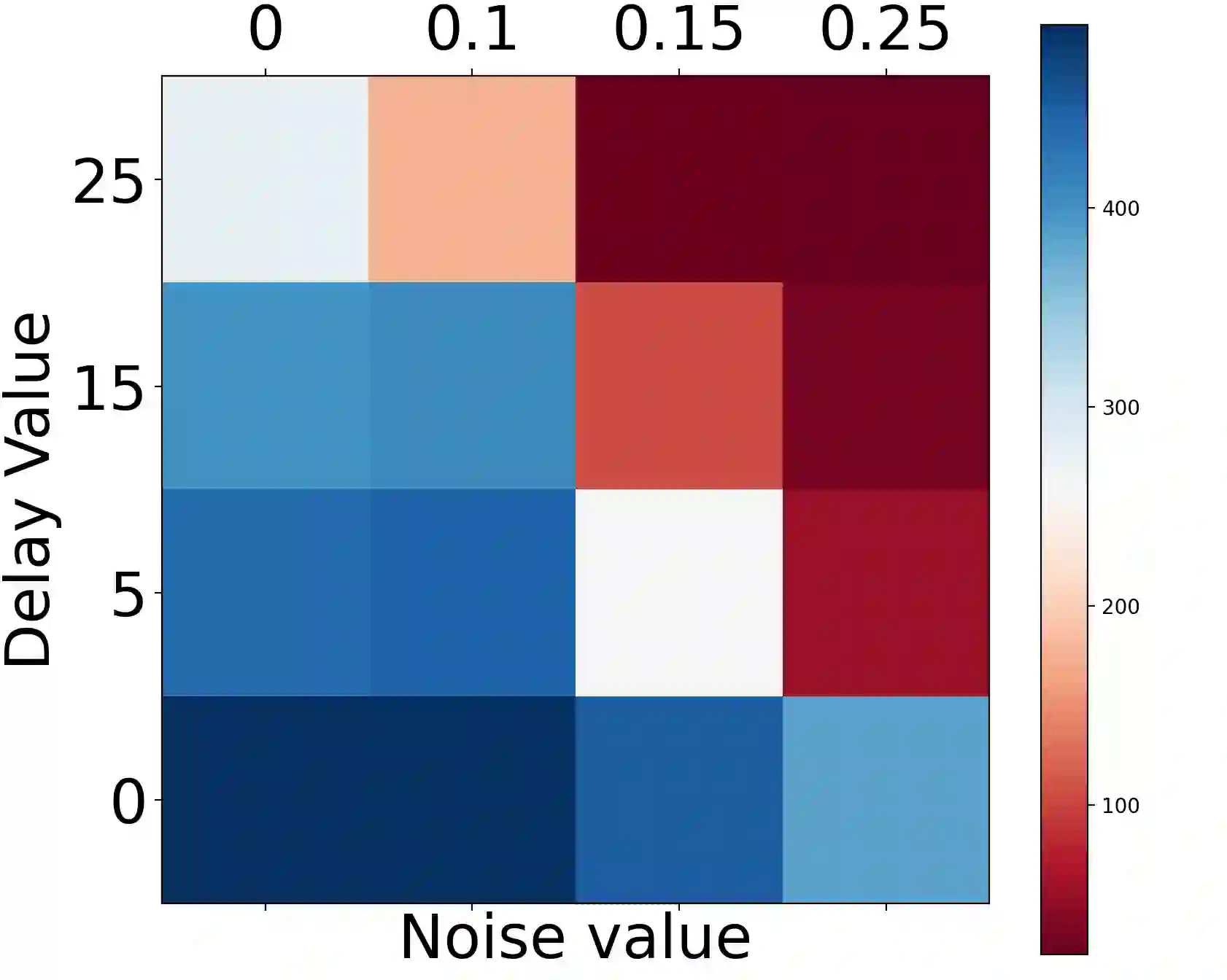
The standard Markov Decision Process (MDP) formulation hinges on the assumption that an action is executed immediately after it was chosen. However, assuming it is often unrealistic and can lead to catastrophic failures in applications such as robotic manipulation, cloud computing, and finance. We introduce a framework for learning and planning in MDPs where the decision-maker commits actions that are executed with a delay of $m$ steps. The brute-force state augmentation baseline where the state is concatenated to the last $m$ committed actions suffers from an exponential complexity in $m$, as we show for policy iteration. We then prove that with execution delay, Markov policies in the original state-space are sufficient for attaining maximal reward, but need to be non-stationary. As for stationary Markov policies, we show they are sub-optimal in general. Consequently, we devise a non-stationary Q-learning style model-based algorithm that solves delayed execution tasks without resorting to state-augmentation. Experiments on tabular, physical, and Atari domains reveal that it converges quickly to high performance even for substantial delays, while standard approaches that either ignore the delay or rely on state-augmentation struggle or fail due to divergence. The code is available at https://github.com/galdl/rl_delay_basic.git.
翻译:标准 Markov 决策程序(MDP) 的制定取决于以下假设: 行动是在选择后立即执行的。 然而, 假设它往往不切实际, 并可能导致机器人操纵、云计算和金融等应用方面的灾难性失败。 我们引入了MDP的学习和规划框架, 决策者在MDP中采取拖延执行的行动, 拖延了 $ $ 的步骤。 因此, 我们设计了一个非静止的Q- 学习风格模型算法, 在不采用州- 降级的情况下解决延迟执行任务。 我们在表格、 物理和 Atari 域进行的实验表明, 执行延迟后, Markov 最初的州- 空间政策就足以获得最高奖赏, 但也需要非静态化。 至于固定的 Markov 政策, 我们显示它们是一般的次优化。 因此, 我们设计了一个非静止的 Q- 学习风格模型算法, 不使用州- 解决延迟执行任务, 而不用州- 降级 。 在表格、 物理 和 Atari 域的实验显示, 它很快会达到高绩效, 即使是重大拖延, 。 而标准/ balbligal- disgismalation 。