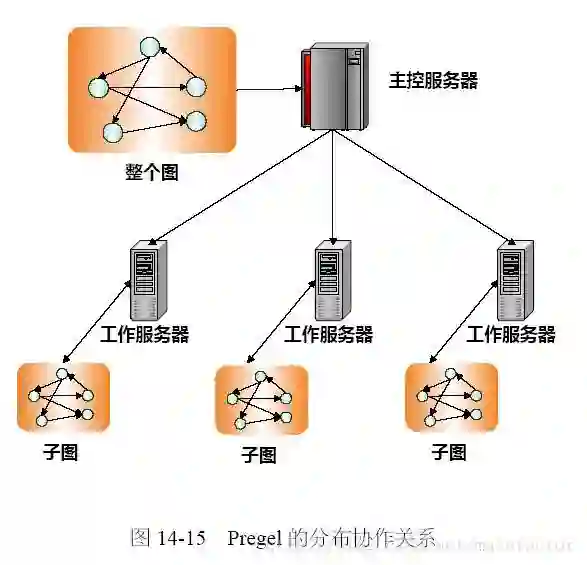
We present ASYMP, a distributed graph processing system developed for the timely analysis of graphs with trillions of edges. ASYMP has several distinguishing features including a robust fault tolerance mechanism, a lockless architecture which scales seamlessly to thousands of machines, and efficient data access patterns to reduce per-machine overhead. ASYMP is used to analyze the largest graphs at Google, and the graphs we consider in our empirical evaluation here are, to the best of our knowledge, the largest considered in the literature. Our experimental results show that compared to previous graph processing frameworks at Google, ASYMP can scale to larger graphs, operate on more crowded clusters, and complete real-world graph mining analytic tasks faster. First, we evaluate the speed of ASYMP, where we show that across a diverse selection of graphs, it runs Connected Component 3-50x faster than state of the art implementations in MapReduce and Pregel. Then we demonstrate the scalability and parallelism of this framework: first by showing that the running time increases linearly by increasing the size of the graphs (without changing the number of machines), and then by showing the gains in running time while increasing the number of machines. Finally, we demonstrate the fault-tolerance properties for the framework, showing that inducing 50% of our machines to fail increases the running time by only 41%.
翻译:我们展示了ASYMP(ASYMP),这是一个为及时分析具有数万亿边缘的图表而开发的分布式图表处理系统。ASYMP(ASYMP)具有几个显著的特征,包括一个强大的容积机制,一个无缝结构,一个无缝结构,无缝的无缝结构,以及有效的数据访问模式,以减少每台机器的间接费用。ASYMP(AsyMP)用来分析谷歌最大的图表,而我们在这里的经验评估中考虑的图表,在我们最了解的意义上,是文献中考虑最多的。我们的实验结果显示,与Google(Goog)以前的图表处理框架相比,ASYMP(ASYMP)可以缩放成更大的图表,在更拥挤的集群上操作,完成真实世界图解析任务。首先,我们评估了ASYMP(ASYMP)的速度,我们从不同选择的图表中显示,它连接的3-50x(3-50x)比在MapReddudududu和Pregel(Pregel)的艺术执行状况要快。然后我们展示这个框架的可缩缩缩缩缩和平行框架的大小。我们只能显示,最后显示50机器的失败。最后显示我们运行的磁力框架。